Application de méthodes statistiques et prédictives (PCA, clustering y PLS-DA) sur les données du vin pour connaître les facteurs qui influencent le plus lors de l'élaboration d'un bon vin.
Miquel Marín Colomé & Álvaro Mazcuñán Herreros
1 – DESCRIPTION DE L'ÉTUDE ET DE LA BASE DE DONNÉES
1.1 – DESCRIPTION DE L'ÉTUDE
Le travail suivant est lié à une base de données traitant de la variété de vin rouge et blanc du «Vinho Verde» portugais. La certification des vins comprend des tests physico-chimiques tels que, détermination de la densité, pH, quantité d'alcool, etc. Avec ce projet, vous souhaitez étudier les variables qui influencent le plus lors de l'analyse de la qualité d'un vin, Si c'est mauvais, bon / passable ou très bon.
1.2 – DESCRIPTION DE LA BASE DE DONNÉES
La base de données comprend 12 variables et 4858 observations. La plupart des variables sont des composants physico-chimiques utilisés pour faire des vins. Ces variables sont les suivantes:
- Acidité fixe
- Acidité volatile
- Acide citrique
- Sucre résiduel
- Chlorures
- Dioxyde de soufre libre
- Dioxyde de soufre total
- Densité
- pH
- Les sulfates
- De l'alcool
Ces variables mentionnées ci-dessus sont continues. Une part, une «cible» ou une variable de réponse est disponible. Cette variable correspond à la note du vin et est de type discret. Prenez les valeurs de 0 une 10.
2 – ANALYSE INITIALE EXPLORATOIRE ET PRÉ-TRAITÉE DES DONNÉES
2.1 – DONNÉES MANQUANTES
Premier, tout d'abord, il recherche s'il manque des valeurs dans le fichier de données. Il est vérifié à l'aide de la fonction suivante et on constate qu'il n'y a pas de valeur de ce type.
## [1] 0
2.2 – TRANSFORMATION DES VARIABLES
L'une des transformations qui ont été effectuées a été celle de la qualité variable du vin. Comme vous pouvez le voir, il y a peu de valeurs de ces observations qu'ils prennent comme évaluation 3, 4, 8 le 9.
## 3 4 5 6 7 8 9
## 20 163 1447 2178 870 175 5
Pour lui, Il a été décidé de regrouper les valeurs que prend cette variable en 3 groupes distincts:
- Groupe 1: Vins d'une valeur de 3 le 4. Ils seront considérés comme de «mauvais» vins
- Groupe 2: Vins avec une valorisation entre 5 et 7. Ils seront considérés comme de «bons» vins
- Groupe 3: Vins d'une valeur de 8 le 9. Les "très bons" vins seront considérés
2.3 – VARIABLES ET / OU ENREGISTREMENTS REJETÉS
Une étude préalable de la base de données a été réalisée et il a été décidé de ne supprimer aucune des variables depuis, d'une part, ils sont tous importants et, pour autre, avoir seulement 12, la suppression de l'un d'eux pourrait entraîner une perte d'informations lors de la réalisation de l'étude.
2.4 – DISTRIBUTION DES VARIABLES
Ensuite, chacune des variables disponibles sera observée, étudier s'il existe, a priori, certaines données anormales ou extrêmes en eux.
Dans le Annexé 8.3: Analyse de distribution variable tout est expliqué plus en détail, analyser s'il y a normalité ou asymétrie dans les données, en plus du coefficient de Kurtosis.
A priori, aucune donnée anormale n'est observée. Comme seul détail, dans le graphique de densité, on peut voir que toutes les observations prennent des valeurs autour de 1.
Ce sont quelques-unes des valeurs de densité de certains vins.
- Vin blanc sec: 0,9880-0,9930 g / mL.
- Vin rouge sec: 0,9910-0,9950 g / mL.
- Vin mousseux: 0,9890-1,0080 g / mL.
- Vin de liqueur (Moscou): 1,0500-1,0700 g / mL.
Donc, c'est une valeur normale.
2.5 MISE À L'ÉCHELLE ET CENTRAGE DES DONNÉES
Après avoir effectué une petite analyse exploratoire des données de ce fichier, il est déjà passé à la partie du prétraitement, partie importante avant d'effectuer les analyses appropriées.
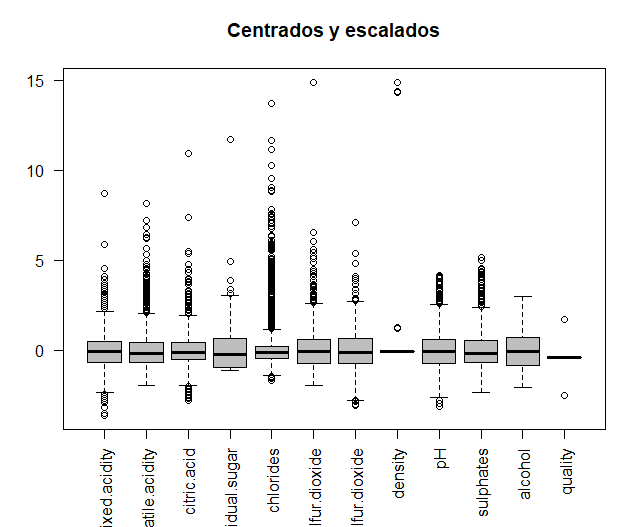
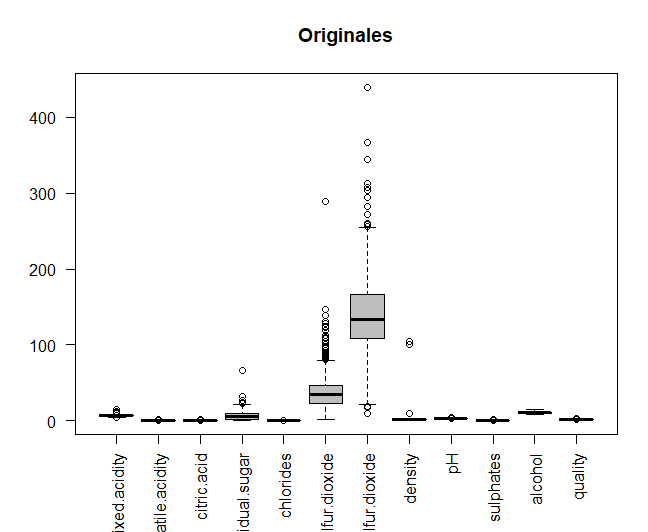
Les données d'origine seront comparées aux données une fois centrées et mises à l'échelle, afin de voir si les variables sont mesurées à différentes magnitudes. Les données sont centrées et mises à l'échelle.
Ensuite, les deux graphiques qui font la comparaison sont imprimés dans la même fenêtre, en utilisant la fonction de couple. On peut voir comment certaines des variables sont mesurées à différentes magnitudes, par exemple, les deux types de soufre. Pour lui, pour une analyse plus approfondie, des données centrées et mises à l'échelle seront utilisées.
3. UNE ANALYSE 1 – ANALYSE DES COMPOSANTS PRINCIPAUX (PCA)
Une fois l'analyse exploratoire effectuée et les données centrées et mises à l'échelle, vous pouvez accéder à la première des trois analyses qui seront réalisées dans ce projet du sujet. Le premier d'entre eux, comme le titre l'indique, est l'analyse des composants principaux. L'utilité de cette méthode est double:
- Rendu optimal dans un espace de petite dimension, observations d'un espace général p-dimensionnel. C’est la première étape pour identifier d’éventuelles variables «latentes» ou non observées, qui génèrent la variabilité des données.
- Permet de transformer les variables d'origine, généralement corrélé, dans de nouvelles variables non corrélées, faciliter l'interprétation des données.
3.1 OBJECTIFS
L'objectif lors de l'utilisation de cette technique sera d'obtenir les variables qui influencent le plus les dimensions qui expliquent la plus grande variabilité. En utilisant cette méthode, il sera possible d'obtenir une vue plus spécifique du comportement des données en cours de traitement. Une part, une petite étude sera menée sur certains vins qui ont des données extrêmes.
3.2 APPLICATION DE LA MÉTHODE / RÉSULTATS NUMÉRIQUES ET GRAPHIQUES
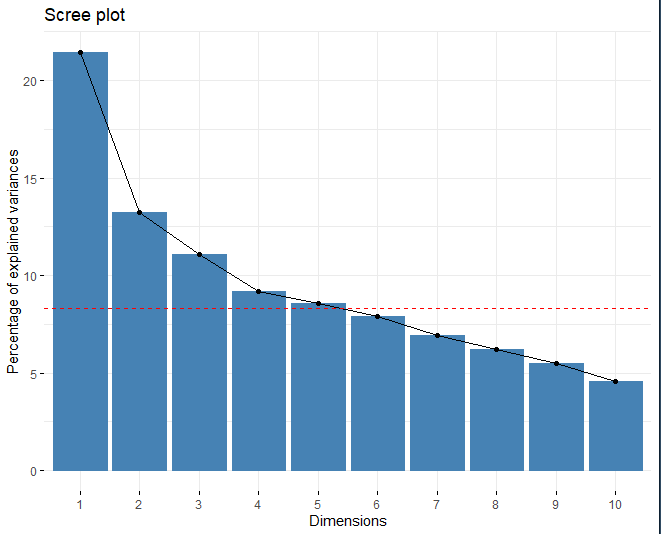
SCREE-PLOT
Elle est déjà passée à l'application de la méthode. Tout cela se fait grâce à la fonction PCA déjà implémentée dans R. Les données ne sont pas mises à l'échelle car cela a déjà été fait précédemment.
## valeur propre variance.pourcentage cumulatif.variance.percent
## Dim.1 2.571633 21.434687 21.43469
## Dim.2 1.585109 13.211958 34.64665
## Dim.3 1.330253 11.087723 45.73437
## Dim.4 1.102265 9.187435 54.92180
## Dim.5 1.029659 8.582255 63.50406
La méthode est appliquée et on observe comment le nombre idéal de composants principaux est 5. D'une part, en utilisant l'intrigue éboulis, la ligne rouge coupe dans la cinquième dimension. D'autre part, Une autre technique pour choisir le nombre approprié de dimensions consiste à obtenir les composantes qui ont une valeur propre supérieure à 1. Aussi, En obtenant un tableau avec ladite valeur propre correspondant à chacune des dimensions, on voit que, à partir du cinquième composant, la valeur propre est supérieure à 1.
SCORE-PLOT
Ensuite, un graphique de score est obtenu avec les scores des vins dans chacune des dimensions qui ont été obtenus précédemment. Ces vins sont colorés par leur apport dans les composants.
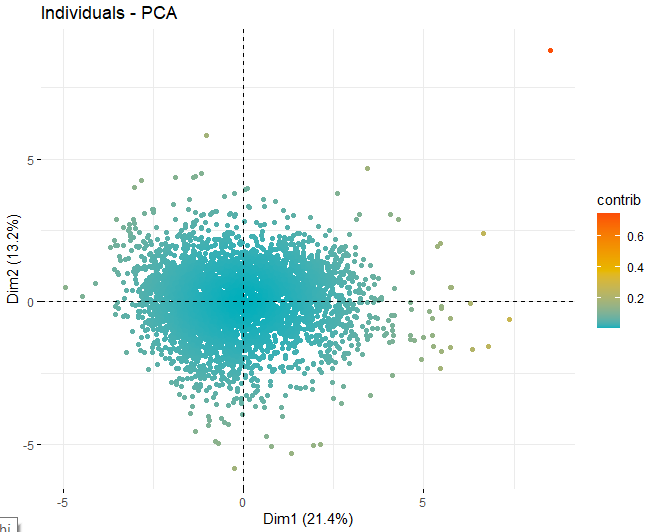
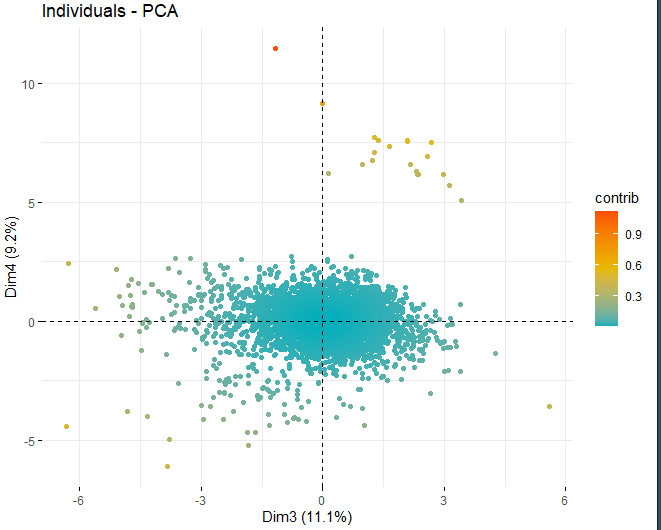
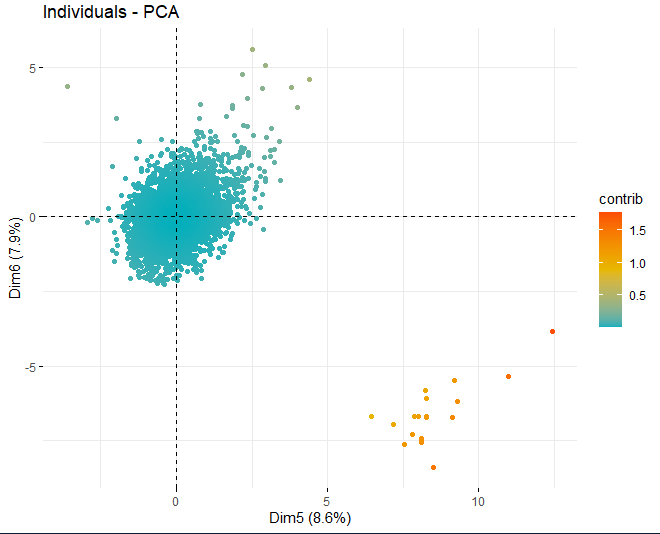
On peut voir comment il y a des valeurs anormales dans les différents composants, mis à part quelques observations extrêmes qui battent un score, en valeur absolue, plus grand que 5 et même de 10. Afin d'obtenir plus d'informations sur la nature de ces observations anormales, ils continuent à obtenir les mêmes graphiques de score qu'avant mais, dans ce cas, uniquement avec des observations qui dépassent un score, en valeur absolue, de 5.
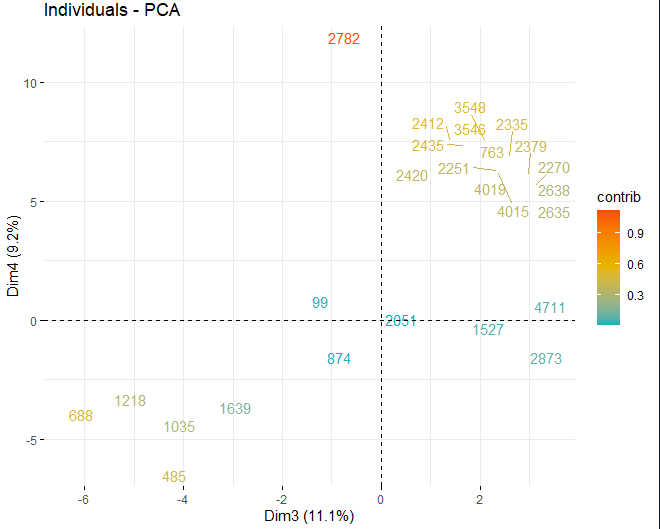
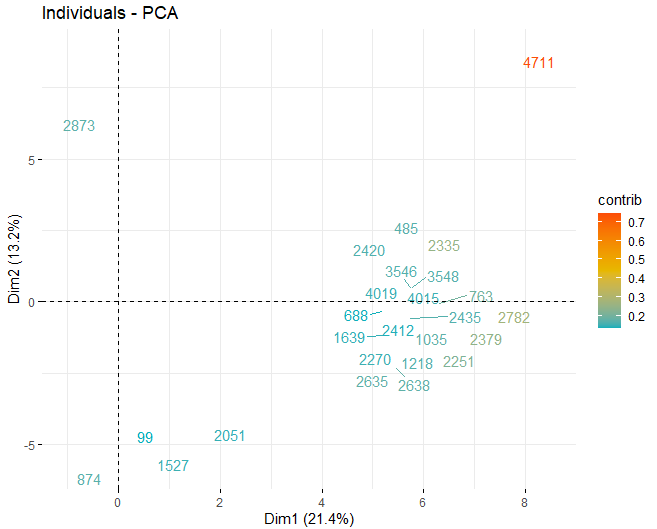
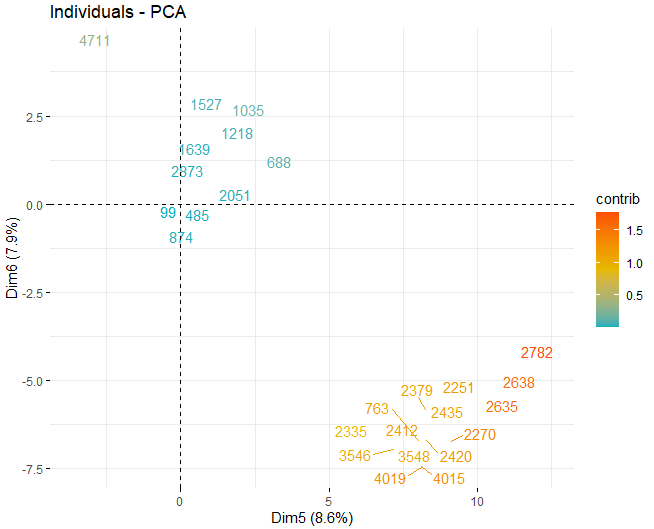
HOTELLING T2
Quelques observations, spécifiquement les vins 4711, 2782 le 2635, ils ont des valeurs très extrêmes qui, s'ils sont laissés dans la base de données, peut fausser les conclusions des analyses futures. Spécifique, Toute observation dépassant une limite de la 99% en utilisant le T2 de Hotelling.
Ensuite, vous pouvez voir certains des vins qui dépassent cette limite.
On observe qu'il existe, spécifique, un total de 156 observations qui dépassent le 99%. 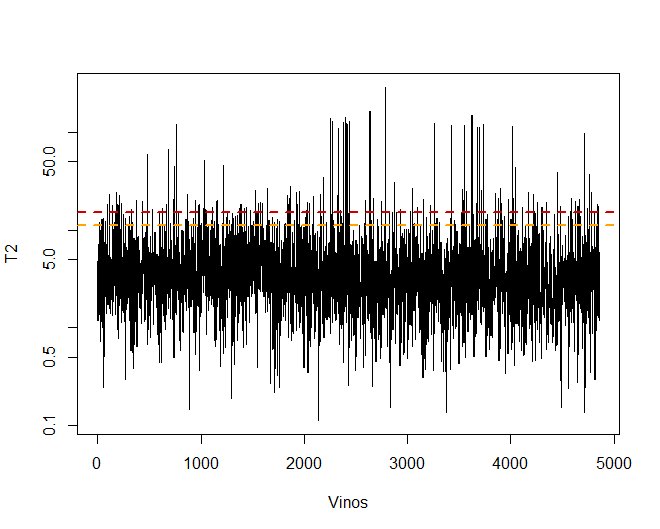
## [1] 156
Pour lui, pour une meilleure analyse, ces vins sont éliminés.
## [1] 4702 12
Ensuite, une variable auxiliaire est créée pour y stocker la variable de qualité, à utiliser dans l'analyse de coloration suivante.
Dans ce cas, observer l'axe «et» des boîtes à moustaches, suppression des valeurs précédentes, les valeurs extrêmes n'existent plus. 
Maintenant, le PCA devrait être refait, avec les nouvelles observations. Dans ce cas, suivant les mêmes critères que précédemment (en utilisant le tracé d'éboulis et les valeurs propres de chacune des dimensions), on obtient 3 principaux composants car ils ont une valeur propre supérieure à 1.
## valeur propre variance.pourcentage cumulatif.variance.percent
## Dim.1 2.3094622 26.079639 26.07964
## Dim.2 1.4442754 16.309503 42.38914
## Dim.3 1.0534806 11.896446 54.28559
## Dim.4 0.8526690 9.628779 63.91437
## Dim.5 0.8060166 9.101956 73.01632
CHARGEMENT-PLOT
Une fois les dimensions appropriées obtenues, les parcelles de chargement de chacune des dimensions obtenues précédemment sont obtenues: 
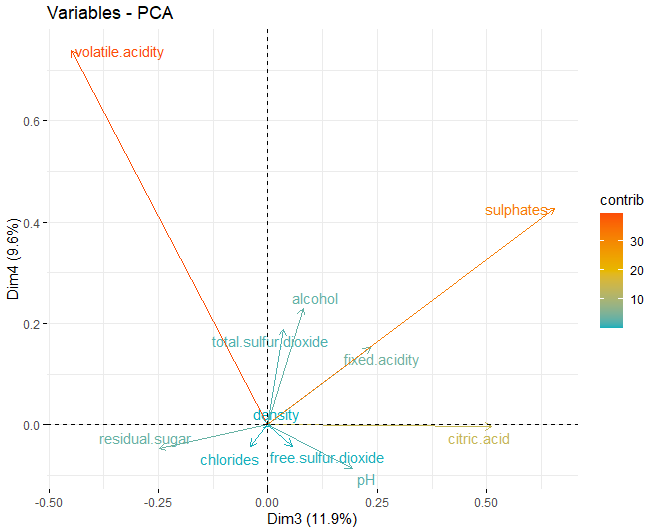
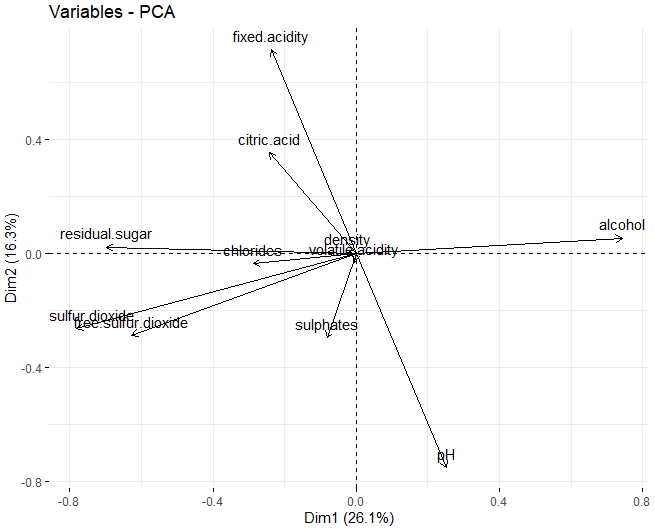
Dans ce cas, on peut voir que, dans la première dimension, les variables qui influencent le plus ces dimensions sont les composants physico-chimiques de l'alcool, sucre résiduel et les deux types de soufre, à la fois gratuit et total. D'autre part, dans la deuxième dimension, ceux qui influencent le plus sont à la fois le pH et l'acidité fixe.
3.3 DISCUSSION DES RÉSULTATS
Dans ce premier objectif, il a été constaté qu'il est nécessaire de réaliser plus d'une analyse PCA en raison des observations anormales pouvant apparaître à l'aide du Hotelling T2.. Si ces résultats ont été ignorés, les graphiques des scores et des charges ne seraient probablement pas interprétés de la même manière et des résultats seraient obtenus qui ne seraient pas entièrement réels.
En dehors de, en utilisant cette technique, il était possible d'obtenir une vue plus détaillée de la base de données en cours de traitement, analyser les variables qui influencent le plus la création des dimensions. Il a été observé que ce sont ceux de l'alcool, sucre résiduel et les deux types de soufre, soufre libre et total.
4. UNE ANALYSE 2 – CLUSTERING
4.1 OBJECTIFS
La deuxième analyse à réaliser dans ce projet sera l'analyse des conglomérats ou l'analyse des clusters. L'objectif lors de l'application de cette technique en particulier est d'obtenir quelles caractéristiques sont les plus importantes lors de l'évaluation de la qualité d'un vin à l'aide de techniques de clustering hiérarchique et d'algorithmes de partitionnement.. Au niveau de cette base de données, l'objectif est d'obtenir les variables chimiques qui influencent la valeur que la variable de réponse finit par prendre, c'est-à-dire, la qualité variable.
Finalement, vous obtiendrez un graphique coloré pour la qualité, étudier si vraiment, les clusters qui forment ces variables, sont-ils bien séparés ou non.
4.2 APPLICATION DE LA MÉTHODE – RÉSULTATS NUMÉRIQUES
4.2.1 GROUPEMENT DES DONNÉES – HOPKINS STATISTIC
Tout d'abord, avant l'application de ladite méthode, vous devez étudier s'il y a un regroupement dans les données en cours de traitement. Cela peut être fait en utilisant le coefficient de Hopkins. Il faut se rappeler que plus ce coefficient de 1, plus de regroupement existera dans les données.
La fonction hopkins déjà implémentée dans R est utilisée mais, Tu dois être prudent, car cette fonction obtient le coefficient d'une manière quelque peu différente. Calculer la statistique à l'envers, c'est-à-dire, la valeur réelle dudit coefficient est 1-H. Donc, dans ce cas 1-0.08 = 0.92. Par lequel, on peut dire qu'il y a un grand regroupement dans les données.
## $H
## [1] 0.1029338
4.2.2 HCPC – REGROUPEMENT HIÉRARCHIQUE DES PRINCIPAUX COMPOSANTS
Le HCPC est un algorithme qui regroupe des individus similaires en clusters mais avec une particularité, est conçu pour fonctionner avec les résultats d'une méthode en composantes principales. Cet algorithme permet d'obtenir un nombre optimal de clusters en utilisant une technique basée sur l'inertie.. Dans le Annexé 8.1: Bibliographie Un lien est joint pour plus d'informations à ce sujet.
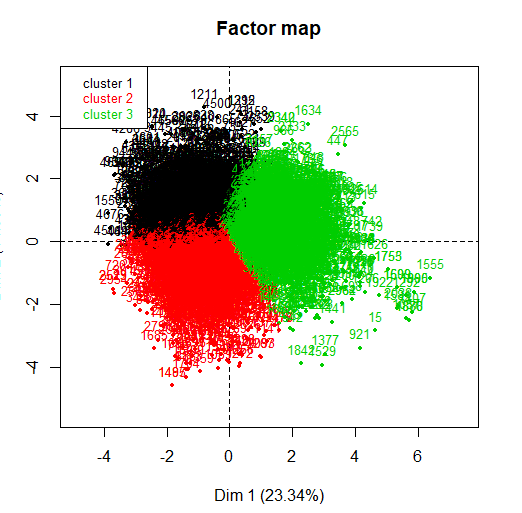
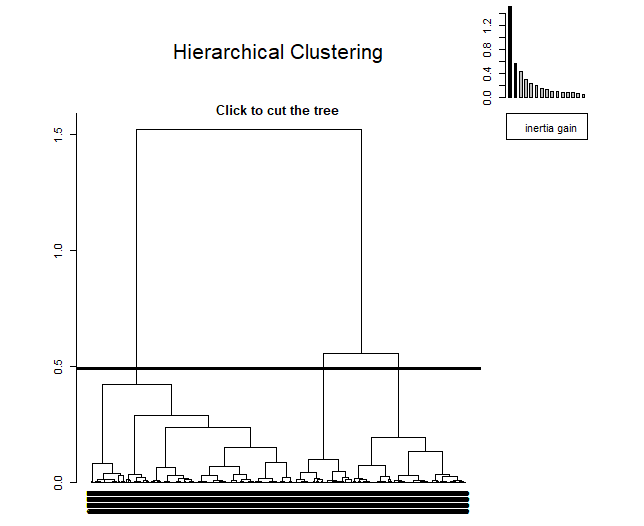
Lors de son application, peut être vu comme, en haut à droite, un petit graphique apparaît indiquant l'inertie dans chacune des dimensions. La méthode décide de prendre trois clusters depuis, du troisième composant, l'inertie est maintenue.
4.2.3 OBTENIR LA MATRICE DE DISTANCE
Après avoir présenté une première technique pour obtenir le nombre optimal de clusters, on obtient la matrice de distance, en utilisant la distance euclidienne car l'objectif est de trouver des vins aux caractéristiques similaires à, plus tard, étudier s'ils sont classés comme bons ou mauvais.
4.2.4 MÉTHODE WARD
En premier lieu, La méthode de Ward sera utilisée. La première méthode a trouvé le 3 comme le nombre optimal de clusters, pour lui, k = 3 sera attribué.
## groupes1
## 1 2 3
## 1743 2031 928
On constate que, en utilisant ladite méthode, les trois groupes formés semblent bien groupés, aucune donnée apparemment anormale.
Ensuite, Les méthodes Elbow et Silhouette seront utilisées pour valider le nombre optimal de grappes pour la méthode de Ward. 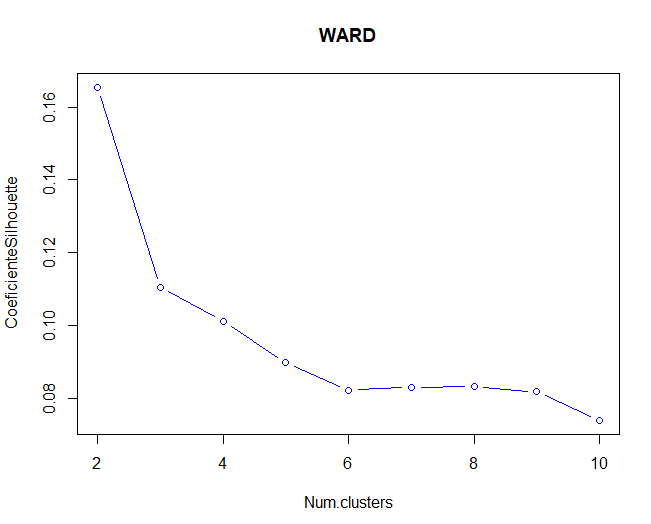
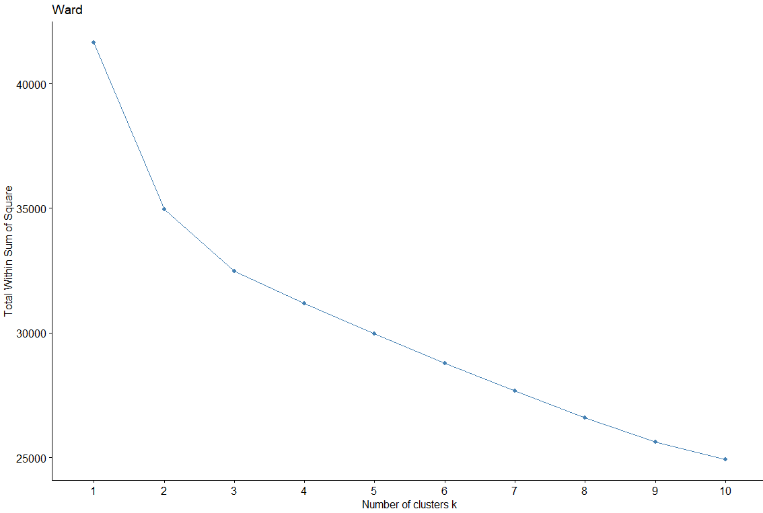
On observe que, pour la méthode Silhouette et la méthode du coude (bien que cela ne semble pas si clair), le nombre optimal de clusters serait 2 clusters. Dans ce cas, en utilisant deux clusters, plus que 1000 observations dans un groupe par rapport à un autre.
## groups1b
## 1 2
## 1743 2959
4.2.5 K-MOYENS
Ensuite, une autre méthode est étudiée, dans ce cas la méthode Kmeans ou Kmedias. Comme cela a été fait avec la méthode de Ward, k = 3 sera également attribué dans ce cas. Un bon regroupement des données est également observé en utilisant trois clusters..
##
## 1 2 3
## 1683 1475 1544
La méthode de clustering optimale est obtenue en utilisant cette méthode., aussi avec coefficient de silhouette et méthode du coude. 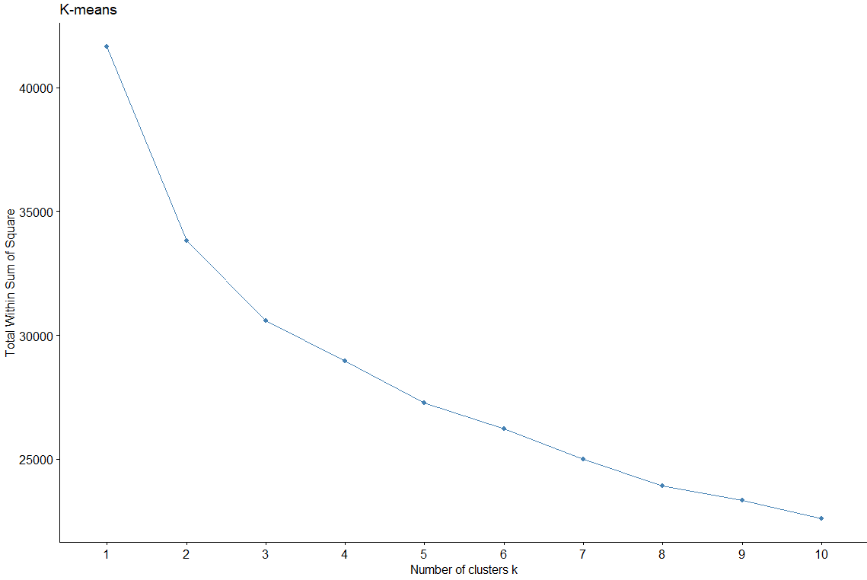
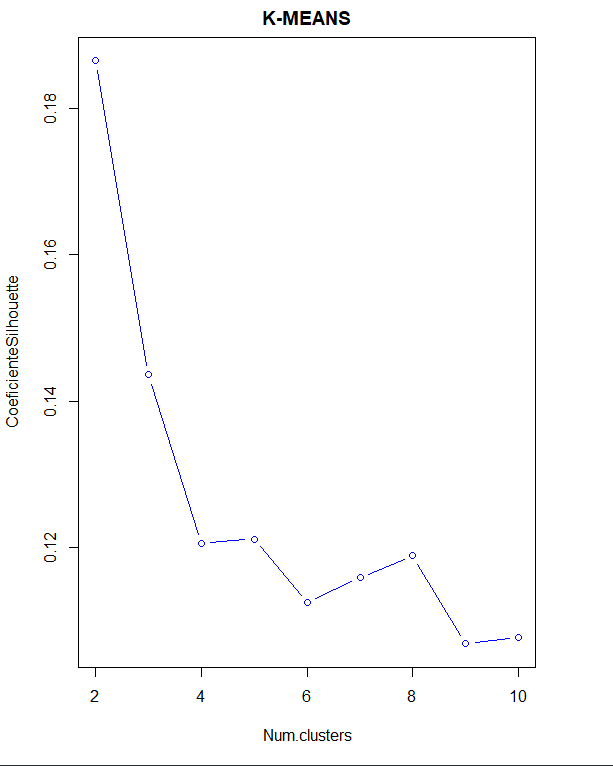
Dans ce cas, dans la méthode du coude, vous ne voyez pas un coude aussi défini. Cependant, étude du coefficient Silhouette, indique que le nombre de clusters est 2 encore une fois.
4.3 NOMBRE OPTIMAL DE CLUSTERS – VALIDATION DES RÉSULTATS
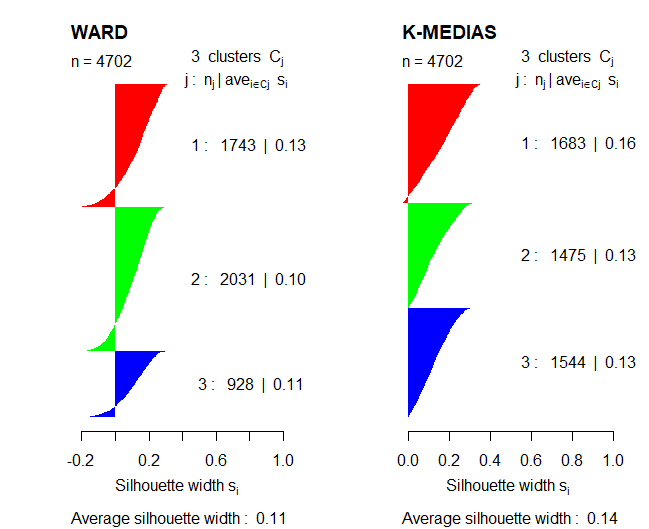
Après avoir étudié quelques méthodes pour obtenir le nombre optimal de clusters, ces méthodes seront comparées à l'aide du coefficient Silhouette afin de valider les résultats.
Comparaison des deux représentations, vous pouvez dire la méthode de partition, l'algorithme k-means, fonctionne mieux que la méthode hiérarchique de Ward parce que le coefficient de Silhouette est plus élevé dans ce cas. En outre, dans le cas de la méthode de Ward, quelques observations apparaissent avec des valeurs négatives dans le coefficient utilisé.
Donc, dans la section suivante, l'interprétation des résultats du clustering sera étudiée à l'aide de la méthode K-means. En outre, cet algorithme sera utilisé avec 3 clusters depuis, précédemment, on a observé qu'avec cette valeur K, les groupes étaient plus équilibrés, pas de valeurs anormales.
4.4 RÉSULTATS GRAPHIQUES
Après avoir indiqué que la méthode K-means sera utilisée, nous procédons à l'obtention d'un ACP pour voir quelles variables contribuent le plus à la formation des clusters. Dans ce cas, On peut observer que, en utilisant l'algorithme k-means avec 3 grappes, Les 3 les groupes se séparent très bien, ils sont équilibrés.
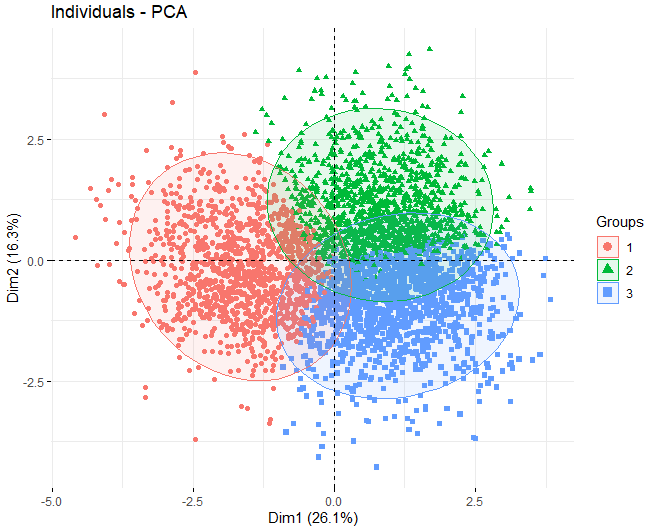
On constate que, dans les deux premières dimensions, les variables qui influencent le plus la création de grappes sont le sucre résiduel, l'alcool, et les deux types de soufre, à la fois le soufre total et le soufre libre.
Finalement, nous montrons ensuite un graphique où chacun des vins est représenté pour voir si la variable qualité influence la création des clusters. Vous pouvez voir que les clusters ne sont pas bien séparés, la plupart des points se chevauchent avec d'autres.
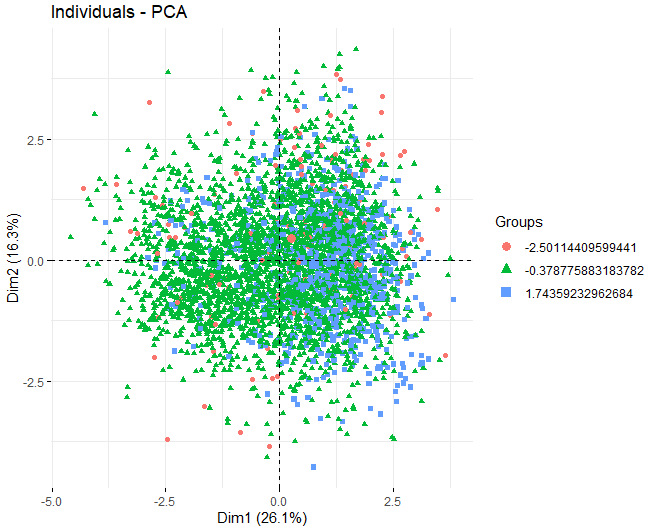
4.5 DISCUSSION DES RÉSULTATS
Grâce à cette technique, il a été observé que la variable de qualité n'influence pas la création des clusters. Cela pourrait être dû à différents facteurs qui n'ont pas été pris en compte dans l'analyse depuis le début.. Les clusters peuvent être formés en fonction d'autres variables telles que, l'appellation d'origine, le type de raisin utilisé pour l'élaboration de ces vins, etc.
5 UNE ANALYSE 3 – MOINDRES CARRÉS PARTIELS – ANALYSE DISCRIMINANTE (PLS-DA)
La technique PLS est un mélange entre régression multiple et PCA. Gardez à l'esprit que s'il existe une multicolinéarité, la régression peut ne pas être effectuée correctement et les résultats souhaités peuvent ne pas apparaître. Cependant, le PLS utilise auparavant l'ACP pour observer quelles variables sont les plus influentes dans la création des variables étudiées et chacune des composantes est orthogonale à la suivante qui influence le plus et ainsi de suite. Pour cette raison, grâce au fait que les composants sont linéairement indépendants les uns des autres, la régression peut être effectuée sans aucun problème.
L'une des variantes PLS est le PLS-DA, qui est celui à utiliser dans ce projet, qui comprend la technique d'analyse discriminante. La différence, par rapport à l'état de la technique, est que la variable de réponse est catégorique. À partir de cette variable catégorielle, autant de variables «factices» seront créées que de valeurs différentes que la variable de réponse peut prendre..
5.1 OBJECTIFS
L'objectif lors de l'utilisation de cette technique est double. D'une part, étudier d'éventuelles observations anormales (ensuite, il sera expliqué comment les traiter). D'autre part, évaluer la capacité prédictive d'un modèle PLS-DA avec la variable de qualité du vin.
Dans la première technique utilisée, le du PCA, il a été observé que, en utilisant le T2 de Hotelling, certaines observations sont apparues qui dépassaient 99%, compte tenu des observations anormales et extrêmes celles qui étaient les plus éloignées de cette coupe. Une procédure similaire sera effectuée dans le PLS. d'abord, un premier modèle PLS sera réalisé et, en utilisant la technique Hotelling T2, les éventuelles observations anormales ou extrêmes seront étudiées.
Toute observation dépassant la limite de 99% en utilisant le T2 de Hotelling puis un nouveau modèle PLS sera à nouveau créé, afin d'obtenir un modèle plus fiable qu'un autre avec des cas anormaux pouvant altérer ses caractéristiques.
5.2 APPLICATION DE LA MÉTHODE
Il est déjà passé à l'application du modèle. Vous devez d'abord transformer la variable de réponse en facteur puisque, bien qu'il soit qualitatif, le programme ne le détecte pas de cette façon car il prend des valeurs numériques.
Une fois appliqué, vous pouvez voir comment le modèle obtient 3 comme nombre idéal de composants.
## PLS-DA
## 4858 échantillons x 11 variables et 1 réponse
## mise à l'échelle standard des prédicteurs et de la réponse(s)
## R2X(sperme) R2Y(sperme) Q2(sperme) RMSEE pour ort pR2Y pQ2
## Total 0.405 0.116 0.113 0.337 3 0 0.05 0.05
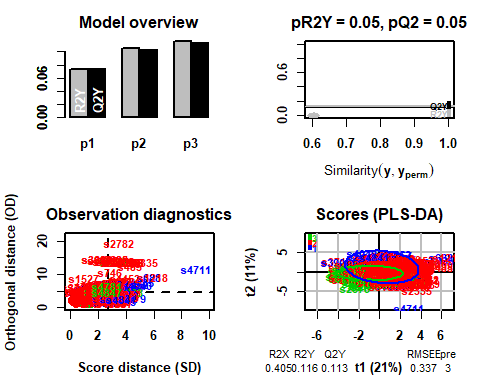
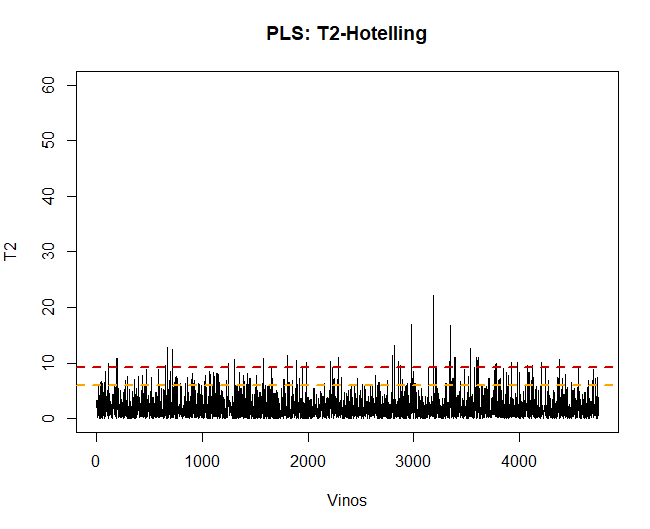
5.2.1 T2-HOTELLING
La première chose à faire, une fois le modèle appliqué, est la validation des données, observer s'il y a des observations anormales ou extrêmes qui peuvent influencer les résultats. Pour cela, un graphique du T2 d'Hotelling sera fait et pourra ainsi les détecter.
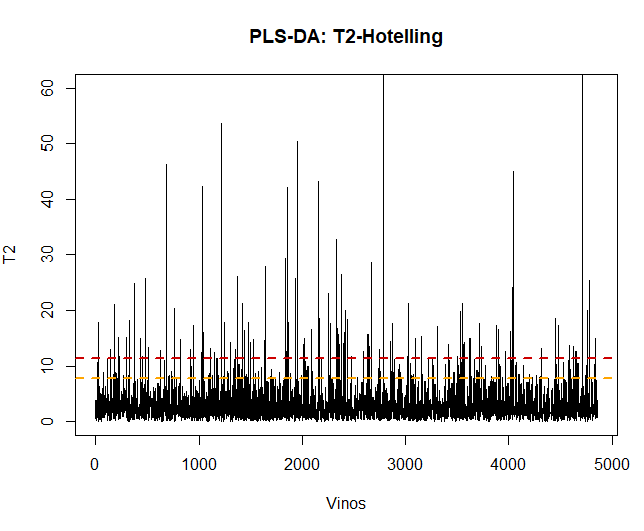
Utiliser cette technique, vous pouvez voir qu'il y en a 100 observations anormales. Ces données seront supprimées et le modèle PLS-DA sera réappliqué.
## [1] 109
5.3 APPLICATION DE LA MÉTHODE SANS DONNÉES ANORMALES
Dans ce cas, vous pouvez voir que, supprimer les observations précédentes, le modèle choisit dans ce cas 2
## PLS-DA
## 4749 échantillons x 11 variables et 1 réponse
## mise à l'échelle standard des prédicteurs et de la réponse(s)
## R2X(sperme) R2Y(sperme) Q2(sperme) RMSEE pour ort pR2Y pQ2
## Total 0.31 0.104 0.101 0.337 2 0 0.05 0.05
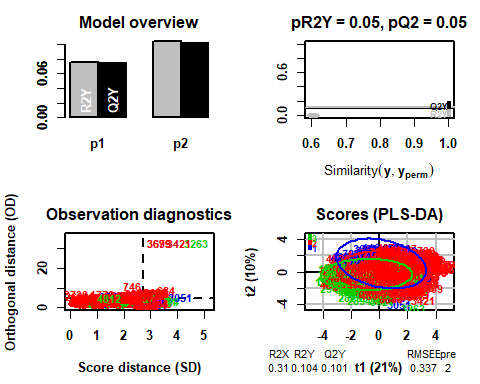
5.3.1 T2-HOTELLING
Si le graphique Hotelling T2 est maintenant affiché, Il n'y a plus de données anormales pouvant influencer le modèle.
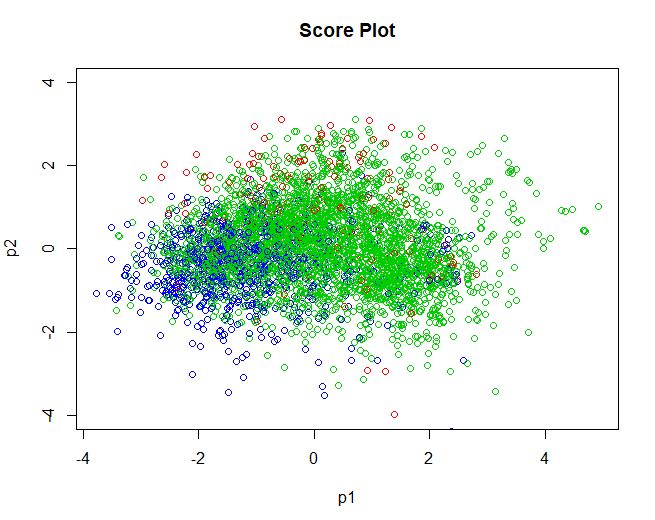
5.3.2 SCORE-PLOT
Une fois les données validées, nous continuons pour obtenir le graphique de score, relative aux individus. Des résultats très similaires sont obtenus à ceux obtenus par l'algorithme k-means utilisé dans l'analyse 2. Les groupes ne sont pas clairement séparés, se chevauchent le plus. Comme mentionné dans l'analyse précédente, cela pourrait être dû au fait que les groupes ne sont pas séparés par la qualité, mais par d'autres variables qui dans cette analyse n'ont pas été arrangées telles que l'appellation d'origine du vin, le type de raisin utilisé pour le faire, etc.
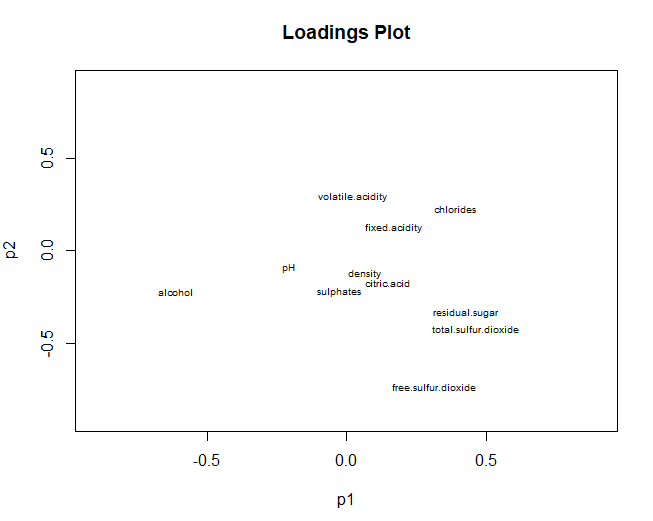
5.3.3 CHARGEMENT-PLOT
D'autre part, nous passons pour représenter graphiquement le graphique des charges, se référant à des variables. Dans ce cas, les résultats sont très similaires à ceux obtenus dans l'analyse en composantes principales.. Soufre total, soufre et alcool libres, ont une contribution élevée dans les deux dimensions. Cependant, en utilisant PLS-DA, on obtient que le pH ne contribue à aucun des deux composants (dans PCA a eu une grande contribution dans la deuxième composante)
5.4 PRÉDICTION DU MODÈLE PLS-DA
Dans cette quatrième section, la prédiction du modèle utilisé dans cette troisième analyse sera faite.. En ayant quelques 5000 observations, nous continuons à créer un ensemble de formation et un ensemble de test.
## PLS-DA
## 3800 échantillons x 11 variables et 1 réponse
## mise à l'échelle standard des prédicteurs et de la réponse(s)
## R2X(sperme) R2Y(sperme) Q2(sperme) RMSEE pour ort pR2Y pQ2
## Total 0.307 0.0982 0.0937 0.338 2 0 0.05 0.05
5.4.1 ENSEMBLE D'ENTRAÎNEMENT
Utilisation des données d'entraînement, on peut voir que le modèle a une précision de 76,55%, ce qui est une valeur très acceptable. Cependant, examinez attentivement les observations que vous prévoyez pour chacun des groupes. Cette valeur de précision est élevée car elle classe bien presque tous les vins du groupe. 2 ("Bon" avec une note entre 5 et 7). Classifie 2801 vins du groupe 2, et les 43 restant au groupe 3.
Cependant, du premier groupe n'a bien classé aucun de ces (120 dans le groupe 2 et 1 dans le groupe 3). Finalement, dans le groupe 3 a classé 108 observations appartenant à ce groupe et 727 pour le groupe 2.
Donc, on peut dire que le modèle prédit très bien les vins du deuxième groupe. Comme conséquence, la valeur de précision est élevée.
## Matrice de confusion et statistiques
##
## mypred
## 1 2 3
## 1 0 120 1
## 2 0 2801 43
## 3 0 727 108
##
## Statistiques générales
##
## Précision : 0.7655
## 95% CI : (0.7517, 0.7789)
## Aucun taux d'information : 0.96
## Valeur P [Acc > NIR] : 1
5.4.2 ENSEMBLE D'ESSAI
Finalement, valider le modèle, la même chose sera faite avant mais, dans ce cas, avec des observations que le modèle n'a pas vu auparavant (ensemble d'essai)
Une tendance similaire à celle de l'ensemble de formation peut être observée. Le modèle a une précision de 76,92%, valeur très similaire à celle obtenue dans l'autre ensemble. Cependant, comme discuté précédemment, le modèle classe très bien uniquement les vins du groupe 2 mais les deux autres groupes ne les distinguent pas bien.
## Matrice de confusion et statistiques
##
## mypred
## 1 2 3
## 1 0 30 0
## 2 0 692 19
## 3 0 170 38
##
## Statistiques générales
##
## Précision : 0.7692
## 95% CI : (0.7411, 0.7957)
## Aucun taux d'information : 0.9399
## Valeur P [Acc > NIR] : 1
6 CONCLUSIONS
6.1 COMPARAISON DES MÉTHODES UTILISÉES
Finalement, dans ce projet, trois méthodes ont été utilisées pour les trois analyses correspondantes: Analyse des composants principaux, Regroupement et moindres carrés partiels – Analyse discriminante (PLS-DA).
La première méthode, le PCA, a servi à obtenir un prétraitement des données et de cette manière, pour pouvoir étudier la base de données un peu plus en profondeur, Analyser les variables qui ont le plus contribué dans les principales dimensions obtenues. Des résultats similaires ont pu être trouvés entre le PCA et le PLS-DA, c'est, analyse du diagramme de chargement des deux techniques, les mêmes variables qui ont contribué le plus dans les deux techniques ont été obtenues, sauf quelques exceptions.
D'autre part, le PCA, grâce au nettoyage qui a été fait dans la base de données, a servi pour la seconde analyse, regroupement, car il a permis d'obtenir les clusters de manière plus équilibrée, pas de groupes anormaux avec peu d'observations.
Finalement, la méthode PLS-DA, en plus de ce qui a été commenté précédemment sur les résultats similaires obtenus avec le PCA, a été utilisé pour évaluer la capacité prédictive du modèle. Un bon premier modèle a été obtenu mais devrait être amélioré à l'avenir, parce que les groupes avec des observations plus faibles n'étaient pas prédits correctement.
6.2 DISCUSSION SUR LES MÉTHODES NON APPLIQUÉES
Trois méthodes n'ont pas été utilisées dans ce projet: Analyse factorielle des correspondances (AFC), Règles d'association et analyse discriminante. Les deux premières techniques n'ont pas été utilisées car la base de données utilisée pour ce travail ne comportait pas de variables qualitatives. (seulement la variable de réponse, la qualité du vin). Le fait de transformer toutes les variables aurait pu entraîner une perte importante d'informations.
D'autre part, Une analyse discriminante était également une bonne option pour obtenir les variables qui ont le plus influencé lors de la discrimination entre les différents groupes dans lesquels les vins ont été classés et par la suite, classer les nouvelles observations. L'ACP et le clustering avaient déjà été appliqués et, parce que l'achèvement du PLS était obligatoire, cette méthode n'a pas pu être étudiée.
Finalement, La technique PLS-DA a été utilisée dans le PLS car la variable de réponse était qualitative. De cette façon, ladite variable a été utilisée comme Y et les autres variables physico-chimiques comme X.
7. AUTRES THÈMES
7.1 COMMENTAIRES SUR LIRE DES ARTICLES
Il a été possible d'étudier que les différents groupes ne se séparent pas bien en raison de la qualité. Donc, vu ca, il a été décidé de faire un peu de recherche sur ce à quoi pourrait ressembler ce regroupement. Grâce à certaines nouvelles et articles, il a été possible de savoir que la qualité du vin n'est pas une combinaison linéaire des variables physico-chimiques disponibles. Donc, la valorisation d'un vin n'est pas linéaire, a des tendances buggy. Ces erreurs sont influencées par les critères de chaque juge.
Donc, la variable «qualité», dans le cas d'une évaluation par des juges experts, Il a certaines inexactitudes qui sont dues aux goûts de chacun de ces.
8. ANNEXE
8.1 BIBLIOGRAPHIE
- Manuel des caractéristiques du vin
- Comment savoir si j'apprécie un vin de qualité??
- HCPC
- Guide pratique des méthodes des composants principaux dans R (Kassambara)
- FactoMineR
- ANALYSE DE DONNÉES MULTIVARIANTES – Daniel Peña
- LES ÉLÉMENTS DE L'APPRENTISSAGE STATISTIQUE
8.2 ANALYSE DE DISTRIBUTION DES VARIABLES
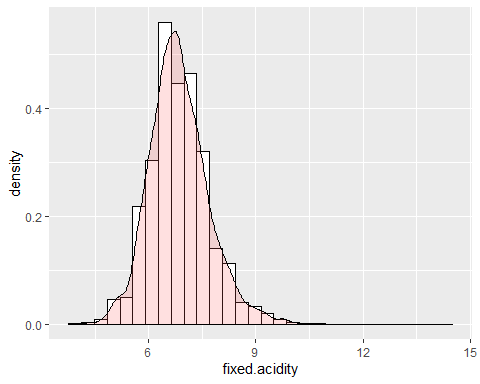
HISTOGRAMME D'ACIDITÉ FIXE
La première des variables est l'acidité fixe. Cette variable a une asymétrie de 0.647 mais un kurtosis de 5.16. Cela indique que ladite variable ne suit pas une distribution normale. Par ailleurs, une donnée extrême est observée qui prend la valeur de 14,2.
ACIDITÉ VOLATILE DE L'HISTOGRAMME
L'acidité volatile a une forme similaire à la variable précédente. Cette variable a une asymétrie de 1,576 et un kurtosis de 8,08 ce qui indique également qu'il ne suit pas une distribution normale.
On observe que les deux variables précédentes ont des queues longues et positives et, à cause de, la moyenne est beaucoup plus élevée qu'elle ne devrait l'être. 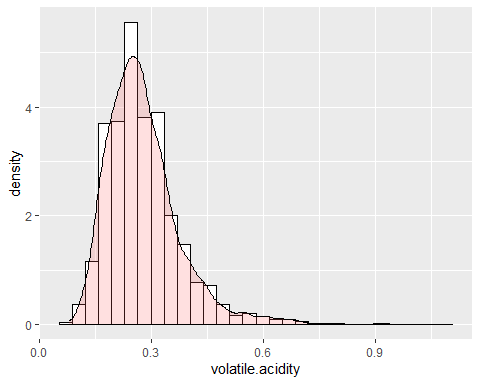
HISTOGRAMME D'ACIDE D'AGRUMES
Dans l'acide, certaines données atypiques peuvent être observées telles que 1,66 g / dm ^ 3 qui marque le maximum de la variable. En dehors de cela, une asymétrie de 1,28 et un kurtosis de 9,16. Donc, il ne suit pas non plus une distribution normale.
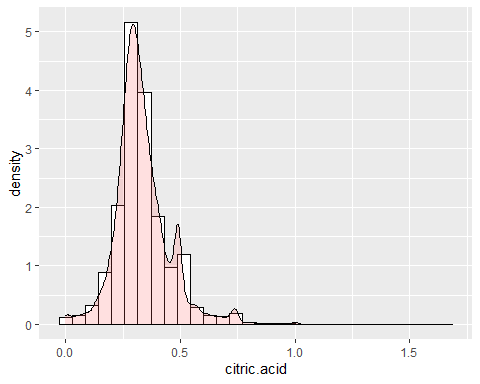
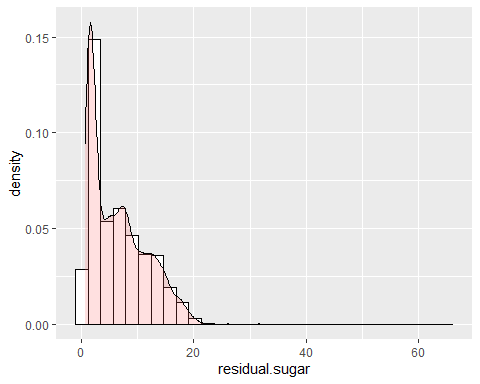
HISTOGRAMME DU SUCRE RÉSIDUEL
Le sucre résiduel a un biais positif. On observe qu'il présente une asymétrie de 1,07 et un kurtosis de 6,46, c'est-à-dire, ne suit pas une distribution normale. Un pic très élevé est observé.
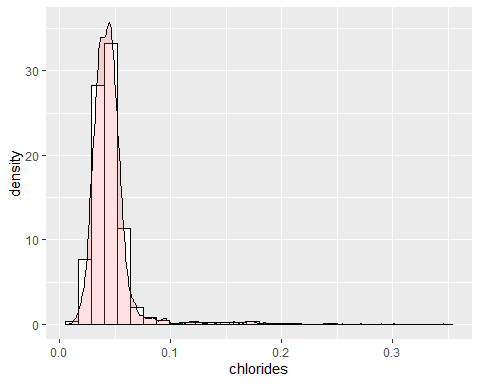
HISTOGRAMME DE CHLORE
Le chlore a plusieurs données extrêmes avec un coefficient de kurtosis de 40,52. Il présente également une asymétrie positive avec un coefficient de 5,02. Par conséquent, ladite variable n'est pas distribuée selon la cloche gaussienne..
HISTOGRAMMES DE DIOXYDE DE SOUFRE TOTAUX ET LIBRES
Distributions de dioxyde de soufre, à la fois gratuit et total, sont symétriques car ils ont des coefficients de biais de 1,40 et 0,39 respectivement. Dans les deux cas, il existe des données extrêmes (à court de 14,45 et 3,57). Ils ne suivent pas une distribution normale. 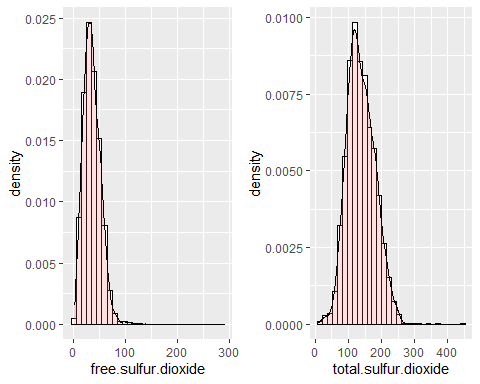
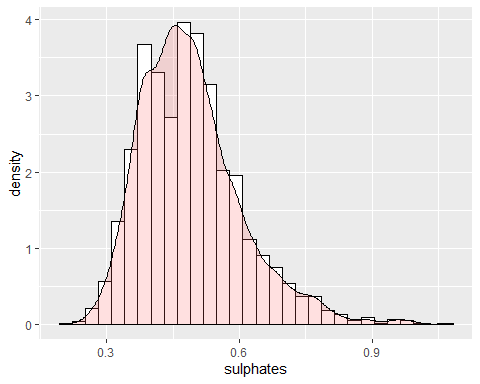
HISTOGRAMME DE SULFATE
Le sulfate a une asymétrie positive avec un coefficient de 0.9768. Puisqu'il a un coefficient de kurtosis supérieur à 2, des données anormales existent et, pourtant, ne suit pas une clochea de Gauss.
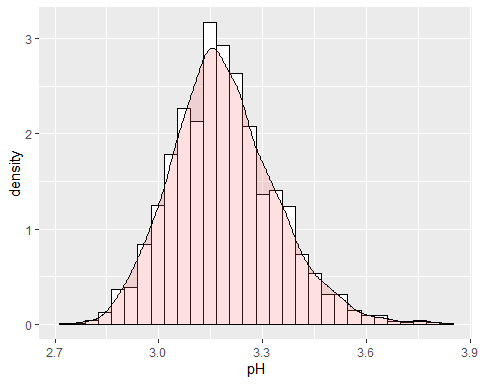
PH HISTOGRAMME
Le pH du vin est d'environ 3,15 avec des données anormales parce que le coefficient de kurtosis est supérieur à 2.