
Application de méthodes statistiques et prédictives
(FAMD, Clustering et PLS-DA)
sur les données cardiovasculaires pour déterminer quelles variables causent des problèmes cardiaques.
Ange Langdon & Ignacio Cano
1. Description de l'étude et de la base de données.
1.1 Description de l'étude
Dans cette étude, une analyse de la relation entre certaines variables indiquant les propriétés physiques de l'état d'une personne sera effectuée. (détaillé plus tard) et si vous avez ou non un problème cardiaque. De cette façon, Quelles seront les variables les plus importantes pour déterminer si une personne a un problème cardiaque sera obtenue.. En outre, Une tentative sera faite pour classer les individus selon leur condition physique en deux groupes., s'ils ont eu un problème cardiaque ou non. La possibilité de prédiction à l'aide d'un modèle PLS-DA sera également étudiée..
1.2 Description de la base de données
La base de données se compose 14 variables et 303 observations. Les variables que nous traitons sont communes et faciles à comprendre. La plupart d'entre eux traitent des aspects techniques des propriétés cardiaques et des niveaux de certaines substances qui ont une influence sur la détermination de l'existence d'une maladie cardiaque.. Ensuite, les 14 variables pour plus de clarté lors de la réalisation de l'analyse, De plus, il est essentiel de savoir de quoi il s'agit pour effectuer une bonne analyse.
- Âge: L'âge de la personne en années
- Sexe: Le sexe de la personne (1 = macho, 0 = femme)
- Douleur_chest: Le type de douleur thoracique ressenti
- Valeur 0 -> Angine typique
- Valeur 1 -> Angor atypique
- Valeur 2 -> Douleur thoracique mais pas de type angor
- Valeur 3 -> Douleur asymptomatique
- (Angine = douleur oppressante causée par un apport sanguin insuffisant <> aux cellules cardiaques)
- p_sanguinea_mmHg: La pression artérielle au repos de la personne mesurée en mm Hg lors de son admission à l'hôpital
- cholestérol: Le taux de cholestérol de la personne mesuré en mg / dl
- hyperglycémie: Glycémie (glucose libre dans le sang) personne à jeun (>120mg / dl, 1 = vrai ; 0 = faux). Si elle est supérieure à 120 mg / dl, on parle d'hyperglycémie, et si le patient souffre d'hyperglycémie depuis longtemps, cela contribue au développement du diabète.
- electro_repost: Un électrocardiogramme au repos de la personne
- Valeur 0 -> Ordinaire
- Valeur 1 -> Anomalie des ondes du segment ST-T (associée à divers problèmes cardiaques selon le type d'anomalie)
- Valeur 2 -> Hypertrophie dans le datatricle gauche (causée par une pression artérielle élevée, peut provoquer une crise cardiaque)
- beats_minute: Les battements les plus élevés par minute enregistrés par la personne
- angina_by_exercise: Si l'angine a été causée par l'exercice (1 = oui; 0 = non)
- s_st: La dépression du segment ST causée par l'exercice physique est étudiée par rapport à la dépression du segment ST lorsque le patient est au repos. Plus cette valeur est élevée, plus vous êtes susceptible d'avoir un problème cardiaque..
- pending_s_st: la pente du segment ST au pic d'exercice
- Valeur 1 -> Pente ascendante
- Valeur 2 -> Boucle d'oreille plate
- Valeur 3 -> Pente négative
- Il serait intéressant de remplacer ces valeurs par 1, 0 et -1 respectivement pour être un peu plus proche de ce qu'ils représentent.
- n_vasos_sanguineos: nombre de vaisseaux sanguins principaux (0-3)
- default_type: C'est un test réalisé avec un élément radioactif (Thallium) injecté dans la circulation sanguine des patients. Cela permet d'étudier le flux sanguin au repos et à l'exercice:
- Valeur 3 -> Circulation sanguine normale.
- Valeur 6 -> Aucun flux sanguin n'est observé dans la zone, ni au repos ni à l'exercice. (défaut corrigé)
- Valeur 7 -> Aucun flux sanguin n'est observé dans la région pendant l'exercice, mais au repos. (défaut réversible)
- problem_heart: Problème cardiaque:
- Valeur 0 -> Non
- Valeur 1 -> Oui
- Valeur 2 -> Oui, pire
- Valeur 3 -> Oui, bien pire
- Valeur 4 -> Oui, le pire possible
- Il est à noter que la variable problem_heart Il servira de référence pour savoir si nous pouvons prédire des cas possibles de problèmes cardiaques à partir des valeurs que les individus prennent dans le reste des variables.. Par conséquent, cette variable sera considérée comme supplémentaire et servira de référence..
2. Analyse exploratoire initiale et prétraitement des données
2.1 Données manquantes
Nous vérifions qu'il n'y a pas de données manquantes, pour cela, un graphique des données manquantes est affiché selon la variable
Comment pouvez-vous voir qu'il n'y a pas de champ vide dans aucune variable.
2.2 Variables et / ou enregistrements supprimés.
Faire un peu de recherche, cet ensemble de données dans la colonne du numéro de vaisseau sanguin certaines observations prennent la valeur ?, ce qui est faux. (Dans l'ensemble de données d'origine, ils représentent des NaN). La même chose se produit avec la variable defect_type, qui prend courage ?, c'est mauvais. Par conséquent, nous éliminerons ces observations
2.3 Recodage des variables
Cette étape est effectuée afin d'obtenir des catégories plus descriptives. De cette façon, les catégories qui étaient auparavant «1» et «0» deviendront homme et Femme respectivement.
2.4 Distribution variable
Cette étape est effectuée afin d'observer les valeurs prises par les variables et aussi de s'assurer qu'il n'y a pas de valeurs erronées.
Dans l'annexe 8.2: L'analyse de la distribution des variables est tout expliquée
Après avoir étudié la distribution des variables, nous observons qu'aucun d'eux n'a de mauvaises valeurs, et par conséquent, nous pouvons continuer l'analyse.
3. Une analyse 1 FAMD(factominer)
FAMD (Analyse de facteurs de données mixtes) est une méthode en composantes principales dédiée à l'exploration de données avec des variables continues et catégorielles. En gros, c'est un mélange de PCA et d'AFC.
Spécifique, les variables continues sont mises à l'échelle à la variance unitaire et les variables catégorielles sont transformées en un tableau disjonctif puis mises à l'échelle en utilisant les critères AFC. Cela rend les deux types de variables représentatifs dans l'analyse.. C'est-à-dire, qu'un type de variables n'influence pas plus que l'autre type de variables. Dans ce cas, problème cardiaque corazón »sera laissé comme variable supplémentaire, afin que nous puissions voir si sans leur présence les individus sont divisés en deux groupes comme ils le feraient si ladite variable était présente. Si vous voulez trouver plus d'informations sur FAMD, vous pouvez le faire sur http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/115-famd-factor-analysis-of-mixed-data-in-r-essentials/ et aussi https://rdrr.io/cran/FactoMineR/man/FAMD.html
3.1 Objectifs
- Effectuer un prétraitement des données numériques et catégoriques pour obtenir sa matrice de score (avec les principaux composants X les plus importants) afin de pouvoir l'utiliser en clustering (le clustering ne prend pas en charge les données mixtes)
- Étudiez les relations entre les variables de l'état physique d'une personne, en laissant la variable du problème cardiaque comme un supplément afin qu'elle n'influence pas l'étude et voyez si les individus, par eux-mêmes, ils sont divisés en deux groupes (avec un problème cardiaque oui ou non).
3.2 Application de la méthode et résultats numériques et graphiques
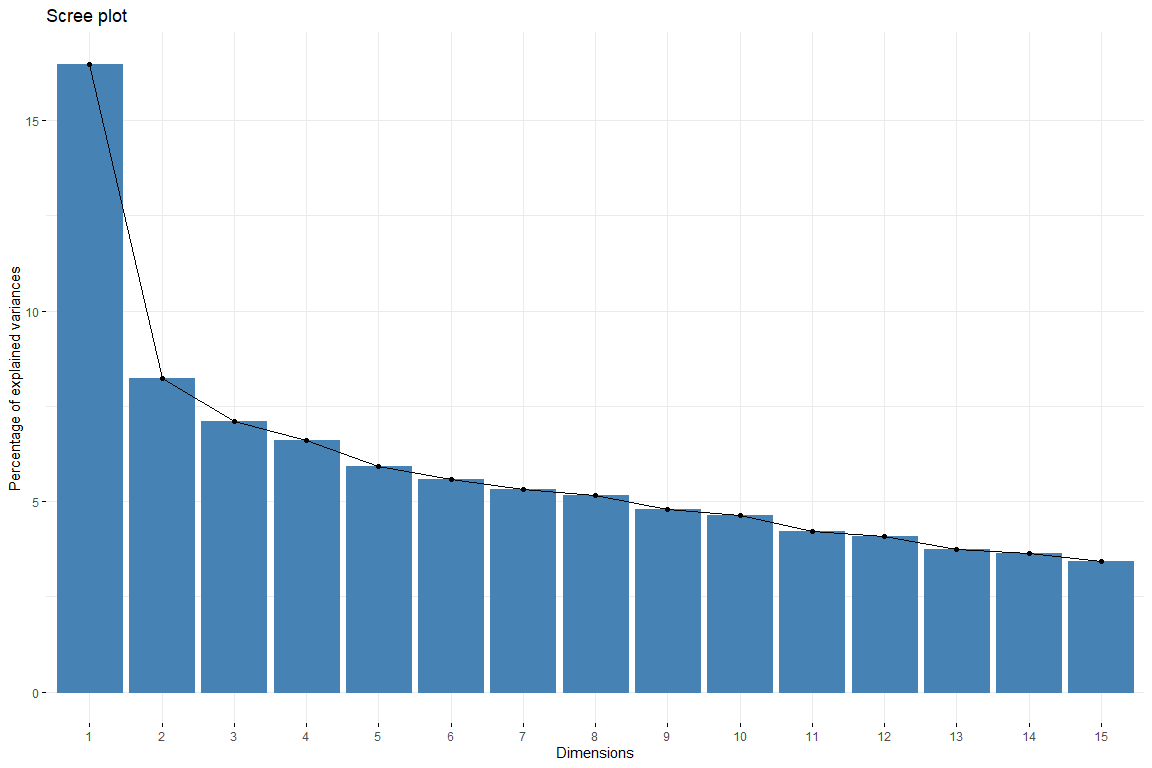
Dans le graphique en éboulis, nous pouvons voir comment 6 dimension la contribution des dimensions descend uniformément. Donc, sera choisi 6 dimensions pour représenter nos données. Nous attrapons aussi 6 dimensions depuis cette façon, nous obtenons une explication de 50% de variabilité. Nous allons maintenant étudier la contribution des variables aux premières dimensions.
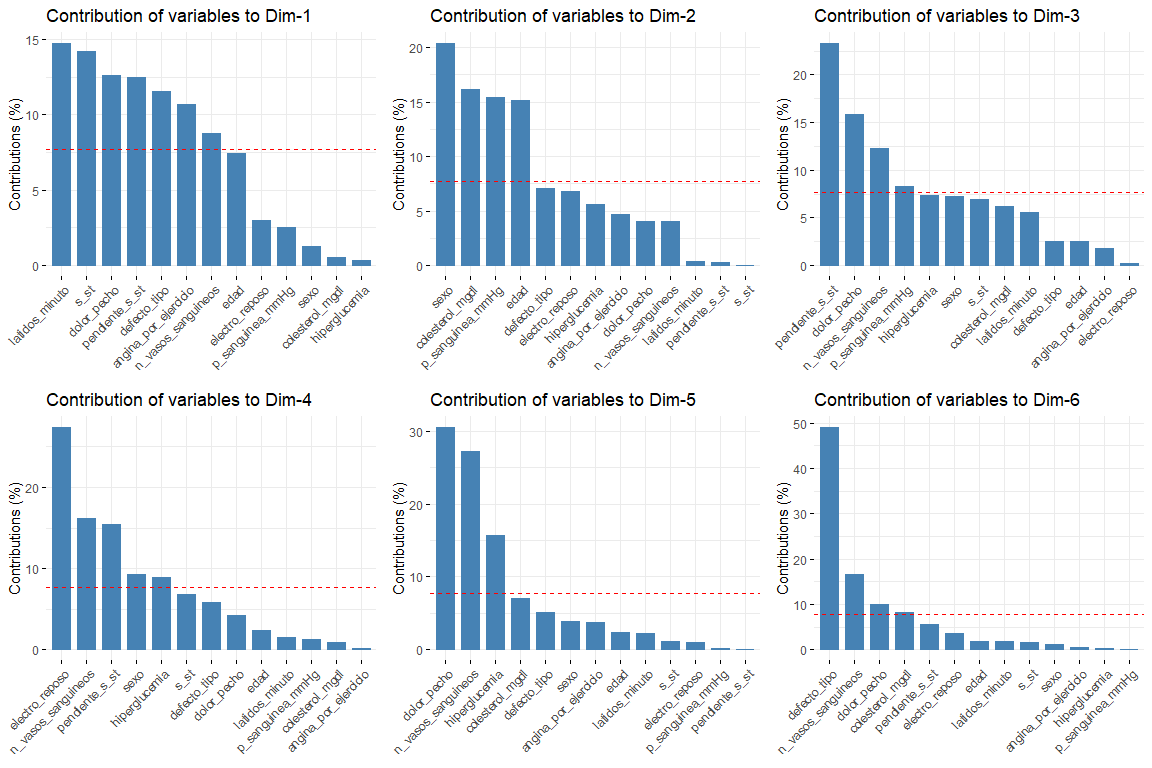
Les résultats les plus intéressants des contributions sont ceux des deux premières dimensions (car ce sont eux qui expliquent le plus de variabilité). Il est à noter que la première dimension est caractérisée par plusieurs variables (logique puisque c'est celui qui explique le plus de variabilité de tous) ce sont default_type, pain_chest et st. Dans la deuxième dimension, le nombre de variables qui caractérisent cette dimension est inférieur à celles de la première dimension, et ce sont du sexe, âge, cholestérol_mgdl, p_sanguinea_mmHg. Une fois les deux premières dimensions caractérisées, nous verrons le graphe des variables dessiné dans l'espace vectoriel des deux premières dimensions, afin d'observer les relations entre les variables, et sa caractérisation dans chacune des deux dimensions d'une manière plus visuelle.
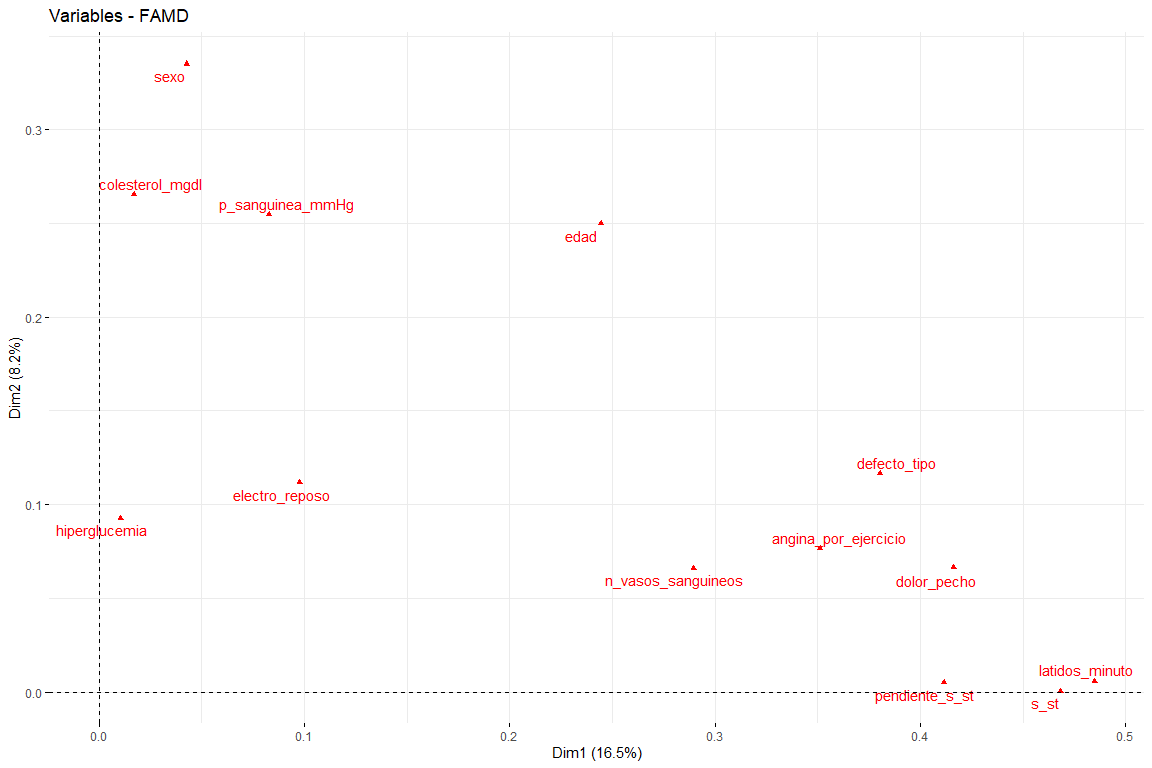
Dans ce graphique, nous pouvons voir représentés les deux premières dimensions (le plus important) et nous avons des résultats qui confirment ceux vus dans le graphique de contribution. Les variables comme latidos_minuto ou s_st sont celles qui contribuent le plus à la première dimension et les variables sexe ou âge ont une grande contribution à la deuxième dimension..
3.3 Discussion des résultats
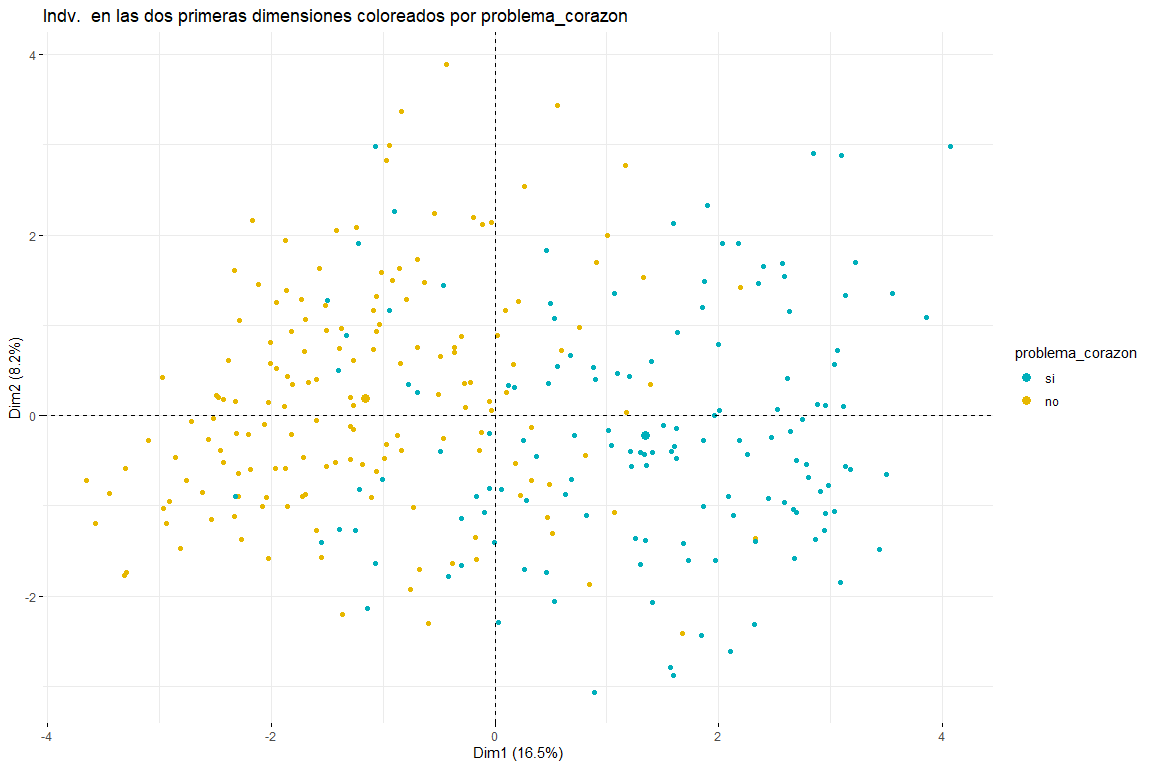
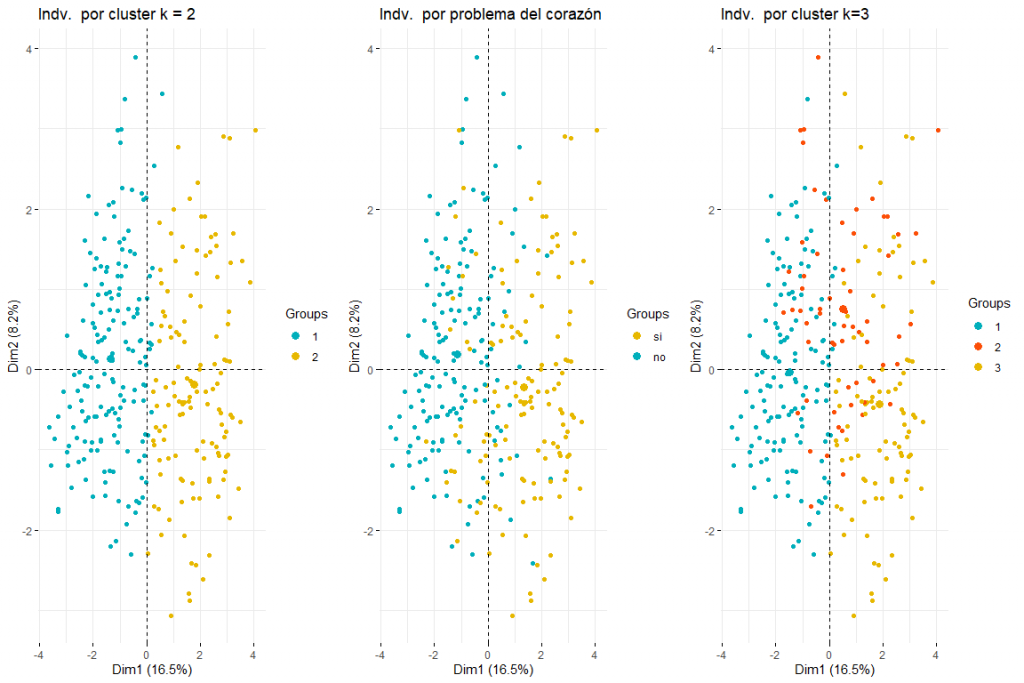
Après avoir vu le graphique des individus coloré par problema_corazon, nous pouvons distinguer entre deux et trois groupes (pour cela, des analyses de regroupement ultérieures seraient nécessaires) les deux résultats possibles ont du sens puisque deux groupes impliqueraient que les valeurs de certaines variables (default_type, douleur_chest, sexe, âge, cholestérol_mgdl, p_sanguinea_mmHg) impliquent la séparation entre les cas de problèmes cardiaques et ceux qui ne. Trois clusters pourraient également avoir un sens puisque en voyant le graphique, nous voyons comment les valeurs problem_heart = yes et problem_heart = no sont séparées, mais on peut aussi voir comment au centre les valeurs de problème cardiaque oui et problème cardiaque non, donc la présence de trois clusters pourrait également être possible. Nous pouvons également affirmer que la principale direction de séparation des groupes vient de la première dimension., donc les variables defect_type, douleur_chest, s_st, default_type, p_sanguinea_mmHg seraient ceux qui permettraient d'identifier les patients ayant souffert d'un problème cardiaque. Il apparaît également que les personnes qui ont eu des problèmes cardiaques sont non seulement déplacées vers la droite mais aussi vers le bas. Cela impliquerait que les variables qui contribuent le plus à la deuxième dimension (sexe, âge, cholestérol_mgdl, p_sanguinea_mmHg) ils devraient également déterminer si un patient a ou non eu un problème cardiaque. Ces conclusions devraient être confirmées par l'analyse de regroupement ultérieure de cette analyse FAMD..
4. Classification hiérarchique
Le HCPC (Clustering hiérarchique sur les composants principaux) est un algorithme qui regroupe des individus similaires en grappes mais avec une particularité. Il est conçu pour fonctionner avec les résultats d'une méthode en composantes principales (PCA, MFA, FAMD…). Pour plus d'informations: http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/117-hcpc-hierarchical-clustering-on-principal-components-essentials/
4.1 objectif
- À travers la matrice des scores obtenus dans le FMAD, observez si en effectuant des regroupements hiérarchiques avec ces individus, on obtient deux clusters qui regroupent les individus en personnes avec et sans problèmes cardiaques.. Au cas où cela n'arriverait pas, étudier la raison de l'existence du nombre inattendu de clusters.
4.2 Application de la méthode
Pour faire le regroupement, nous allons utiliser les coordonnées des individus dans le 6 dimensions que nous avons prises dans le FAMD. L'objectif de la FAMD, comme discuté précédemment, était de pré-traiter les données pour pouvoir ensuite regrouper. Malgré tout, Nous avons obtenu des résultats assez révélateurs avec le FAMD uniquement et il est prévu qu'avec l'analyse de regroupement, ces résultats seront confirmés..
Pour le calcul de la matrice de score qui sera utilisée ultérieurement dans le clustering, toutes les variables qui indiquent l'état physique de la personne seront utilisées. Il est souligné que dans le clustering hiérarchique, la variable problem_heart ne sera PAS incluse afin qu'elle n'ait aucun effet lors du calcul des clusters. Puisque l'objectif est de calculer des clusters à travers les variables de l'état physique, pour voir si c'est lié au problème cardiaque.
4.2.1 Nous calculons les distances et la statistique de Hopkins
Avant d'appliquer un algorithme de clustering, il est important de vous demander s'il existe un type de regroupement pour celui-ci, Nous effectuons la statistique Hopkins qui indique s'il y a un regroupement dans les données. Nous devons nous rappeler que la bibliothèque «clustertend» renvoie 1-H avec H étant la statistique de Hopkins.
$H
## [1] 0.2628502
Dans le cas des données cardiaques, le statisticien a une valeur de 0.26 très loin de 1, pourtant, nous pouvons affirmer qu'il y a regroupement dans nos données.
4.2.2 Nombre optimal de clusters
Pour pouvoir exécuter l'algorithme de clustering hiérarchique, il faut connaître le nombre optimal de clusters. Pour cela, nous allons exécuter les tests suivants.
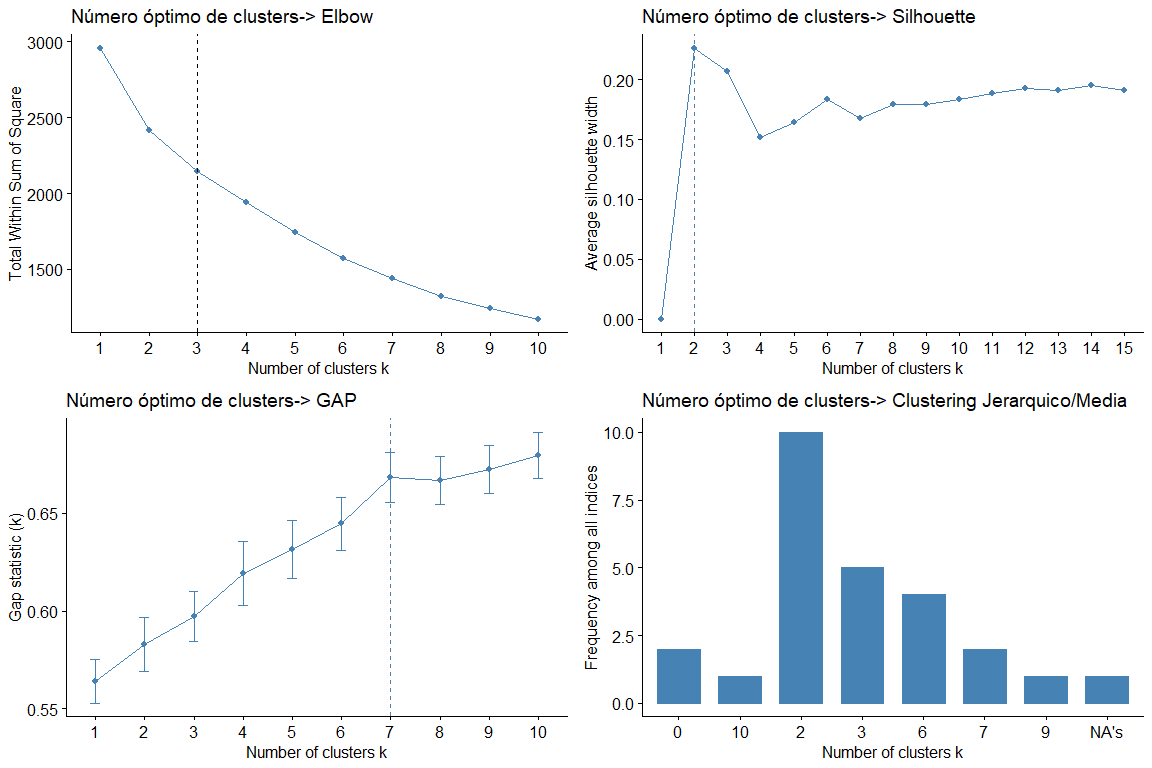
En regardant les graphiques et les tableaux, nous pouvons voir que pour les différentes statistiques et méthodes, nous obtenons différentes valeurs de clusters. Le résultat le plus fréquent est de considérer 2 grappes, suivi de 3 grappes. (le résultat 7 il semble également répété mais comme il ne serait pas logique de considérer 7 groupes nous rejetons cette conclusion)
Ensuite, nous faisons un graphique en grappes de 2 et 3 clusters respectivement pour voir lequel correspond le mieux à nos données. Nous utilisons pour obtenir les données kmeans car lors de l'analyse des données, nous pouvons voir que les données n'ont pas de valeurs très extrêmes et donc, pas besoin de méthodes plus robustes comme PAM, par exemple.
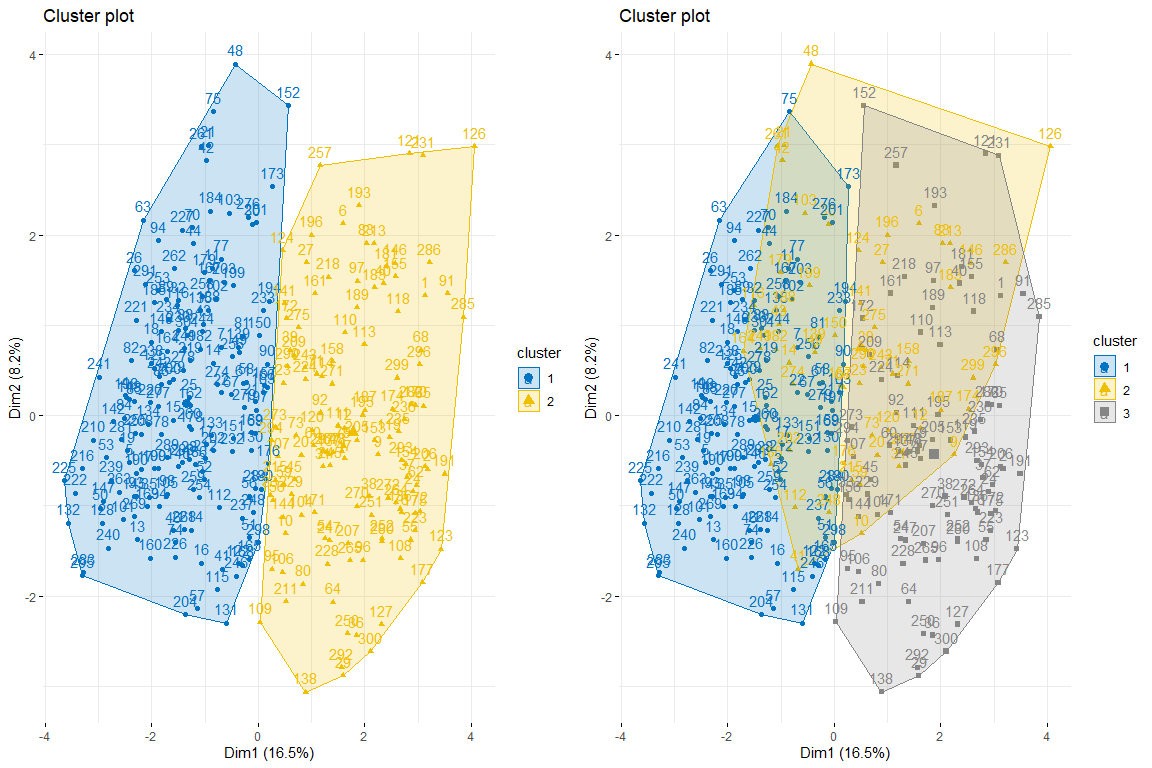
Comme nous pouvons l'observer 2 les clusters semblent être la meilleure option car ils créent 2 groupes assez naturels, c'est-à-dire, les personnes ayant des problèmes cardiaques et celles qui ne le font pas.
Nous allons poursuivre la comparaison entre deux et trois grappes en colorant les individus du tracé des individus FAMD..
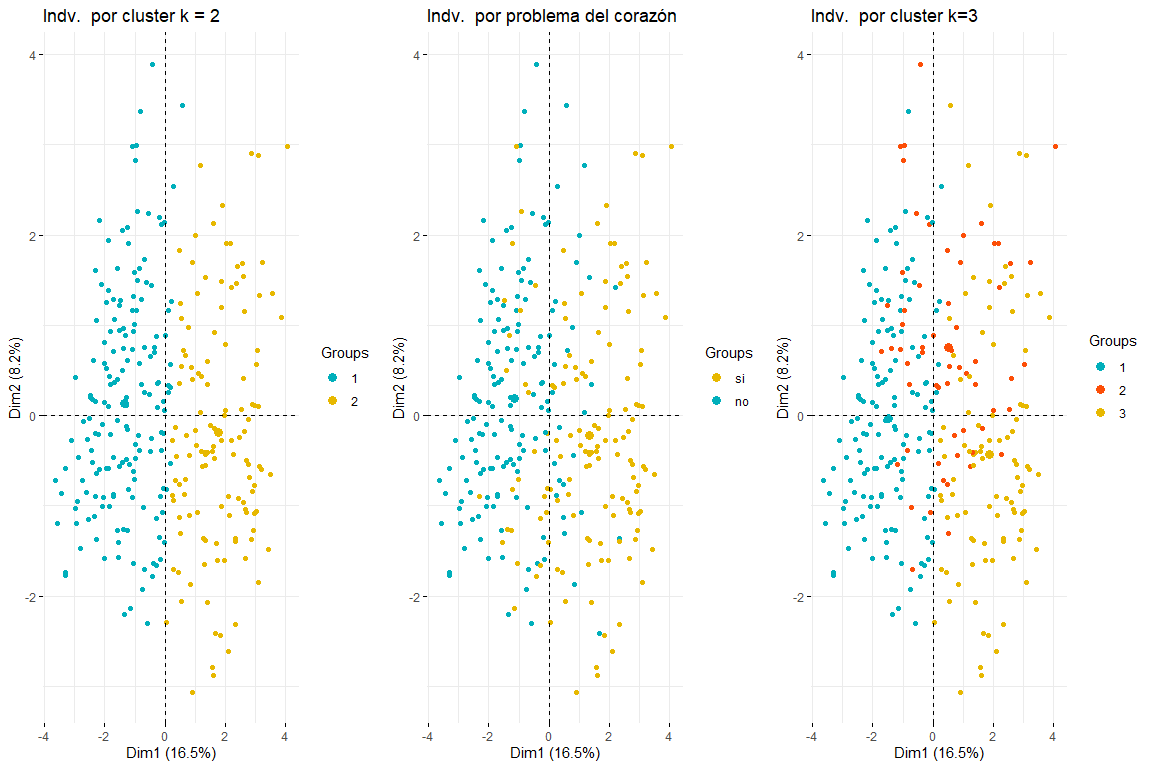
Comme on peut le voir dans les trois graphiques des individus colorés par grappe et par problème cardiaque, il est apprécié que deux clusters est celui qui s'adapte le mieux, et ressemble plus au tableau des individus colorés par problème cardiaque. Après avoir comparé ces trois groupes de graphiques, nous pouvons conclure que l'utilisation de deux clusters correspond davantage à la distribution des données selon problem_heart. Pour tout ça, deux clusters seront choisis pour le clustering hiérarchique.
4.3 Résultats numériques et graphiques
Enfin, la relation entre les variables et les deux clusters et, donc, leur relation avec le fait qu'ils aient ou non un problème cardiaque. Nous commencerons par la relation entre les catégories de variables qualitatives et l'appartenance à un cluster ou à un autre. Il est évident que les catégories les plus liées à un cluster sont celles avec un v.test plus élevé, tandis que ceux dont la valeur de v.test est très négative, moins liés seront avec ledit cluster (et comme nous n'avons que deux clusters, ces catégories avec un v.test très négatif seront probablement liées à l'autre cluster.).
res.hcpc2$desc.var$Catégorie
## $«1»
## valeur p. v.test
## pente_s_st = positive 2.930295e-25 10.384064
## angina_por_exercise = angina_no_exercise 1.061236e-23 10.035774
## default_type = normal 2.733441e-22 9.709997
## n_vasos_sanguineos = 0 4.846452e-13 7.229537
## douleur_chest = angine_atipica 4.782592e-11 6.577551
## douleur_chest = douleur_no_angina 1.569061e-07 5.244266
## sexe = femme 4.235184e-05 4.094260
## electro_repost = normal 4.769950e-03 2.822173
## $«2»
## Cla / Mod Mod / Cla Global
## valeur p. v.test
## angina_por_exercise = angina_exercise 1.061236e-23 10.035774
## pendiente_s_st = plana 5.739929e-20 9.149120
## douleur_chest = asymptomatique 8.164639e-19 8.857749
## defect_type = defect_reversible 2.547142e-15 7.911300
## sexe = homme 4.235184e-05 4.094260
## n_vasos_sanguineos = 2 4,952918e-05 4.057838
## n_vasos_sanguineos = 3 9,157912e-05 3.911883
## default_type = fixed_defect 1.073890e-04 3.873260
## n_vasos_sanguineos = 1 4,649990e-03 2.830331
## electro_reposto = hypertrophy_izq 2.225498e-02 2.285988
## electro_repost = anomalie_st 3.297443e-02 2.132394
## pente_s_st = négatif 4,472770e-02 2.007206
Nous allons maintenant voir la relation entre les variables quantitatives et les deux clusters. Les variables les plus représentatives sont celles avec le v.test le plus élevé (en valeur absolue) et en regardant la différence entre «Moyenne dans la catégorie» et «Moyenne globale», nous pouvons avoir une idée des valeurs que les individus dans un cluster prennent sur ces variables.
## $«1»
## v.test Moyenne dans la catégorie Sd moyenne globale dans la catégorie
## beats_minute 10.133353 161.3313609 149.597973 16.6608075
## p_sanguinea_mmHg -3.346967 128.6508876 131.648649 16.2372212
## âge -6.575012 51.5147929 54.513514 8.9085469
## s_st -9.798909 0.4757396 1.051351 0.6908983
##
## $«2»
## v.test Moyenne dans la catégorie Sd moyenne globale dans la catégorie
## s_st 9.798909 1.817323 1.051351 1.222434
## âge 6.575012 58.503937 54.513514 7.537699
## p_sanguinea_mmHg 3.346967 135.637795 131.648649 18.848618
## beats_minute -10.133353 133.984252 149.597973 20.744028
Donc, vous pouvez voir que les individus qui composent le premier cluster sont définis en ayant des valeurs élevées dans beats_minute (par rapport à la moyenne), faible en âge, p_sanguinea et s_st. Nous pouvons également voir comment les individus du cluster 1, c'est-à-dire les cas qui n'ont pas souffert d'un problème cardiaque, Elles sont des femmes, dont la douleur thoracique n'est pas une angine de poitrine atypique ou une angine de poitrine et non causée par l'exercice. En outre, ton electro au repos est normal, sa valeur après le test avec Thalium est normale et son n_vasos_sanguíneos est 0.
De l'autre côté, les individus de la deuxième grappe sont majoritairement des hommes, dont la pression artérielle est supérieure à la moyenne, dont les battements par minute sont inférieurs à la moyenne et dont s_st est supérieur à la moyenne. Ils se distinguent également par leur pente plate_st, quelques valeurs de 1, 2 le 3 dans n_vasos_sanguíneos, dont l'angine est causée par l'exercice, sa douleur est asymptomatique et sa valeur après le test Thalium est réversible ou fixe. Enfin, ses valeurs électro au repos sont l'hypertrophie ou l'anomalie_st.
4.4 Discussion des résultats
Comme vous pouvez voir les variables qui caractérisent le plus les clusters et par conséquent, aussi si une personne a un problème cardiaque ou non, sont les variables qui ont le plus contribué aux première et deuxième dimensions du FAMD faites précédemment. En outre, on voit que les conclusions obtenues ont du sens; ceux qui ont souffert d'un problème cardiaque (appartenant au cluster 2) avoir une fréquence cardiaque maximale par minute très faible, un âge avancé, Ce sont des garçons, pression artérielle supérieure à la normale, une douleur thoracique asymptomatique ... tous ces facteurs sont des facteurs de risque de problèmes cardiovasculaires.
5. Une analyse 3: PLS-DA
La régression des moindres carrés partiels ou la régression des moindres carrés partiels (Régression PLS) c'est une méthode statistique liée à la régression des composantes principales, au lieu de trouver des hyperplans à variance maximale entre la variable de réponse et les variables indépendantes, une régression linéaire est trouvée en projetant les variables de prédiction et les variables observables dans un nouvel espace. Parce que les données X et Y sont projetées dans de nouveaux espaces, la famille de modèles PLS est connue sous le nom de facteur de modèle bilinéaire. Dans notre cas, nous utiliserons l'analyse discriminante des moindres carrés partiels (PLS-DA) qui sont une variante utilisée lorsque le Y est binaire.
5.1 Objectifs
Il y a deux objectifs lors de l'exécution du PLS-DA:
La première consiste à comparer les résultats obtenus dans le FAMD à l'aide des graphiques de scores et de charges et à voir si le même résultat peut être interprété. Également à travers le graphique de diagnostic d'observation, nous pouvons observer l'existence ou non de données extrêmes.
Le deuxième objectif est d'évaluer la capacité prédictive du modèle PLS-DA avec les données, qui seront séparés en données d'entraînement et données de test. Cela servira à voir s'il est possible de prédire de nouveaux cas de problèmes cardiaques avec les variables disponibles..
5.2 Application de la méthode
Pour l’application de la méthode, un pré-processus différent des variables «indépendantes» qui formeront notre matrice X a été utilisé, car la fonction opls a besoin que toutes les colonnes de la matrice X soient de type "numérique" (code disponible en annexe)
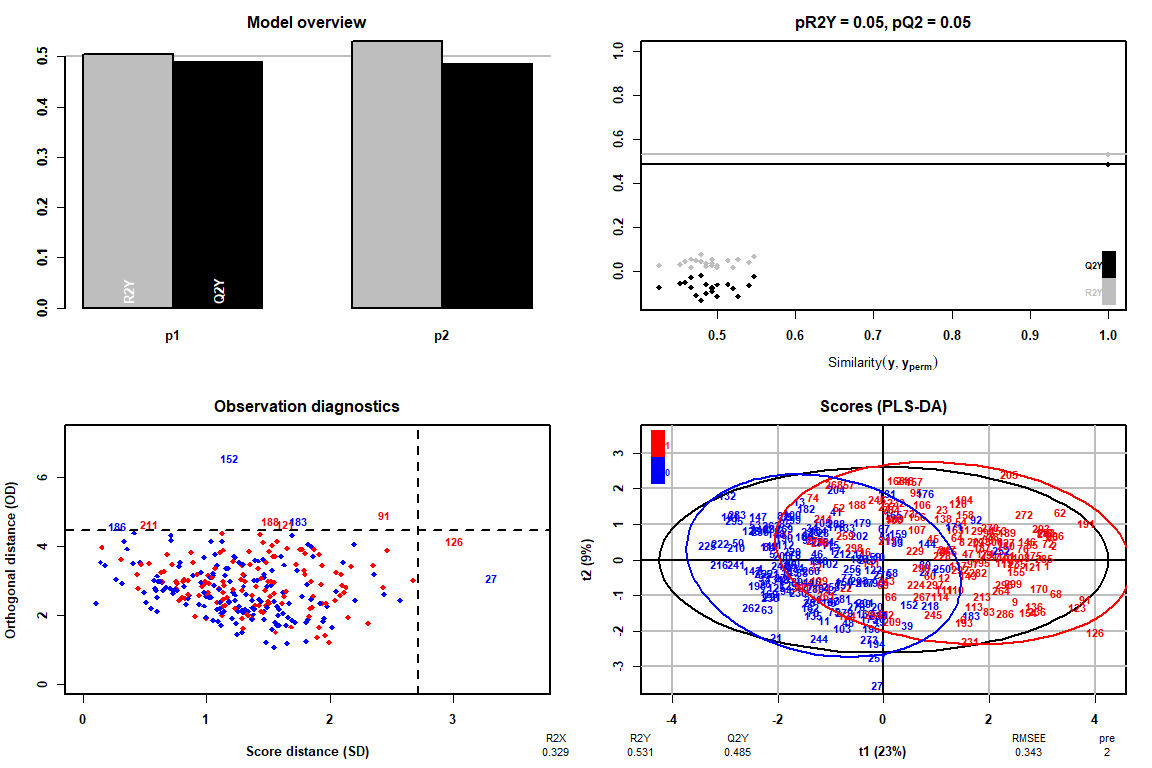
Comment l'observer grâce au tableau de diagnostic d'observation, il n'y a pas de valeurs extrêmes, on peut donc continuer l'analyse du PLS-DA sans avoir à supprimer aucune valeur.
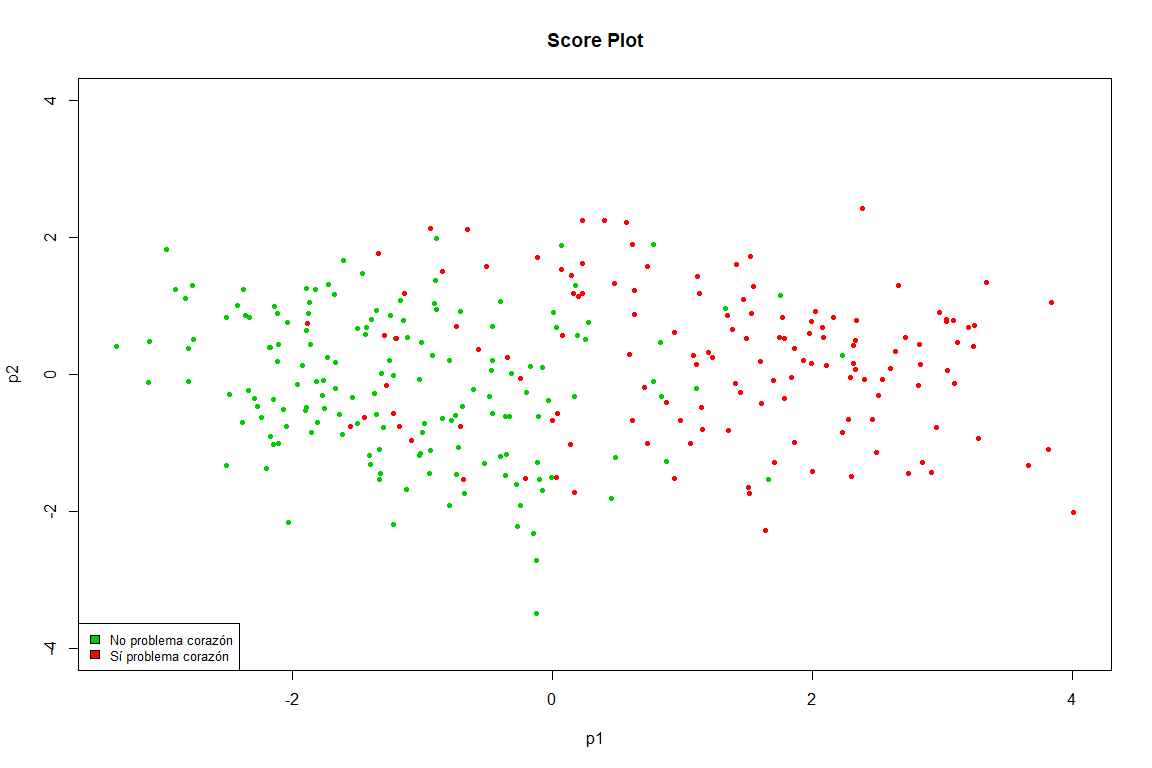
Ce graphique est pratiquement une copie de celui obtenu dans le FAMD, on voit avec quelle clarté les points sont séparés en deux groupes (problème cardiaque et non problème cardiaque)
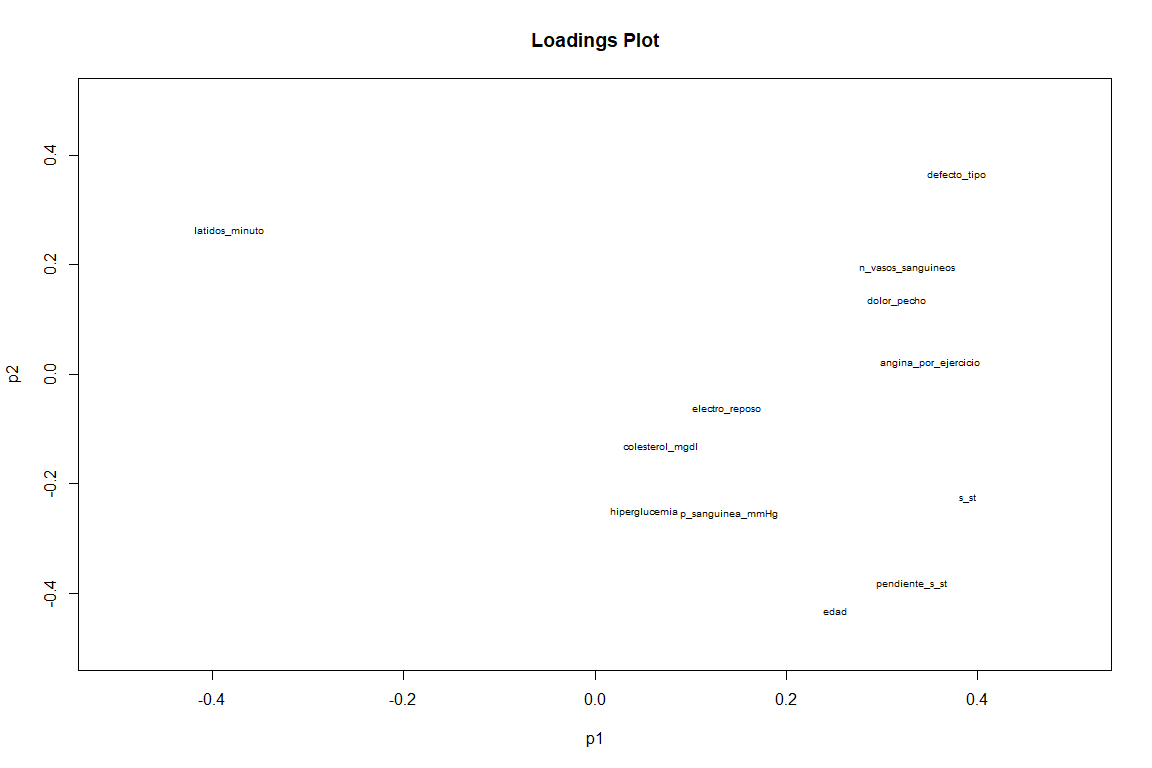
Sur le graphique des charges, si nous voyons un résultat quelque peu différent du graphique des chargements FAMD. Nous voyons comme des variables comme pente_s_st, default_type et minute_beats (bien que cela avec une valeur négative ) ont une grande contribution aux deux composants. Alors que des variables telles que angina_por_exercicio et pain_chest contribuent avant tout au premier composant.
Nous passons maintenant à analyser la capacité prédictive du pls-da à l'aide de données d'entraînement et de données de test.
mypred = prédire(myplsda)
confuTrain = table(trainData$problem_heart, mypred)
confusionMatrix(confuTrain)
## Matrice de confusion et statistiques
## mypred Précision : 0.8487
## 0 1 Kappa : 0.6946
## 0 113 15
## 1 21 89 Précision équilibrée : 0.8495
Comment pouvons-nous voir le modèle prédire ses propres lignes, Il a une précision de 0.85, très bon rapport qualité / prix soutenu par un kappa 0.7, qui indique un bon accord de nos données. (https://es.wikipedia.org/wiki/Coeficiente_kappa_de_Cohen)
La prochaine chose est d'essayer de prédire des données que le PLS-DA n'a jamais «vues»
mypred = prédire(myplsda, données de test[,–14])
confuTest = table(données de test$problem_heart, mypred)
confusionMatrix(confuTest)
## Matrice de confusion et statistiques
## mypred Précision : 0.8448
## 0 1
## 0 28 3 Kappa : 0.6859
## 1 6 21 Précision équilibrée : 0.8493
Le modèle a des valeurs similaires (précision y kappa) pour des données que vous n'avez jamais vues, avec lequel on peut conclure que ce modèle, Prédit assez bien si un nouveau cas va avoir un problème cardiaque ou non avec une probabilité d'environ 84% (Précision 0.84)
5.4 Discussion des résultats
Vous pouvez voir comment PLS-DA est une très bonne méthode pour prédire les nouveaux cas de problèmes cardiaques chez les patients, cependant, Il convient de noter que l’étude comprenait quelques 300 patients environ, il faudrait donc augmenter le nombre d'individus pour voir si ce modèle PLS-DA prédit vraiment avec une telle certitude (84%) si un patient aura un problème cardiaque ou non. D'un autre côté, La matrice des scores et la matrice des chargements ont été étudiées en deux composantes. (le plus significatif) et les différences avec les résultats du FAMD ont été étudiées.
6. Conclusions
6.1 Méthodes comparatives utilisées
Dans ce travail, trois méthodes ont été utilisées: FAMD, Clustering hiérarchique et PLS-DA.
Le FAMD et le clustering ont vu pratiquement les mêmes résultats (informations trouvées dans la section des conclusions de la méthode respective) cela a du sens puisque les coordonnées des individus dans les six premiers composants principaux ont été utilisées pour effectuer le regroupement hiérarchique, donc le FAMD nous a servi de prétraitement des données (pour le clustering) et aussi comme une première analyse des relations entre les variables et les individus dans notre base de données. En regroupant, nous avons confirmé ces premières observations que nous avons faites sur l'existence de deux groupes et les variables qui les influencent.. Le PLS-DA, bien qu'il ait également été utilisé pour comparer les résultats avec ceux du FAMD en raison de la similitude possible entre les graphiques des scores et des charges., Il a été principalement utilisé pour évaluer la capacité prédictive du modèle avec nos données.. Découvrir ainsi la grande capacité prédictive du modèle avec une précision de 85% dans des données que je n'ai jamais vues (données de test).
6.2 Discussion sur les méthodes non appliquées
Les méthodes qui n'ont pas été utilisées dans ce travail sont: Règles d'association, Analyse discriminante.
En premier lieu, les règles d'association ne sont pas utilisées car nous considérons qu'elles ne correspondent pas à notre base de données (nos variables ne sont pas qualitatives et le fait de transformer toutes les variables aurait signifié une perte importante d'informations). En échange, le clustering et la possibilité de pouvoir effectivement observer les clusters dans lesquels notre base de données était séparée nous paraissaient une option bien plus intéressante.
Concernant l'analyse discriminante, Il est vrai que cela aurait été une option très intéressante puisque précisément notre intention dès le premier instant est de voir les variables les plus liées à un problème cardiaque ou non., pour ensuite prédire les cas futurs ou classer les individus que nous avions déjà. Cependant, l'utilisation du PLS ou du PLS-DA était obligatoire et les analyses FAMD et clustering avaient déjà été effectuées, qui sont considérées comme plus pertinentes dans ce cas que l'analyse discriminante, il a donc été décidé de s'en passer.
Finalement, le choix entre PLS et PLS-DA est évident puisque l'intention a toujours été d'étudier la relation entre le problème cardiaque et les autres variables, donc la meilleure option dans ce cas est de choisir PLS-DA, en utilisant comme Y le problème cardiaque et comme X le reste des variables pour étudier la relation entre elles et la capacité de prédire.
7 Autres thèmes
7.1 Commentaires sur les articles lus
L'idée de supprimer à la fois FAMD et le clustering hiérarchique (ainsi que l'utilisation de la matrice de score pour le regroupement hiérarchique) ha surgido del libro «Guide pratique des méthodes des composants principaux en R (Kassambara)‘Y del libro‘ Analyse exploratoire multivariée par exemple utilisant R (Chapman & Hall / CRC Informatique & L'analyse des données)’ de Francois Husson. Nous pensons que c'est un outil très puissant pour combiner les deux techniques (FAMD et clustering) depuis le premier, nous permet de supprimer le bruit de nos données, et deuxieme, en utilisant FAMD comme prétraité, nous pouvons utiliser des «données mixtes» dans le clustering, ce qui nous apporte un grand avantage.
8. Annexe:
8.1 Blibliographie
- HCPC I
- FAMD I
- Informations sur le segment ST en attente
- «Guide pratique des principales méthodes des composants en R (Kassambara)»
- «Analyse multivariée exploratoire par exemple utilisant R (Chapman & Hall / CRC Informatique & L'analyse des données)’ de Francois Husson
- Documentation de FactoMineR
- Modifications du cœur et des vaisseaux sanguins dues au vieillissement
- Battements maximum par minute
- Facteurs de risque de problèmes cardiovasculaires
- Données utilisées
8.2 Analyse de distribution variable
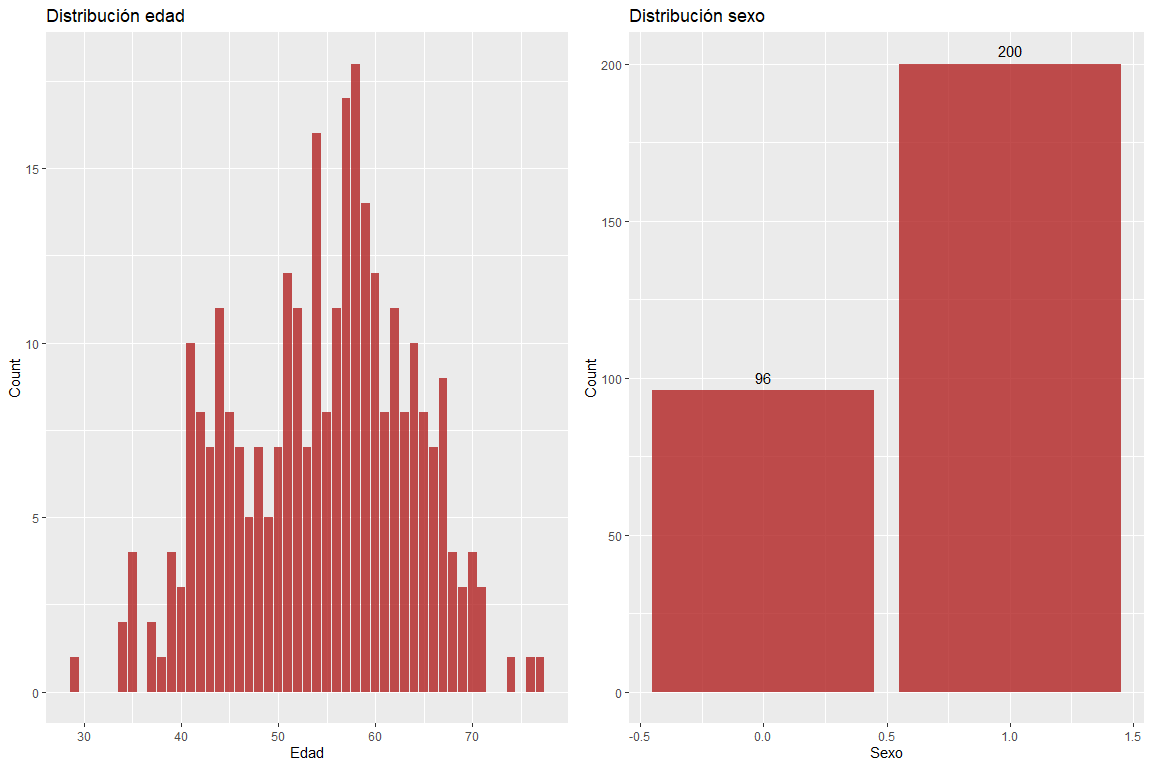
La variable d'âge ne prend pas de valeurs extrêmes et la variable sexe ne contient pas de valeurs erronées.
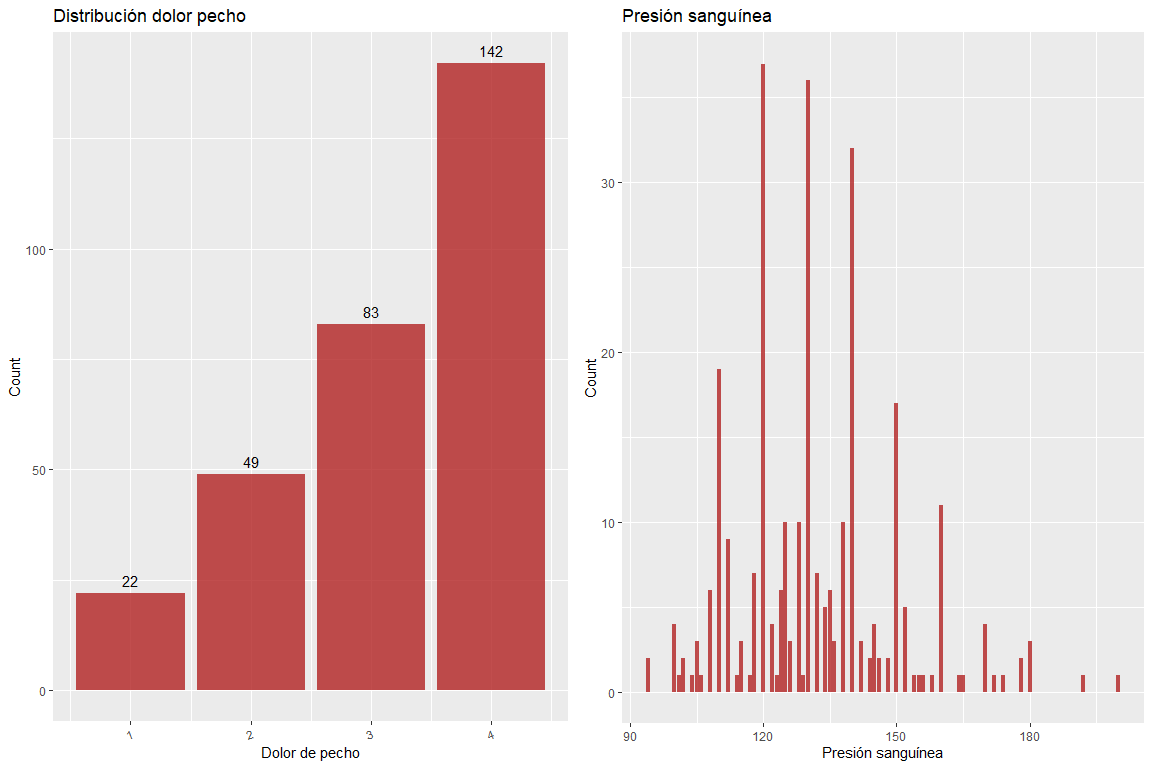
La douleur thoracique variable ne contient pas de mauvaises valeurs, tout comme la tension artérielle variable.
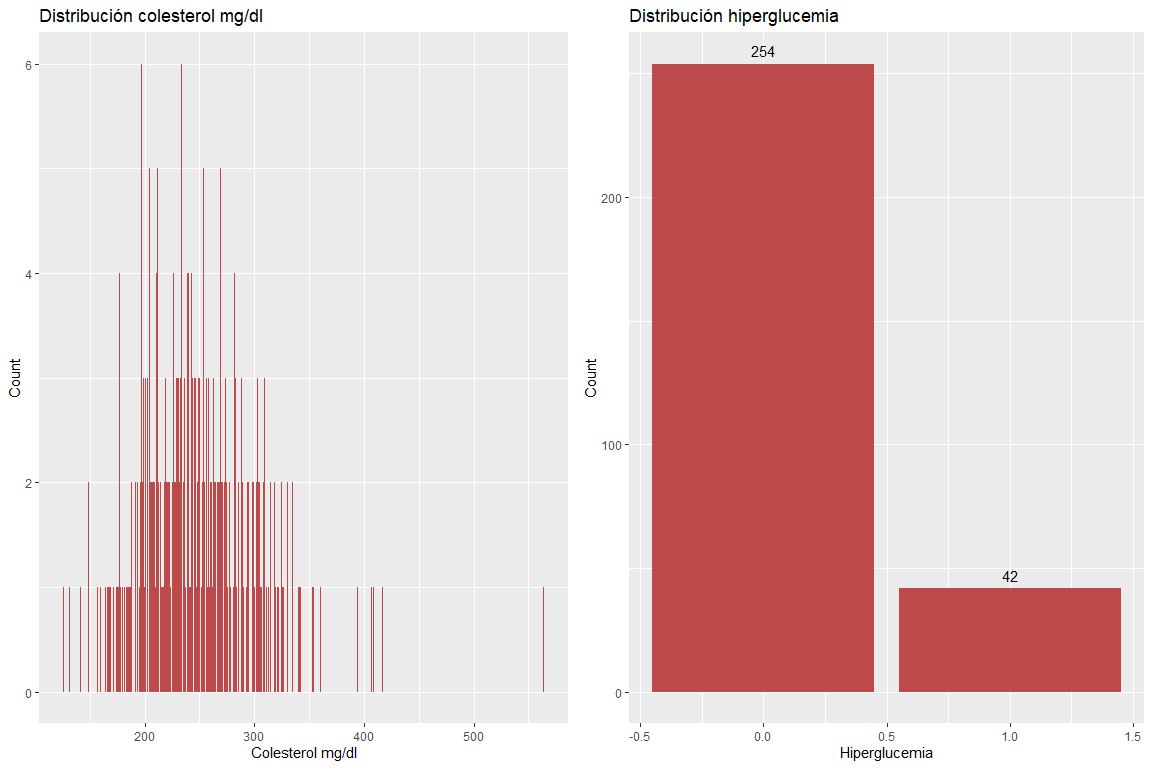
Les deux variables Cholestérol mg / dl et hyperglycémie ne prennent pas de mauvaises valeurs.
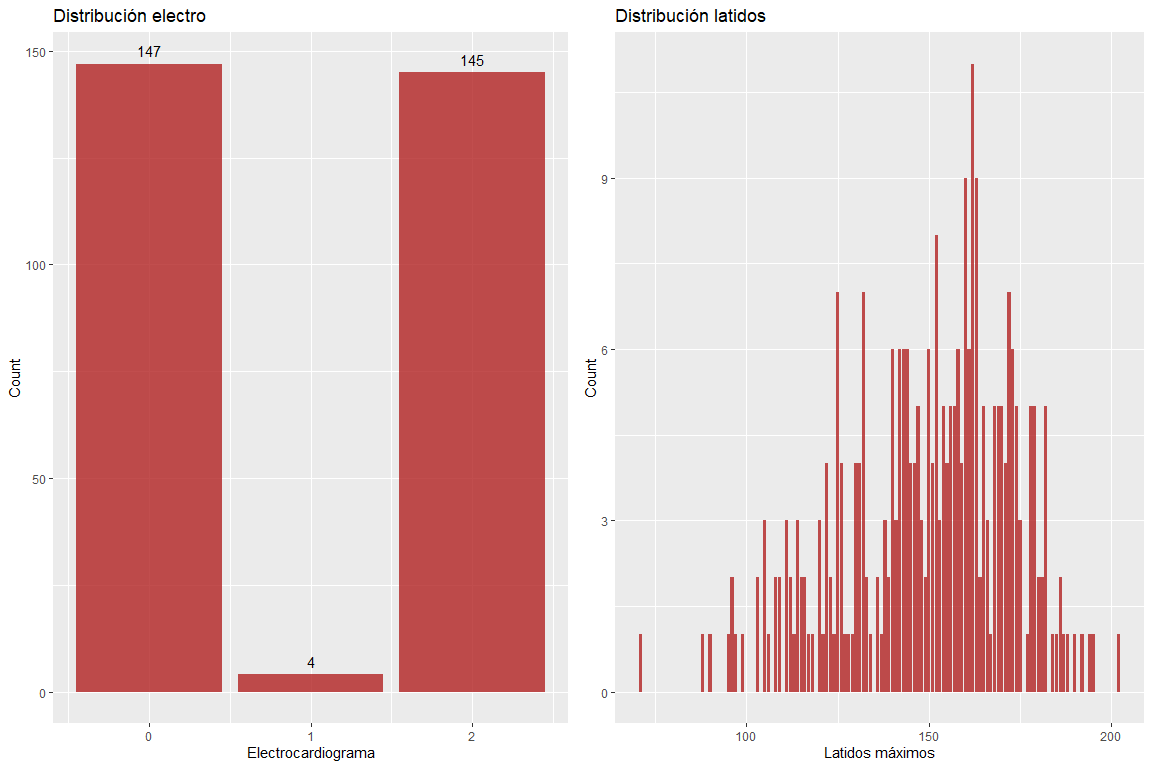
Les deux variables résultats de l'électrocardiogramme et battements maximum par minute ne prennent pas de mauvaises valeurs.. Cependant, il faut souligner qu'il existe des valeurs assez élevées pour l'âge des patients. (selon la formule de Haskell & Renard, Dont l'utilisation est largement utilisée pour délimiter les pulsations maximales en fonction de l'âge).
Les deux variables exercent l'angine de poitrine et la dépression du segment ST n'ont pas de valeurs erronées.. Mais il faut souligner qu'il existe des observations avec une valeur de dépression du segment ST très élevée.
Les deux variables en attente du segment ST et du nombre de vaisseaux sanguins n'ont pas de valeurs erronées.
Les deux variables type de défaut et problème cardiaque n'ont pas de valeurs erronées.