
Auteurs:
- Alvaro Mazcuñan Herreros
- Miquel Marín Colomé
- Lisa Gilyarovskaya
- Ignacio Cano Navarro
- Angel Langdon Villamayor
- Iker Rodriguez
SafeGraph « Motifs » Filtrage des données 6
Plus de sources de données pour une intégration ultérieure 7
Transformations et intégration des données 8
Normalisation des données (Micro normalisation CBG) 9
Premier coup d'œil aux visites réelles 10
Modèle / Itération d'évaluation 14
Première itération du modèle 22
Saisir les données de la page Web 25
introduction
Costomize est un projet qui essaie d'aider certaines entreprises américaines dans le nombre prévu de clients qu'elles vont avoir un jour donné, ainsi que le revenu prévu et le nombre d'employés nécessaire pour couvrir la main-d'œuvre quotidienne. Le modèle sera créé à partir de modèles de données fournis par la société SafeGraph.
Pour cela, nous avons choisi quatre entreprises américaines représentatives comme Subway, Walmart, Starbucks et Old Navy. En raison du fait que nous n'avions que 2020 et 2021 données, nous voulions choisir un endroit où la période COVID n'était pas extrêmement significative afin que nous puissions utiliser les deux années pour la formation du modèle. Notre sélection était Houston, Texas, car les restrictions n'y étaient pas aussi strictes et prolongées que dans d'autres États et les modèles de données n'étaient pas à peine affectés par COVID.
Évaluation de la valeur
Les informations extraites de nos prévisions peuvent être extrêmement utiles pour toutes sortes d'entreprises (combien de stock un magasin spécifique aura besoin, embaucher du personnel à temps partiel aux jours de pointe, prévision des revenus), en particulier pour les franchises alimentaires en raison du fait que normalement les visites de clients dans ce type d'entreprises sont équivalentes à des achats. Ces informations vont être utiles aux entreprises car elles peuvent prévoir le stock nécessaire ainsi que l'effectif. Le critère de réussite sera la capacité prédictive du modèle, C'est, dans quelle mesure le modèle sera-t-il capable de prédire le nombre de personnes qui seront présentes dans une fenêtre de temps à un endroit spécifique. Nous entraînerons le modèle puis nous ferons des prédictions et évaluerons sa précision ainsi que d'autres mesures qui pourraient intéresser des clients potentiels.
Lors de la mise en pratique de notre modèle, il peut y avoir deux façons de mal tourner: Il peut surestimer le nombre de visiteurs ou l'inverse, C'est, le sous-estimer. S'il surestime le nombre de visiteurs, l'entreprise allouerait plus de ressources (des employés, Stock) que nécessaire et cela entraînerait des pertes. D'autre part, s'il sous-estime le nombre de visiteurs, Cela se traduirait par des files d'attente plus importantes en raison du manque d'employés et même d'une pénurie due au manque de stock. C'est pourquoi notre premier conseil à nos clients serait de prendre nos prédictions comme un conseil et non comme une vérité absolue., afin d'éviter de grosses erreurs qui pourraient potentiellement causer des pertes dues à des « jours inhabituels » où par des facteurs externes non pris en compte par le modèle il y a plus ou moins de visiteurs que prévu.
Prise en compte du point de vue commercial, nous n'allons pas avoir de problèmes d'abus légal du fait que notre site web aura un espace personnel pour chacun de nos clients avec tous les rapports et prévisions personnels et un rappel que nos analyses vont être spéculatives et ne pourraient pas être pris comme une vérité absolue.
En matière d'éthique et d'environnement, nous sommes conscients qu'il pourrait y avoir un certain biais social dans nos données: les données de mobilité dont nous disposons sont obtenues à partir d'appareils Android et Apple. Logiquement, en étudiant uniquement les données des personnes possédant ces appareils, nous introduisons une certaine discrimination envers les personnes qui ne peuvent pas se permettre de tels appareils, car leurs schémas/habitudes de mobilité ne sont pas pris en compte.
Pour conclure l'évaluation de la valeur, nous tenons à souligner que notre projet a actuellement deux grandes limites. La première est due à l'origine des données, nous utilisons des modèles de données provenant d'une application qui décide quels magasins une personne en particulier a visités (plus de cela dans le Description des données section). Cela fait que les données ne sont pas aussi «réelles» que nous le souhaiterions et, par conséquent, nos prédictions seront considérablement pires que si nous disposions de données «réelles» directes de nos clients.’ nombre de visites. (Nous ne pouvons pas vérifier si les données dont nous disposons sont similaires aux visites réelles qu'un magasin a eues un jour donné ). La deuxième limitation est que nous avons entraîné notre modèle pour prédire les visites seulement un jour à l'avance, nous savons qu'il serait possible de changer cela et de rendre notre modèle capable de prédire plus d'un jour à l'avance mais ce serait beaucoup d'efforts en vain, parce que chaque entreprise aimerait que des jours différents soient prédits. Il est évident que dans une situation réelle nous nous adapterions aux clients’ Besoins.
Intégration technique
En terme de outils techniques, cette équipe voulait aller plus loin que l'année dernière. C'est pourquoi nous avons voulu passer du codage et du stockage des scripts localement à un environnement où chacun d'entre nous avait le même code complètement mis à jour en temps réel avec une possibilité de travailler en même temps à distance.
Donc, nous avons décidé de stocker notre code dans un Dépôt Github:
La fonction de base de ceci est de professionnaliser et de rendre ce projet plus sérieux. Notre objectif personnel est de nous rapprocher du monde du codage que nous rencontrerons dans le futur, afin d'être de plus en plus préparé aux pratiques commerciales ou, directement, pour un emploi fixe.
En mettant simplement en œuvre ce que nous avons mentionné, on aurait juste le « processus de stockage » de la partie outillage technique, mais il y a autre chose: Code VS. C'est un éditeur de code qui a une grande caractéristique: la possibilité de coder à distance en même temps. La fonctionnalité qui nous permet de rendre cela possible est Partage en direct. LiveShare est une extension VSCode qui partage un écran VSCode et son bash avec d'autres participants. Dans notre cas, normalement, l'un de nous partagera son environnement VSCode avec les autres, créant la possibilité que tout le monde puisse coder en même temps et exécuter les scripts sur le même ordinateur. Essentiellement, l'invité de l'environnement travaille avec la personne qui l'a créé pendant qu'il code dans l'ordinateur de l'hôte.
Comme nous menons un projet de science des données, nous devons comprendre que ces types de projets dépendent des bibliothèques sources et des outils d'analyse de données.. Du fait que nous menons un projet en équipe, il est important de corriger toutes les dépendances dans un format partageable qui permet à chaque membre de l'équipe d'utiliser les mêmes versions et de créer des bibliothèques. Sachant cela, nous utiliserons un environnement virtuel pour obtenir différents ensembles de packages Python.
Dans ce but, nous avons utilisé le pipenv paquet de Python, plus d'informations à ce sujet dans le Annexe section.
Maintenant que nous avons fini de définir les outils techniques, commençons par le packages techniques. Nous devons nous rappeler que nous travaillons avec Python 3.8.6, donc les bibliothèques que nous avons utilisées sont les suivantes:
- pandas: Il a été utilisé pour ouvrir l'ensemble des ensembles de données que nous avons, à la fois Safegraph et des informations externes provenant de différents sites. En plus d'effectuer des transformations de données qui aideront à obtenir un meilleur modèle.
- pandas-profilage: Pour créer un rapport résumé et pratique des données.
- openpyxl: Pour lire et écrire des fichiers Excel avec des pandas
- ipykernel: Pour activer les fenêtres interactives dans les fichiers .py, C'est, bloc-notes jupyter dans un fichier .py
- dateheure: Comme son nom l'indique, pour gérer les dates car nous avions différents formats dans différents ensembles de données.
- vacances: Pour savoir si un jour précis était férié ou non.
- tu: Fournit des fonctions pour interagir avec le système d'exploitation (Répertorier les répertoires, créer des chemins de fichiers valides, suppression de fichiers, copie de fichiers, etc…)..
- json: Pour traiter les fichiers json et les listes d'analyse et les dictionnaires.
- retraçage: Pour faire face à certaines exceptions en cas de besoin .
- boto3: Principalement pour écrire du code qui utilise des services comme Amazon S3 et Amazon EC2. (Pour télécharger des données depuis le compartiment SafeGraph S3)
- dégager: Pour évaluer un modèle Ridge, un modèle Lasso et un modèle de régression linéaire choisissant des hyperparamètres pour le modèle correspondant.
- matplotlib et plotly: Pour tracer les points où chacun des magasins Subway est situé à Houston.
- sélénium: Raclage du site Web wundergroud.com pour obtenir des données historiques sur la météo de Houston.
- Je trie: Pour trier les importations python automatiquement
- autopep8: Pour formater automatiquement les fichiers python .py pour qu'ils correspondent à la convention officielle Python pep8.
finalement, à part Python 3.8.6, R a également été utilisé pour former un modèle de régression linéaire pour la section « Evaluation ».
Non seulement avons-nous fait des recherches par nous-mêmes, mais aussi, dans certains cas où nous avions des doutes sur une tâche spécifique, nous avons contacté des data scientists qui ont travaillé avec les données Safegraph. Pour cette tâche, nous avons dû utiliser le Mou outil.
Dans le but de montrer visuellement notre maquette nous avons développé un page web fonctionnelle avec une description de notre « Commencez » et exemples de travail pour nos « clients ». Afin de faire la page Web, nous avons utilisé des langages Web tels que HTML, CSS, Javascript et tapuscrit et aussi des cadres pratiques pour la construction de composants réactifs (Réagir) et rendu côté serveur pour le référencement (Suivant.js). Ces technologies sont à la pointe du développement web.
L'exemple de tableau de bord fonctionnel pour chacun de nos clients a été réalisé en utilisant les technologies ci-dessus ainsi que des bibliothèques spécifiques et pratiques pour la création de tracés et de graphiques (Plotly JS) et pour l'utilisation de beaux composants d'interface utilisateur (matérialité) comme le sélecteur de date. Ces cas de travail peuvent être montrés à tout client potentiel pour démontrer comment cela fonctionnerait une fois qu'il embaucherait nos services.
En termes de méthodologie utilisé, il est décrit dans le Annexe.
Données
Description des données
SafeGraph fournit de nombreux fichiers avec des informations différentes dans chacun d'eux. Ils vont être expliqués pour le moment:
- Lieux de base (core_poi.csv): Informations de base telles que le nom de l'emplacement, adresse, Catégorie, et association de marque pour les points d'intérêt (Parce que) où les gens passent du temps ou de l'argent. [https://docs.safegraph.com/v4.0/docs#section-core-places]
- Géométrie (géométrie.csv): Empreintes de POI avec des métadonnées de hiérarchie spatiale indiquant quand les polygones enfants sont contenus par les parents ou quand deux locataires partagent le même polygone. [https://docs.safegraph.com/v4.0/docs/places-schema#section-geometry]
- Motifs (patrons.csv): Placer le trafic et les agrégations démographiques qui répondent: combien de fois les gens visitent, combien de temps ils restent, d'où ils viennent, où d'autre ils vont, et plus. [https://docs.safegraph.com/v4.0/docs/places-schema#section-patterns]
La plupart des variables sont catégoriques avec des informations sur les magasins. Il existe également des variables numériques se référant aux visites publiques dans un magasin. en outre, il y a des colonnes qui ne sont ni chaîne ni numérique, ce sont des listes ou JSON, similaire à l'horaire du magasin ou des appareils OS des gens.
SafeGraph fournit les données avec différentes mises à jour temporelles, comme tous les jours, hebdomadaire et mensuel. Il va être téléchargé directement depuis le terminal. Aussi, les fichiers sont compressés au format a.gzip.
Cette entreprise fournit des données dans une plus grande agrégation que les magasins. Par exemple, par état.Il reflète les visites par jour/semaine/mois de chaque état ou région (visit_panel_summary.csv, normalisation_stats.csv).
outre, il y a un autre fichier, la description des métadonnées (release_metadata.csv).
Enfin et surtout, l'une des plus grandes difficultés est la taille de l'ensemble de données, estimé être terminé 40 FR (une fois que nous avons filtré le houston 2020-2021 base de données).
Préparation des données
SafeGraph « Motifs » Filtrage des données
La première chose à faire était de décider quelle franchise/marque nous intéressait. Nous voulions avoir une quantité généreuse de POI d'une franchise spécifique dans un comté spécifique.
Après avoir enquêté sur l'impact de COVID sur les États américains, nous avons décidé de filtrer nos données en sélectionnant État du Texas, plus précisément le comté de Houston, parce que cette zone géographique était la les moins touchés par les restrictions de covid tout au long de 2020 et 2021. De cette façon, nous pouvons former un modèle comprenant 2020 données car les différences entre la période de pandémie de Covid et les autres années ne sont pas aussi énormes que dans d'autres villes. C'est notre méthodologie pour cette première itération de la construction de modèles, nous pensons que utiliser toutes les données disponibles est le meilleur moyen de construire un modèle avec une bonne capacité prédictive considérant que nous n'avons que des données de 2019, 2020 et 2021.
Après quelques itérations, nous avons décidé de choisissez la franchise Subway en raison de deux facteurs importants. La première est que dans la plupart des cas, quand quelqu'un entre dans un magasin de restauration rapide, normalement c'est parce qu'il va acheter quelque chose. Alors quand on compte les visites au fast food, nous comptons essentiellement les achats. Le taux de conversion est assez élevé. Cela ne se produit pas avec les magasins de vêtements. Aussi, pendant la pandémie de covid, ces types d'entreprises ont pu rester ouverts et fonctionnels avec les services à emporter, contrairement aux magasins de vêtements.
Un autre facteur important à propos de la franchise Subway est qu'il s'agit de la marque de restauration rapide avec beaucoup de locaux à Houston, plus que 200 différents magasins. Autres options auxquelles nous pensions d'autres marques comme Five Guys, Wendy’s, KFC, Burger King, Pizza Hut, Taco Bell, Starbucks et Domino’Pizzas, mais ces franchises n'ont pas autant de magasins que Subway à Houston. Pour prendre cette décision nous avons cartographié tous ces magasins franchisés en utilisant les coordonnées que nous avons dans le jeu de données.
Une autre chose que nous devions faire était de vérifier que le nombre de magasins Subway était correct, juste parce que nous pensions qu'avoir plus de 200 magasins était presque impossible. Étonnamment, il n'y a pas eu d'erreurs. Nous avons vérifié cela sur Google Maps. Si vous regardez un quartier spécifique de Houston et que vous recherchez « Métro » , ce sera très rare si vous ne pouvez pas voir au moins 10 magasins de métro. Houston est complètement surpeuplé par le métro.
Ceci est une carte de la région de Houston où chaque point bleu est un magasin Subway.
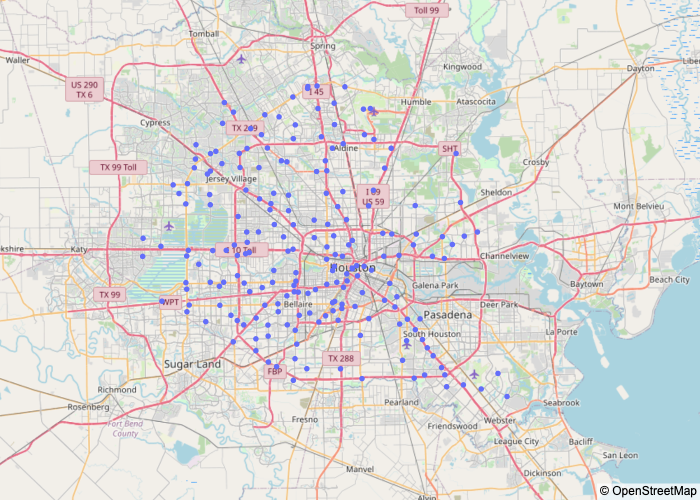
Chiffre 1 – Plan de Houston avec Subway’s
Plus de sources de données pour une intégration ultérieure
Une fois que nous avons filtré et organisé nos données SafeGraph Patterns, nous avons commencé à enquêter sur d'autres sources de données externes pour trouver Données d'historique météorologique de Houston et données socio-économiques de Houston. L'idée d'intégrer ces sources de données est de faire un modèle plus complexe en considérant d'autres caractéristiques comme un jour de mauvais temps/beau temps, bloc de recensement riche/pauvre, etc.. Nous avons aussi pensé à intégration des données de calendrier mettre des variables binaires indiquant si c'est un jour férié et une autre variable indiquant si c'est le week-end. Nous pensons que le nombre de visites dans un magasin de restauration rapide pourrait être vraiment influencé par ce genre de fonctionnalités.
Après une longue recherche et aucun résultat, nous avons demandé dans Slack Forum sur les ensembles de données socio-économiques du Texas. Grâce aux membres de Slack, nous avons réalisé que SafeGraph avait sa propre ensemble de données socio-économiques appelé « Données de recensement ouvertes ». Donc, afin d'avoir toutes les fonctionnalités précédemment décrites dans notre modèle, nous avons dû intégrer notre jeu de données principal appelé « Motifs » avec « Données de recensement ouvertes » qui dispose de ces informations socio-économiques comme par exemple, revenu par recensement. Pour ajouter encore plus d'informations, nous envisageons également de l'intégrer avec un autre jeu de données SafeGraph appelé « Lieux de base (noyau poi.csv) » .
Une fois les données de revenu obtenues et intégrées aux autres variables que nous avions déjà, nous aimerions savoir comment varie le revenu pour chacun des recensements de la ville de Houston.
Le graphique suivant a été obtenu grâce au site suivant: http://proximityone.com/harriscounty_tx.htm
On peut voir comment les zones avec le plus de ressources (plus grand que 60,000) sont situés à la périphérie de la ville.
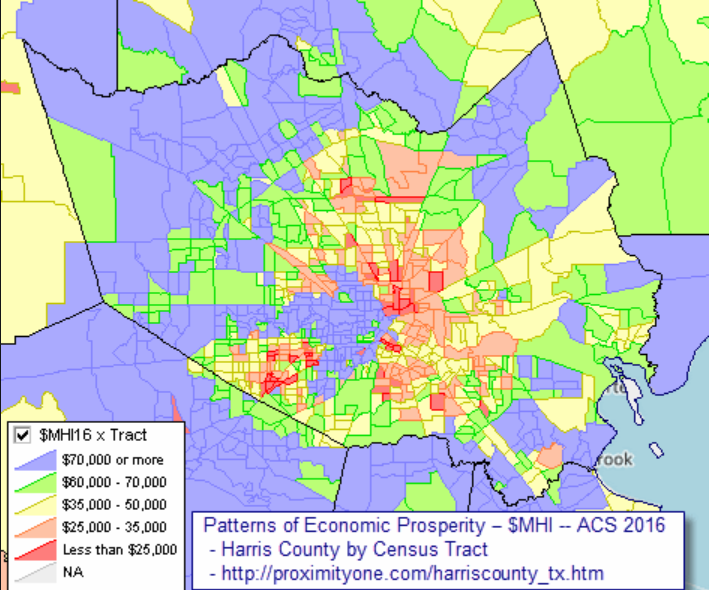
Chiffre 2 – Carte des revenus de Houston
Puis, une fois qu'il a été possible de visualiser les quartiers de la ville en fonction de leurs revenus, dans la section intitulée « Première approche des visites réelles« , les visites de certains magasins Subway seront affichées pour observer comment se comporte leur évolution et ainsi, tenir compte de l'occurrence des valeurs aberrantes.
Transformations et intégration des données
Ensuite, nous allons expliquer tous les problèmes que nous avons rencontrés dans ce jalon avec des valeurs manquantes, valeurs aberrantes et autres transformations dans chaque ensemble de données.
L'un des premiers problèmes que nous avons rencontrés après avoir filtré nos données Patterns, réalisait qu'il y avait une autre ville appelée Houston. En fait il y a 20 villes des États-Unis appelées Houston. Nous avons donc dû refaire notre filtrage en ajoutant la région ( ville=Houston et région=Houston).
Notre approche consiste à faire tous ces traitements de données dans chaque jeu de données filtré (Motifs, CorePlaces, Temps, Recensement Ouvert, Vacance) séparément avant de tout intégrer, afin d'obtenir des résultats plus propres après intégration.
Dans le « Motifs » Ensemble de données, nous avons décidé de supprimer toutes les valeurs manquantes de la fonctionnalité la plus importante: visites_par_jour. Au fur et à mesure que l'ensemble de données de modèles est construit, chaque valeur de Visits_by_day est une liste de 30 valeurs représentant les visites par jour dans un magasin Subway spécifique au cours d'un mois spécifique, dans une année donnée. Tellement vrai, les 176 les valeurs aberrantes que nous avons là représentent en fait les données mensuelles d'un magasin spécifique.
La prochaine transformation consiste à annuler ces listes pour avoir des visites par jour. Lignes qui visitent les valeurs où 0 ont été supprimés, c'est parce que cela n'a pas de sens de garder des valeurs qui sont fausses (il n'est pas possible qu'un magasin ouvert comme Subway n'ait pas au moins un visiteur) ou sont fermés. Nous avons décidé de supprimer ces données car nous pensions que lorsqu'une entreprise utilisait notre modèle, ils ne s'attendront pas à ce que le modèle prédise quand un magasin est fermé et en outre, cela rendrait la tâche de prédiction encore plus difficile.
Nous avons modifié l'ensemble de données Patterns pour avoir autant de lignes que de dates différentes (à partir de 20…) et views_by_day pour chaque date mentionnée auparavant pour chaque magasin Subway à Houston. Cette transformation est nécessaire car l'entrée attendue pour un modèle est des données quotidiennes. Aussi nous avons dû traiter quelques doublons dans cette variable.
Une autre chose à prendre en compte, lié à l'ensemble de données « Patterns », est le fait que certaines listes et dictionnaires n'étaient pas vraiment de ce type, sinon c'était des ficelles. Pour transformer cela comme de vraies listes et dictionnaires, nous devions utiliser la bibliothèque json, plus précisément la méthode "charge".
Dans le Données historiques sur la météo de Houston, obtenu de wundergroud.com, nous avons des données météorologiques historiques quotidiennes indiquant la quantité de précipitations à Houston. Le processus était simple. L'idée était d'obtenir les données de ce site Web en utilisant Selenium. Nous avons obtenu les données à partir d'un mois seulement, puis, nous avons itéré le script afin d'obtenir la quantité de précipitations dans la période de temps que nous voulions. Puis, certaines valeurs devaient être transformées simplement parce que Python ne les reconnaissait pas comme des nombres. Donc, nous devions remplacer certains caractères par d'autres, comme le remplacement du ",' à un '.' (la version standard du flotteur). Aussi, les valeurs des précipitations ont été données en pouces, nous devions donc transformer ces valeurs à une échelle plus commune, en mmHg (utilisé pour représenter combien il a plu dans un endroit). Le processus pour changer cette échelle ne faisait que multiplier la valeur précédente par 25.4, car 1 Dans = 25.4 mm.
Enfin pouvoir ajouter des données de recensement ouvertes, nous avons d'abord dû déterminer dans quel fichier csv de l'ensemble du système de répertoire Open Census Data se trouvait le « revenu médian des ménages » (B19013e1) caractéristique. Après avoir itéré chaque csv, nous avons découvert que celui dont nous avions besoin était cbg_b19.csv. Une fois que nous avons eu ces informations, nous avons créé la variable cbg_ Income dans notre ensemble de données et nous l'avons remplie en utilisant cette condition tout en itérant le fichier cbg_b19.csv. La condition vérifie ligne par ligne si le code cbg de csv est le même que celui du magasin Houston Subway cbg et si c'est le cas, nous ajoutons les informations sur le revenu pour cet îlot de recensement.
métro[‘cbg_revenu’] = np.où(métro[‘poi_cbg’] == str(ligne[1][0]), ligne[1][1], métro[‘cbg_revenu’])
Normalisation des données (Micro normalisation CBG)
Cette étape s'est avérée être l'une des plus compliquées lors de cette élaboration de Milestone II. La partie difficile de la construction d'un modèle est qu'il est difficile d'obtenir de véritables données de comptage. On s'est rendu compte que le nombre brut de visites à partir des données SafeGraph doit être normalisé afin d'obtenir des résultats plus fiables. Après une longue recherche, l'approche la plus précise que nous puissions faire dans le temps disponible consiste à ajuster le nombre de visites en fonction du nombre d'appareils SafeGraph et de la population du recensement des États-Unis dans les CBG des foyers des visiteurs.
Fondamentalement, ce que nous avons fait a été d'ajouter le Variable de recensement_Population (B01001E1) à partir des données de recensement ouvertes (dans cbg_b01.csv spécifique) à notre ensemble de données à partir des données du recensement ouvert. Nous avions également besoin de CBG_Number_Of_Devices variable de home_panel_summary.csv. Les formule nous avons utilisé pour cela normalisation divise ligne par ligne Population CBG par nombre de périphériques SafeGraph dans ce CBG * raw_visit_counts.
Premier coup d'œil aux visites réelles
Une fois la visites la variable a été normalisée, comme nous l'ont conseillé certains data scientists qui ont travaillé avec ces données, nous allons maintenant passer à la visualisation du vraies visites.
Il a été décidé d'effectuer cette tâche afin de détecter, s'il y a, magasins qui peuvent contenir des valeurs aberrantes (par exemple, magasins qui n'ont pas de visites en une journée) afin d'obtenir un meilleur modèle, avec des résultats plus réalistes, à l'avenir.
Voici quelques exemples de visites dans certains métros de Houston:
Avant d'analyser chaque capture d'écran/intrigue, nous devons expliquer l'axe X. Ici, nous avons l'évolution du temps. Cette évolution temporelle est le nombre de jours par magasin. Nous ne pouvons pas proposer une vision d'une chronologie avec un jour précis car certains jours seront supprimés (plus à ce sujet plus tard).
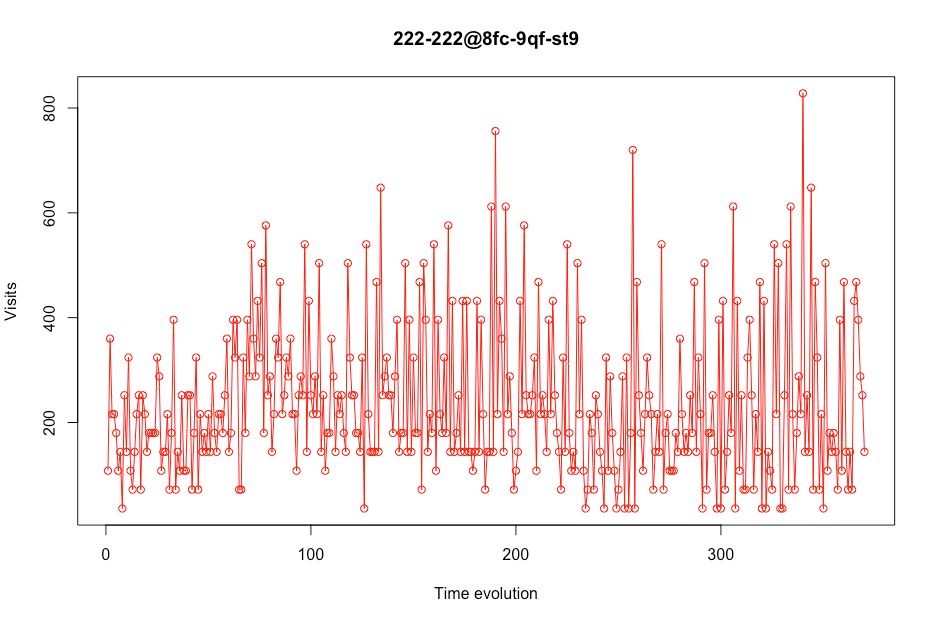
Dans cette première capture d'écran, nous pouvons voir que ce magasin particulier (stocker avec placekey 222-222 @ 8fc-9qf-st9) pourrait être considéré comme acceptable pour être utilisé comme données de formation en raison du fait qu'il contient des valeurs de visite réalistes.
Vous pouvez également voir comment les visites baissent considérablement au début du graphique. C'est parce qu'à cette époque (mi-mars), la quarantaine a commencé en raison de COVID-19. En raison de ce, il a été décidé de supprimer la plage horaire entre décembre et mars, afin que cela n'affecte pas la prédiction des visites réelles.
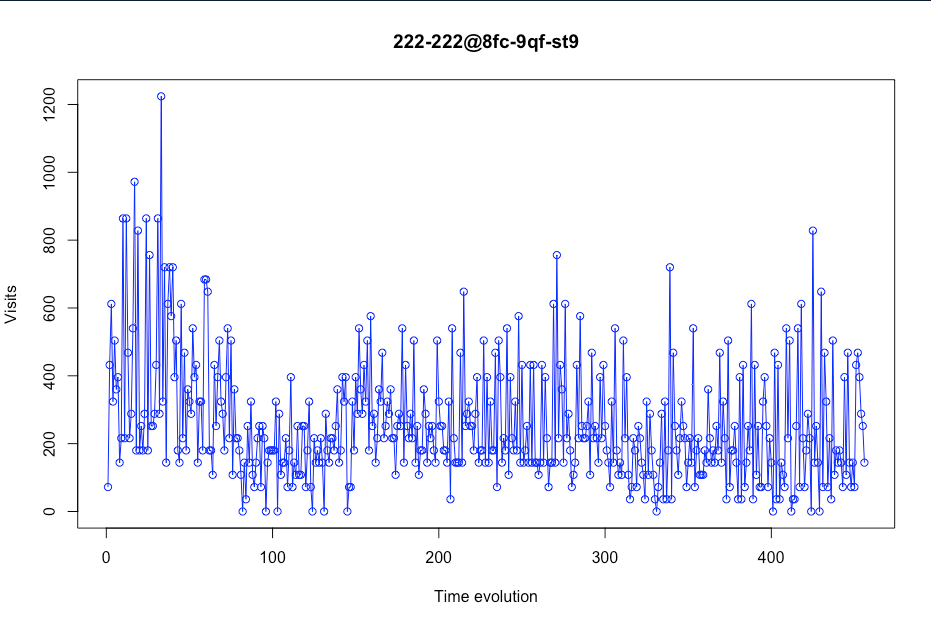
Chiffre 3 – Évolution des visites dans un certain magasin
 Ainsi, remarquez à quoi ressemble l'évolution des visites dans le magasin mentionné ci-dessus, une fois le temps de plage pré-COVID éliminé.
Ainsi, remarquez à quoi ressemble l'évolution des visites dans le magasin mentionné ci-dessus, une fois le temps de plage pré-COVID éliminé.
Chiffre 4- Evolution des visites dans un certain magasin sans data precovid
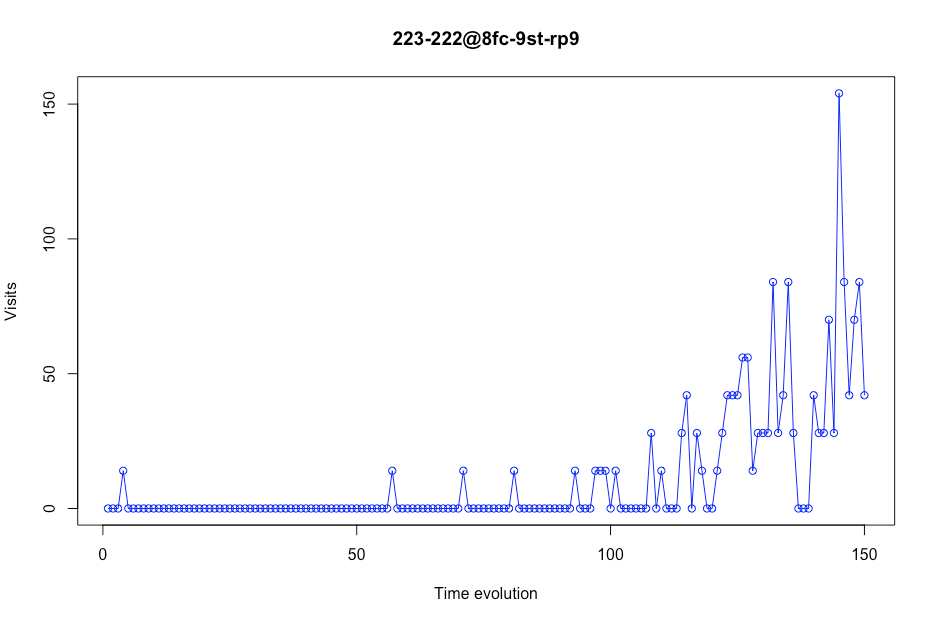 Nous ne devons pas seulement regarder les magasins avec des visites réalistes, mais aussi avec ceux qui ont 0 visites dans certaines plages de temps car ces magasins pourraient provoquer de fausses prédictions dans le modèle final qui est fait.
Nous ne devons pas seulement regarder les magasins avec des visites réalistes, mais aussi avec ceux qui ont 0 visites dans certaines plages de temps car ces magasins pourraient provoquer de fausses prédictions dans le modèle final qui est fait.
Chiffre 5 Évolution des visites dans un certain magasin
Comme nous pouvons le voir dans l'intrigue suivante, certains magasins avaient peu de valeurs. Dans ce cas, ce magasin apparaît seulement 31 fois dans les données. Nous considérons qu'un magasin doit avoir un nombre minimum de jours dans le jeu de données. Ce nombre est 200 jours. Cela signifie que s'il y a moins de 200 valeurs dans un certain magasin, ce lieu sera supprimé des données. Par exemple, ce magasin ne sera pas dans notre sous-ensemble de formation de modèle.
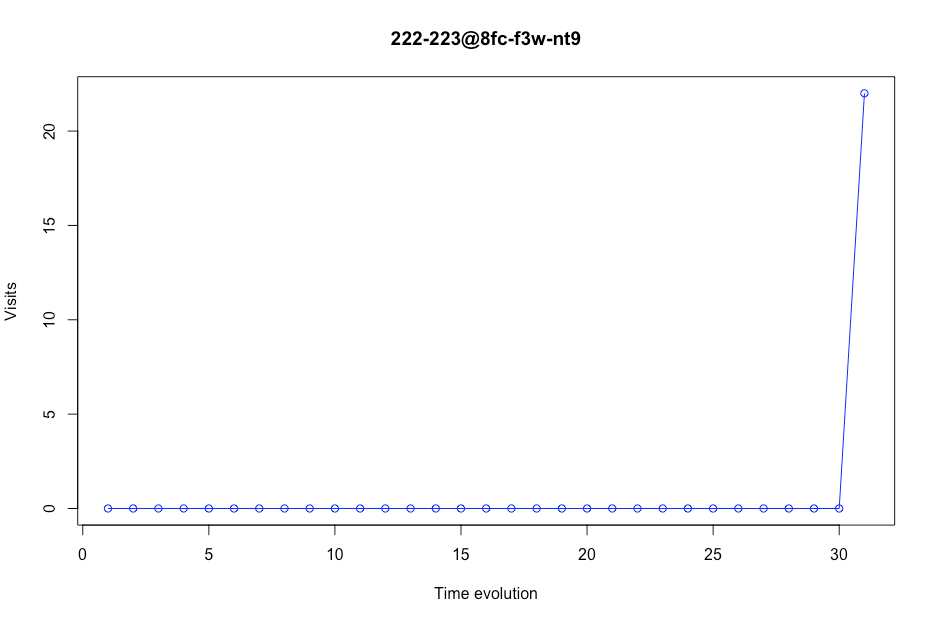
Chiffre 6 Évolution des visites dans un certain magasin
Certaines visites étaient des valeurs aberrantes, nous avons donc décidé de remplacer ces valeurs aberrantes par un nombre normal de visites par magasin. La fonction.clip() modifie les valeurs aberrantes par d'autres valeurs. Comme nous ne voulions pas perdre la caractéristique supérieure ou inférieure des visites, nous n'avons pas modifié les valeurs aberrantes par la moyenne des visites, nous l'avons changé pour le quantile supérieur ou inférieur, avec un 90% de confiance. Cela se fait avec le code suivant:
upper = df_per_store.visits.quantile(.95)
inférieur = df_per_store.visits.quantile(.05)
df_per_store[‘visites’] = df_per_store[‘visites’].agrafe(supérieur=supérieur, inférieur=inférieur)
Aussi, nous avons remarqué que l'évolution de nos visites avait d'énormes imperfections. Nous avons considéré qu'il était presque impossible qu'un certain magasin puisse avoir, par exemple, 200 visites un lundi régulier, puis ses visites tombent à 20 le lendemain. C'est une erreur que nous avons en raison de la façon dont SafeGraph compte les visites (ils calculent les visites avec le nombre d'appareils et la population d'un certain groupe d'îlots de recensement). En utilisant cette formule, l'évolution des visites est passée d'une valeur élevée à une valeur très basse. Nous avons dû lisser ces visites afin d'améliorer la compréhension du modèle de cette tendance. Cette technique s'appelle convolution.
La formule que nous avons utilisée pour moduler ces visites par magasin était:
Donc, appliquer cette convolution à nos données, nous sommes passés d'une évolution de visites comme celle-ci:
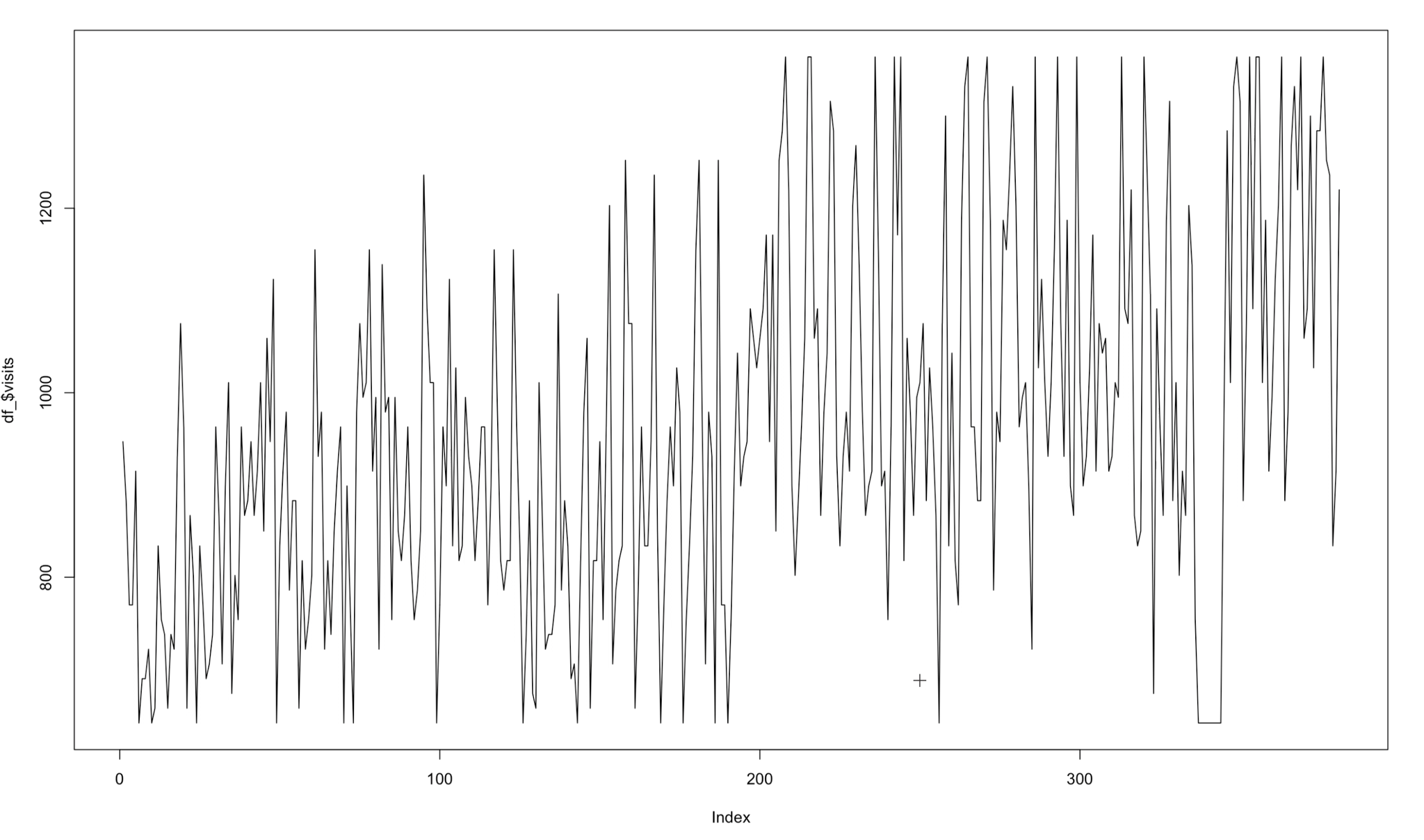
Chiffre 7 Évolution des visites dans un certain magasin
Pour ça:
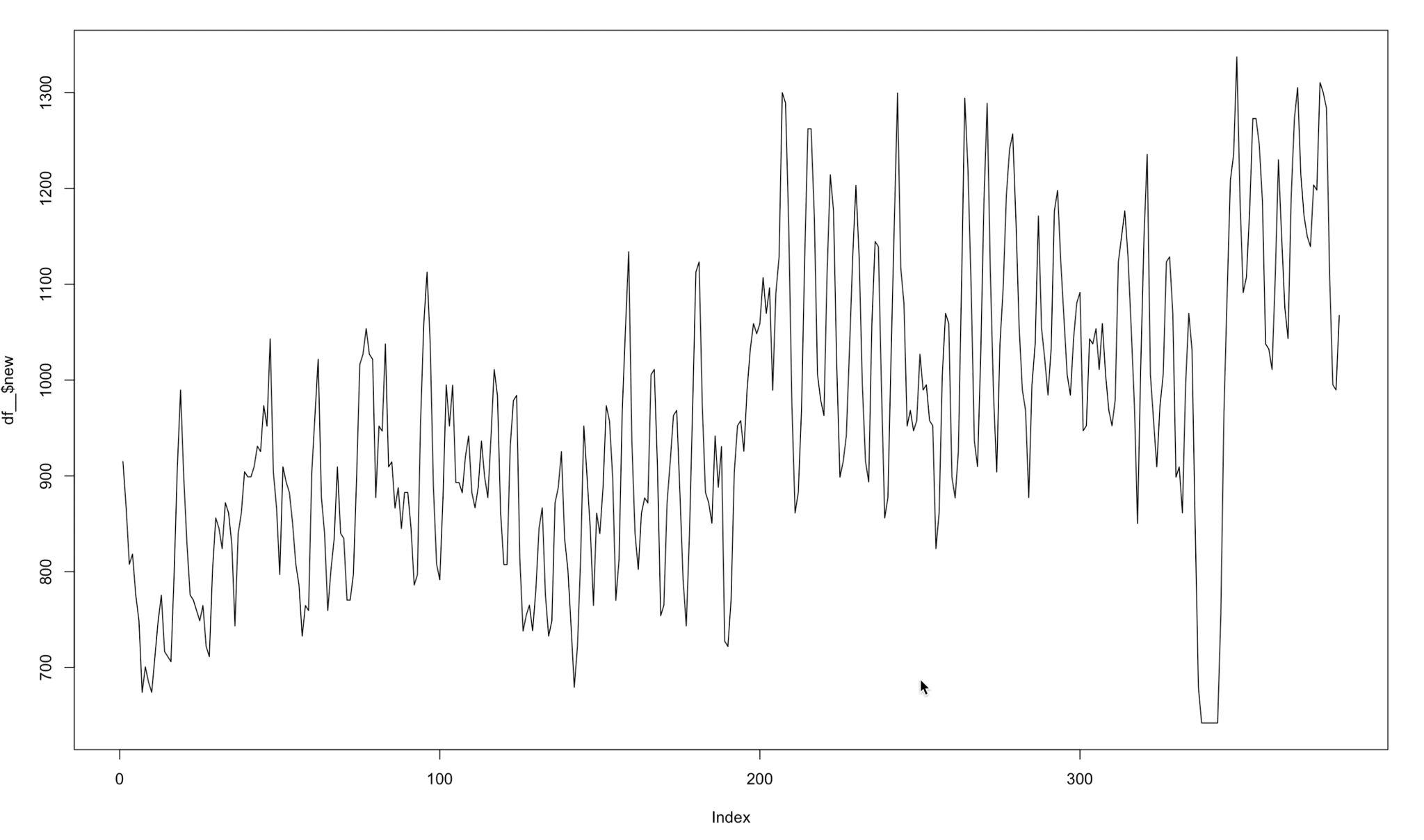
Chiffre 8 Evolution des visites modélisées dans un certain magasin
Avec ce calcul, chaque modèle s'est presque amélioré 10% de sa note. Bien sûr, utiliser cette transformation dans les données de test serait de la triche. C'est pourquoi la valeur à prédire dans les données de test était les visites sans calcul. Donc, Pour résumer, les données du train utilisent les visites modulées et les données de test ne sont pas.
Modèle / Itération d'évaluation
Après un première itération du modèle (expliqué en annexes), une régression linéaire simple le modèle a été choisi. Ses métriques étaient le MSE=5456 et le R²=0.6874. La plupart de nos fonctionnalités n'ont pratiquement aucun effet sur le modèle. Nous avons donc affronté la deuxième itération dans l'espoir de rechercher principalement de nouvelles fonctionnalités pertinentes liées au temps qui pourraient améliorer les métriques de ce modèle..
Pour le deuxième itération du modèle, avant d'ajouter une variable supplémentaire, nous avons décidé d'introduire de nouveaux magasins en dehors de Subway afin d'évaluer notre modèle final dans différents cas. Les franchises ajoutées ont été: Starbucks, Walmart et Vieille-Marine. Non seulement nous voulions nous concentrer sur le domaine alimentaire mais aussi sur d'autres secteurs comme l'habillement, centres commerciaux, entre autres.
Une fois ces magasins ajoutés, nous avons également décidé d'ajouter quelques variables supplémentaires par rapport au temps. Ceux que nous avons ajoutés pour évaluer notre modèle dans la première itération étaient les suivants: visites_semaine_dernière et hier_visites en dehors des mois et jours de la semaine.
Puis, pour cette deuxième itération, nous avons appliqué plus de plages de temps comme: signifie_dernier_3_jours, moyenne_dernières_7_jours, moyenne_dernière_14_jours, moyenne_dernière_21_jours, moyenne_dernière_30_jours, moyenne_dernière_60_jours. En dehors de toutes ces variables temporaires, d'autres ont été introduits pour ce deuxième essai. Par exemple, divisant la ville de Houston en quatre domaines (sud-ouest, Nord Ouest, sud-est, nord-est) population, le revenu par cbg, parking près des magasins.
en outre, nous voulions implémenter plus de modèles en dehors d'une régression linéaire. Pour cette raison, il a été décidé d'utiliser des techniques populaires telles que AléatoireForêt mais la version régresseur de celui-ci (AléatoireForêtRégresseur), une version régressive de Machines à vecteurs de soutien (SVR), DégradéBoostingRégresseur, XGBoost, et Empilage, qui consiste en une combinaison de différents classificateurs. Le meilleur modèle que nous ayons obtenu jusqu'à présent en termes de MSE et R2 était Empilage qui se composait de quatre modèles de base (XGBoost, LGBMrégresseur, Forêt aléatoire et régression au lasso) avec xgboost comme méta-régresseur.
Afin d'augmenter encore la capacité de prédiction de notre modèle, nous devrions utiliser GridSearchCV de sklearn à affiner chacun des modèles d'empilage, cependant comme ce n'est pas pour un vrai client nous ne l'avons pas implémenté en raison du manque de capacité de calcul (seul l'empilement a pris près d'une heure pour une entreprise).
outre, il est juste de dire que l'amélioration la plus importante que nous ayons faite pour cette deuxième itération était le fait d'appliquer le convolution technique, comme il est clairement expliqué dans la préparation des données – Section Premier coup d'œil sur les visites réelles.
Après avoir évalué toutes ces considérations qui ont été commentées précédemment, il a été possible d'obtenir que le meilleur modèle était avec les variables suivantes: journée, pluie, hier_visites , visites_semaine_dernière, moyenne_dernières_7_jours, moyenne_dernière_30_jours.
Prochain, les résultats obtenus dans chacun des magasins sont affichés une fois les améliorations, qui ont été discutés, ont été faites:
Métro
| Modèle | But (R²) | MSE |
| Régression au lasso | 0.8194 | 2606.07 |
| AléatoireForêtRégresseur (100 estimateurs) | 0.8165 | 2647.44 |
| SVM (SVR, C=1, noyau='poly', degré=2) | 0.6548 | 4981.47 |
| DégradéBoostingRégresseur | 0.8184 | 2680.45 |
| XGBoost | 0.8016 | 2928.15 |
| Empilage | 0.8190 | 2556.64 |
Table 1 Modèle de métro
Starbucks
| Modèle | But (R²) | MSE |
| Régression au lasso | 0.9127 | 7137.03 |
| AléatoireForêtRégresseur (100 estimateurs) | ** | ** |
| SVM (SVR, C=1, noyau='poly', degré=2) | ** | ** |
| DégradéBoostingRégresseur | 0.9163 | 6585.86 |
| XGBoost | 0.9063 | 7377.66 |
| Empilage | 0.9200 | 6371.41 |
Table 2- Modèle Starbucks
**Nous n'avons pas essayé de former ces méthodes en raison du fait que les résultats étaient bien pires que les autres qui sont présentés.
Walmart
| Modèle | But (R²) | MSE |
| Régression au lasso | 0.9209 | 163281.98 |
| AléatoireForêtRégresseur (100 estimateurs) | ** | ** |
| SVM (SVR, C=1, noyau='poly', degré=2) | ** | ** |
| DégradéBoostingRégresseur | 0.9163 | 133153.86 |
| XGBoost | 0.9063 | 168204.66 |
| Empilage* | 0.9348 | 126180.24 |
Table 3 Modèle Walmart
Vieille Marine
| Modèle | But (R²) | MSE |
| Régression au lasso | 0.7876 | 3228.11 |
| AléatoireForêtRégresseur (100 estimateurs) | ** | ** |
| SVM (SVR, C=1, noyau='poly', degré=2) | ** | ** |
| DégradéBoostingRégresseur | 0.7410 | 4243.22 |
| XGBoost | 0.6754 | 5319.66 |
| Empilage | 0.7339 | 4360.41 |
Table 4 Modèle Old Navy
Visualisation
introduction
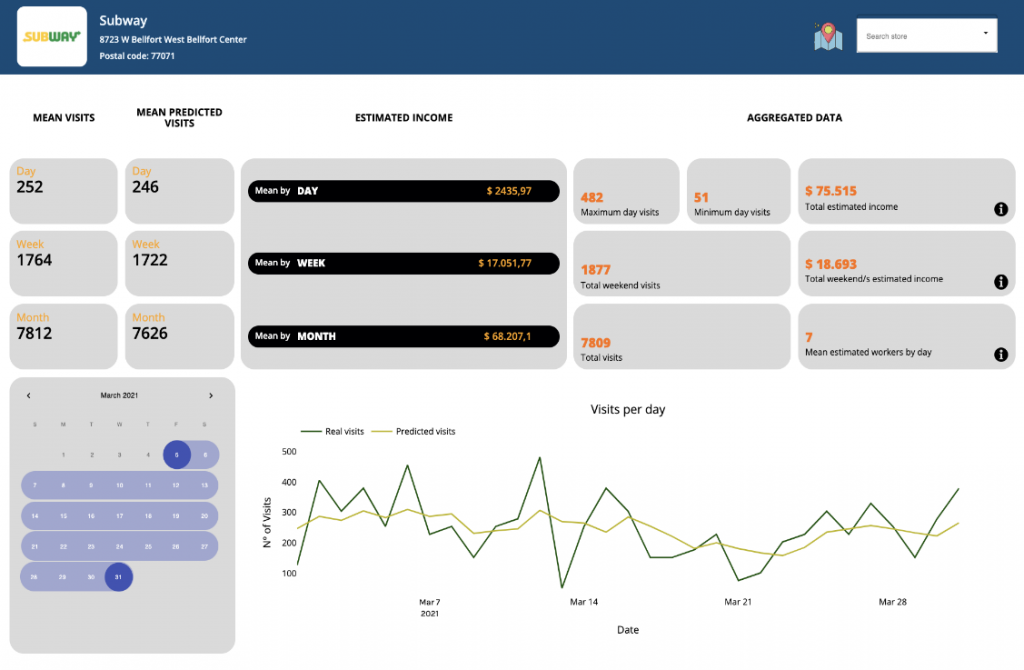
D'une vision future de startup, nous avions besoin d'un logiciel de visualisation simple afin de montrer à nos futurs clients ce que nous sommes capables de faire. Avec ça en tête, l'idée d'un tableau de bord est venue. Avec un tableau de bord entièrement fonctionnel, nos clients potentiels auraient une idée de la façon dont notre startup pourrait aider leurs entreprises dans des présentations ou des pitchs d'ascenseur.
L'utilisation de visualisations est une excellente idée pour communiquer rapidement les informations techniques fournies par les modèles d'apprentissage automatique à nos futurs clients, même s'ils ne connaissent peut-être pas l'apprentissage automatique ou la science des données en général.. Cette approche nous permet d'être créatifs, concis et efficace. Avec le slogan « Less is more » dans notre esprit, nous devions réfléchir aux informations qui devraient figurer dans le tableau de bord et celles qui ne.
Comme notre principal attrait en tant que startup était de prévoir des visites pour les entreprises, nous avons décidé d'inclure plusieurs KPI créés à partir de la prévision des visites, tels que les bénéfices estimés et la main-d'œuvre estimée, cela les aiderait encore plus. Bien sûr, chacun de nos KPI serait personnalisé pour chacun des besoins de nos clients, donc la façon de les estimer. (Ce n'est pas la même chose de prédire l'effectif d'un Walmart à partir de leurs visites que de prédire l'effectif de Starbucks)
Prendre tout en compte, nous avons décidé qu'il était vraiment important non seulement de créer ces informations précieuses pour nos clients, mais aussi de pouvoir leur montrer efficacement ces informations de manière à ce qu'ils puissent les mettre en pratique. C'est la seule façon pour nos clients potentiels de déterminer s'ils souhaitent faire appel à nos services..
En équilibre, après avoir expliqué tout notre processus de création du tableau de bord, nous joignons quelques images pour illustrer notre travail:
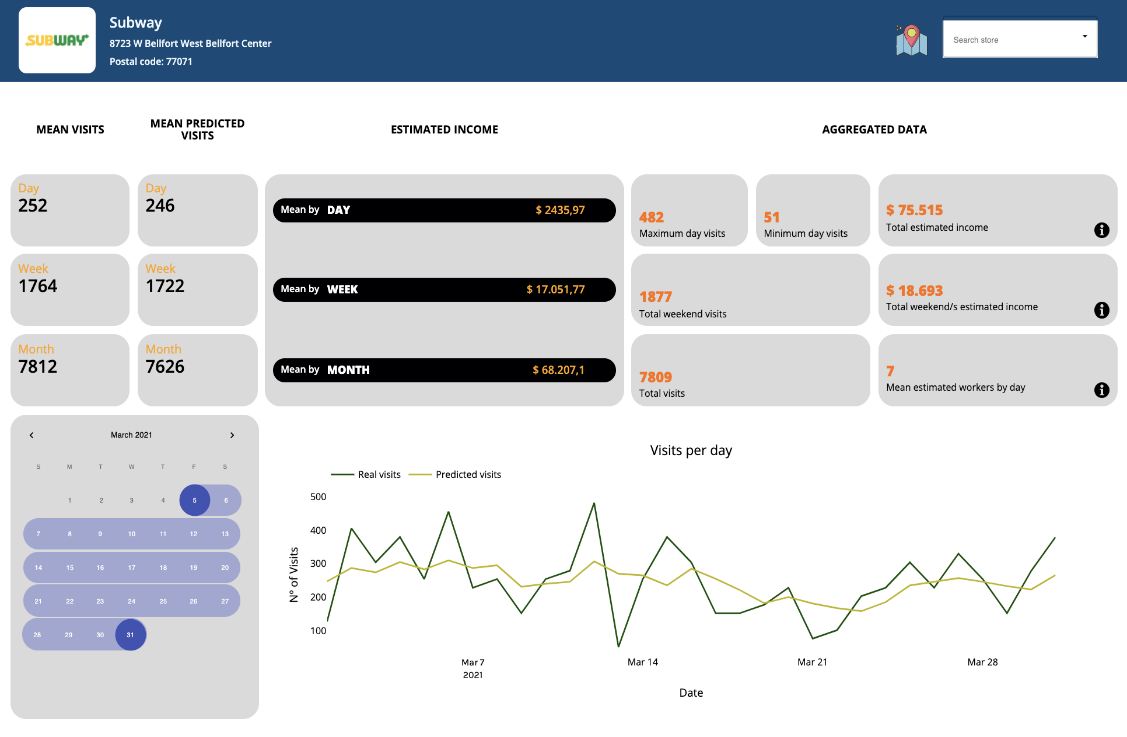
Chiffre 9 Exemple de tableau de bord
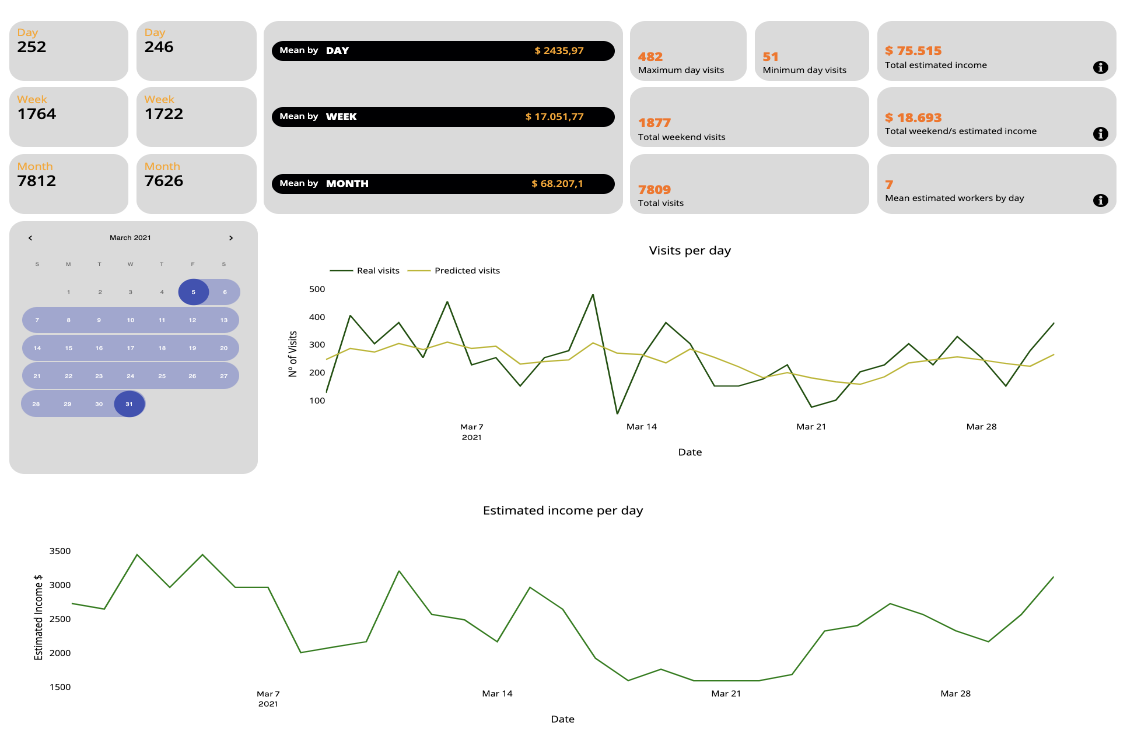
Chiffre 10 Exemple de tableau de bord
Aspect technique
Le design d'un tableau de bord n'a pas été une chose facile à imaginer. Nous avons décidé d'afficher les prévisions quotidiennes de notre modèle par rapport aux prévisions quotidiennes réelles dans une ligne de tracé afin qu'il soit vraiment simple de comparer les performances de notre modèle avec le nombre réel de visites.. néanmoins, ce n'était pas suffisant pour le tableau de bord, nous avons donc fait des recherches sur les KPI simples dans ce genre de franchises, certains d'entre eux expliqués ci-dessous:
- Nous voulions savoir combien d'argent un client dépenserait dans un Métro magasin aux États-Unis, après quelques recherches nous avons décidé de compter que normalement ce prix est d'environ 10 chevreuils. Sans compter que dans les fast-foods, la visite d'un client équivaut à un achat.
- La question suivante portait sur le nombre d'employés nécessaires par client dans un magasin Subway. D'après la plupart des articles sur le sujet, 4 il faut des employés pour servir en moyenne 150 les clients.
- Pour le Starbucks la franchise, nous avons découvert que l'achat moyen est d'environ 4,10 dollars et nous supposons également que chaque visite client équivaut à un achat.
- Dans la boutique Starbucks, le ratio employé/client est 4 employés pour 210 clients plus ou moins.
- Dans Walmart magasins le prix moyen que nous avons considéré est 55 dollars, et il n'y a pratiquement personne qui va chez Walmart sans objectif d'achat. Le ratio employé/client est 200 employés pour 2000 les clients
- Dans Vieille Marine magasins la situation est tout autre, comme nous l'avons tous vécu personnellement lors de l'achat de vêtements, il est tout à fait normal de visiter un magasin de vêtements sans rien acheter, donc pour cette statistique nous avons considéré que seulement la moitié des visiteurs deviennent acheteurs. L'achat moyen est 100 dollars dans ce cas. Cinq employés sont nécessaires pour chaque 250 clients.
Rassembler et résumer toutes ces informations, nous avons ajouté des agrégats à chacun de nos clients’ Tableau de bord en tant que Revenu estimé par jour, par semaine et par mois entre autres agrégats personnalisés.
La fonction de calendrier est fournie aux clients afin qu'ils puissent sélectionner une fenêtre de temps dans laquelle ils souhaitent connaître la valeur des agrégats tels que: revenu minimum et maximum à l'époque, bénéfices totaux, visites minimum et maximum, statistiques moyennes du week-end, etc.
Nous avons également ajouté un Nombre estimé de travailleurs par jour afin que notre client puisse prévoir la main-d'œuvre nécessaire.
Conclusion
Pour conclure ce projet de trois mois, nous allons passer en revue les phases auxquelles nous avons été confrontées en tant que groupe et comment nous avons abordé les problèmes auxquels nous avons été confrontés tout au long du projet’trajectoire de s.
La première bosse de tous était la tâche de comprendre, traiter et filtrer les données fournies par SafeGraph, suivi de la tâche compliquée d'établir un objectif réaliste limité par le temps et les connaissances dont nous disposons.
Le défi d'extraire des informations des données pour créer un nouveau, utile, et le modèle commercial engageant a été un processus qui a dû passer par de nombreuses itérations.
Une fois l'objectif de prévision des visites de certains magasins américains décidé, le projet a pris un autre rythme. Nous avons su transformer les données pour l'avoir en notre faveur afin de compléter notre objectif.
Dans la phase de construction du modèle, la complication suivante est venue de la petite taille de la fenêtre de temps que SafeGraph nous a fournie: uniquement les données de 2020 et 2021. Cela nous a limité en termes d'utilisation de modèles d'apprentissage en profondeur possibles avec une bonne réputation pour ce type de modélisation. (VOIR LSTM). L'approche choisie était de former un modèle de régression éliminant les dépendances temporelles et lissant les biais provenant des données brutes de Safe Graph. Sans oublier de nombreux essais effectués afin d'intégrer des variables d'intérêt en dehors de SafeGraph qui permettraient d'améliorer les prédictions, dont la seule réussie a été l'ajout de variables météorologiques.
Le modèle final choisi après plusieurs itérations de réglage fin a été Stacking, décrit dans le modèle / Section d'itération d'évaluation.
La décision suivante consistait à choisir le meilleur support et la meilleure façon de présenter les résultats du modèle avec une orientation commerciale.
Nous avons décidé que dans le cas hypothétique où le projet serait couronné de succès, nous serions une startup de Data Science Consulting qui aurait une plateforme numérique où chacun de nos clients aurait un espace privé avec un tableau de bord personnalisé où les prédictions / résultats des analyses effectuées.
Et voilà notre projet se termine. Partir de données très compliquées, un business model a été obtenu avec un avenir très probable dans le monde du travail. C'est une raison d'être fier.
Héritage
Comme nous l'avons mentionné, tout ce travail ne sera pas vain car nous pensons tous qu'il a un avenir pour devenir une startup à succès. Grâce à tous les progrès réalisés au cours de l'année, nous avons pu créer un projet qui montre ce que nous sommes capables de faire et comment nous pourrions aider nos clients potentiels.
Concernant les données, ce n'est pas le nôtre puisqu'il vient de SafeGraph donc il ne sera pas d'accès public. Aussi, pour des raisons évidentes, nous garderons pour nous les parties critiques du code, le garder en mode privé sur notre référentiel Github. Nous pourrions développer une documentation afin que dans le cas où quelqu'un d'entre nous essaie d'utiliser le code à l'avenir, il/elle peut facilement rattraper ce que nous avons fait dans le passé.
Les références
| Van der Walt, Stéphane, S. Chris Colbert, et Gaël Varoquaux. « Le tableau NumPy: une structure pour un calcul numérique efficace. » L'informatique en science & ingénierie 13.2 (2011): 22-30.
Liutu, Riina. « Étude de marché du métro. » (2010). |
Pedregosa, Fabien, et al. « Scikit-apprendre: Apprentissage automatique en Python. » le Journal de la recherche en apprentissage automatique 12 (2011): 2825-2830.
Gackenheimer, Cory. « Qu'est-ce que réagir?. » Introduction à React. Presse, Berkeley, CETTE, 2015. 1-20.
| Vrai, Sandro. Matplotlib pour les développeurs Python. Packt Publishing Ltd, 2009.
Marr, Bernard. Indicateurs de performance clés (KPI): Les 75 mesures que tout manager doit connaître. Pearson Royaume-Uni, 2012. Zheng, Siqi, et al. « Développement des transports en commun, commodités de consommation et valeurs de la maison: Témoignage de Pékin’s quartiers de métro. » Journal d'économie du logement 33 (2016): 22-33. Haney, Matthieu Robert. L'impact de Walmart sur les perspectives de la communauté: Une étude de deux communautés au Texas. insulter. 2009. Verbert, Katrien, et al. « Apprentissage des applications de tableau de bord d'analyse. » Scientifique américain du comportement 57.10 (2013): 1500-1509. Efron, Bradley. « Données manquantes, imputation, et le bootstrap. » Journal de l'Association statistique américaine 89.426 (1994): 463-475. brun, Robert Goodell. Lissage, prévision et prédiction de séries temporelles discrètes. Société de messagerie, 2004. |
Chose, Kai Ming, et Ian H. Witten. « Empilage de modèles ensachés et déchiquetés. » (1997).
Chen, Tianqi, et al. « Xgboost: amplification de gradient extrême. » Version du package R 0.4-2 1.4 (2015).
| Elsworth, Stéphane, et Stefan Güttel. « Prévision de séries temporelles à l'aide des réseaux LSTM: Une approche symbolique. » arXiv préimpression arXiv:2003.05672 (2020).
Muzaffar, Shahzad, et Afshin Afshari. « Prévisions de charge à court terme en utilisant les réseaux LSTM. » Énergie Procédia 158 (2019): 2922-2927. |
Annexes
Première itération du modèle
Tout d'abord, nous tenons à prendre en compte que la nature de nos données est une série chronologique. Nous l'avons transformé en convertissant les variables dépendantes du temps en nouvelles fonctionnalités modifiées. Après toutes ces transformations, nous avons obtenu des données de panel. toutefois, en essayant de faire de la validation croisée ainsi que de l'amorçage, nous avons obtenu de mauvais résultats. Cela a du sens car nos données sont intrinsèquement ordonnées et ne peuvent donc pas être échantillonnées au hasard.
Nous avons pris le premier 70% de notre ensemble de données en tant que sous-ensemble d'apprentissage et le dernier 30% comme sous-ensemble de test. Le premier réglage d'hyperparamètre que nous avons fait était avec le modèle Ridge avec alpha=1.
Les métriques que nous avons utilisées pour évaluer le modèle sont les MSE, erreur quadratique moyenne, qui sera utilisé pour évaluer la qualité de notre prédicteur. Étant donné que nous supposons que le coût de la surestimation et de la sous-estimation des visiteurs est le même, le MSE correspond à nos objectifs.
Les R², R au carré (R2) est une mesure statistique qui représente la proportion de la variance pour une variable dépendante qui est expliquée par une ou plusieurs variables indépendantes dans un modèle de régression. Alors que la corrélation explique la force de la relation entre une variable indépendante et dépendante, R-carré explique dans quelle mesure la variance d'une variable explique la variance de la deuxième variable. Donc, si le R2 d'un modèle est 0.50, alors environ la moitié de la variation observée peut être expliquée par le modèle’entrées.
Notre premier déploiement de modèle n'a pas été aussi bon que prévu. Notre modèle Ridge avait un MSE=11000 et un R²=0.27. Ces métriques étaient très améliorables.
Puis, nous avons remarqué une grosse erreur dans le sous-ensemble d'entraînement. Les données ont été triées par magasin, pas à la date. Le modèle devait capturer l'évolution de chaque ligne au fil du temps. Après avoir trié les données par date, nous avons à nouveau entraîné le modèle et l'avons testé. Maintenant, les métriques sont meilleures: MSE=6500 et R²=0.63.
Après, nous avons essayé différents modèles tels que Lasso et Elastic Net, avec différents alphas. ( Nous avons itéré différents alpha’s et choisi la plus optimale afin de créer un équilibre entre les taux d'erreur dus à la variance et dus au biais). De manière générale, l'alpha augmente l'effet de régularisation.
Le lasso avec alpha=1 était le meilleur jusqu'à présent.
Après la crête, Lasso et ElasticNet, un modèle linéaire simple a également été formé afin d'essayer de voir s'il pouvait améliorer les métriques du modèle Lasso. Nous l'avons formé en R, simplement parce que la sortie que ce logiciel donne est très utile pour comprendre le modèle. Les métriques étaient le MSE=5456 et le R²=0.6874.
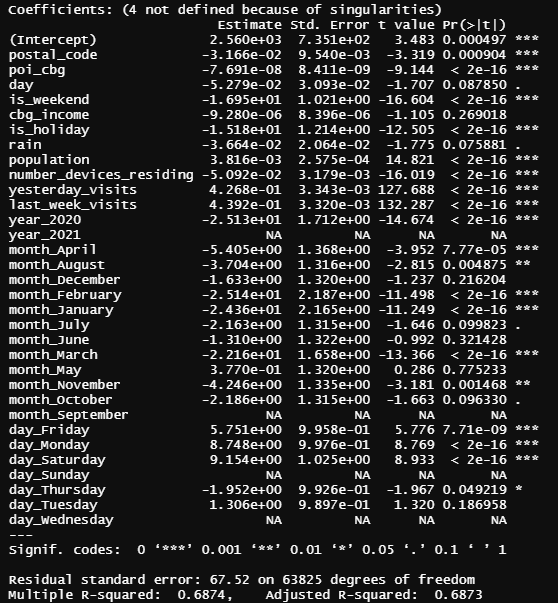
Figure annexe 1 – Sortie de régression de métro
Pour cette première étape de construction du modèle, après quelques itérations expliquées avant, nous avons finalement décidé de choisir régression linéaire simple.
Interprétation des coefficients:
Tout d'abord, les valeurs NA que nous pouvons voir dans le tableau ci-dessus sont dues au fait que le modèle a automatiquement détecté une forte corrélation dans ces variables et les a éliminées de la liste des variables de régressivité.
Les étoiles que nous pouvons voir dans la colonne de droite indiquent la signification de chaque variable, plus il y a d'étoiles, plus le coefficient est important.
Le lundi et le samedi ont des coefficients positivement significatifs, qui dit que le lundi et le samedi il y a plus de visites, tandis que les autres jours de la semaine (par exemple, jeudi) il y a moins.
À ce stade, nous ne pouvons pas expliquer le number_of_devices_residing coefficient, car selon le modèle, plus il y a d'appareils dans le cbg, moins il y a de visites. Pour la prochaine itération, nous supprimerons cette variable du modèle.
On voit que le coefficient de l'année 2020 est négatif, et comme cette variable est une variable muette, on en déduit que les visites en année 2021 ont augmenté par rapport aux visites en 2020 (ce qui a du sens avec toute la situation COVID).
En ce qui concerne le coefficient du mois, nous ne pouvons trouver aucune explication socio-économique. Nous ne savons pas comment les interpréter car cela n'a pas de sens que tous les coefficients soient négatifs, donc dans la prochaine étape nous allons probablement abandonner ces variables.
Enfin et surtout, toutes les variables que nous avons implémentées liées aux visites passées (visites de la semaine dernière et visites du dernier jour) sont assez importants pour le modèle (comme on s'y attendait) et nous fait réfléchir que si nous ajoutons plus de variables liées aux visites passées (par exemple la moyenne des visites du mois dernier) nous pourrions améliorer notre modèle.
Méthodologie
Notre méthodologie sera « Keep It Simple » (KIS), nous allons avoir trois listes de tâches, une liste se compose de tâches à faire; il a des tâches que nous devons faire mais elles n'ont pas été commencées. Une autre liste comprendra les tâches que nous avons déjà commencées et en cours (pas terminé). La dernière liste concernera les tâches effectuées, dans cette liste, nous allons stocker toutes les tâches terminées.
Chaque tâche du KIS méthodologie aura ses participants et une échéance. Chaque tâche doit être terminée avant la date limite.
Afin de suivre nos progrès tout au long du projet, nous allons utiliser Trello. Il sera utile pour gérer et organiser toutes les tâches et aussi pour voir qui est/sont en charge de laquelle. en outre, cet outil nous permettra de suivre KIS méthodologie. Toutes les listes de tâches sont visibles dans le tableau Trello suivant: (https://trello.com/b/rqu6A2U8/project2021)
En ce qui concerne la dynamique de réunion, nous utiliserons Teams ou Discord (en fonction de la qualité de la prestation le jour de la rencontre). Nous allons programmer des réunions chaque week-end à une heure qui convient à toute l'équipe (de préférence le dimanche).
En ce qui concerne l'élaboration du code, nous utiliserons Visual Studio Code Live Share qui permet le partage en direct du code, donc tout le monde dans le projet va pouvoir travailler dans le même fichier de code en même temps. en outre, nous utiliserons Github pour le versioning du code, ainsi qu'un référentiel central où la version la plus mise à jour du code sera stockée.
(https://github.com/angel-langdon/Project2021)
Pipenv
Pipenv est une bibliothèque pratique pour gérer les environnements virtuels. en outre, nous avons développé un script qui automatise l'installation des packages nécessaires ainsi que l'ajout de fonctions d'utilitaires globales au Python PATH. En faisant cela, une fois que nous sommes dans l'environnement virtuel, nous pouvons facilement importer des fonctions globales qui sont utilisées dans plusieurs parties du projet. Par exemple, à partir de n'importe quel dossier du projet, nous pourrions faire ce qui suit:
de utils.download.download_safe_graph_data importer download_census_data
Le script a été conçu pour automatiser l'installation des packages et le processus d'ajout des fonctions globales au chemin peut être trouvé ici (le script a été téléchargé il y a deux mois et peut être vérifié dans Github la date du dernier commit) :
Dépôt Github
Lien vers github: https://github.com/angel-langdon/Project2021
Saisir les données de la page Web
Lien entre les données: https://entredatos.es/project2021-costomize