Применение статистических и прогностических методов (PCA, кластеризация у PLS-DA) на данных о вине, чтобы получить, какие факторы влияют больше всего при создании хорошего вина.
Микель Марин Коломе & Альваро Мазкунан Эррерос
1 — ОПИСАНИЕ ИССЛЕДОВАНИЯ И БАЗЫ ДАННЫХ
1.1 — ОПИСАНИЕ ИССЛЕДОВАНИЯ
Следующая работа связана с базой данных, касающейся разновидности красного и белого вина португальского 'Vinho Verde'. Сертификация вина включает физико-химические тесты, такие как, определение плотности, pH, количество алкоголя, и т.д. С этим проектом, Вы хотите изучить те переменные, которые влияют больше всего при анализе качества вина, Если плохо, хорошо / удовлетворительно или очень хорошо.
1.2 — ОПИСАНИЕ БАЗЫ ДАННЫХ
База данных состоит из 12 переменные и 4858 наблюдения. Большинство переменных являются физико-химическими компонентами, которые используются для изготовления вин. Эти переменные следующие:
- Фиксированная кислотность
- Летучая кислотность
- Лимонная кислота
- Остаточный сахар
- Хлориды
- Свободный диоксид серы
- Общая двуокись серы
- плотность
- pH
- Сульфаты
- Алкоголь
Эти переменные, указанные выше, являются непрерывными. Отдельно, доступна «цель» или переменная ответа. Эта переменная соответствует рейтингу вина и имеет дискретный тип. Взять значения из 0 а 10.
2 — ПЕРВОНАЧАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ И ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
2.1 — ОТСУТСТВУЮЩИЕ ДАННЫЕ
Первый, прежде всего, он исследует, есть ли пропущенные значения в файле данных. Это проверяется с помощью следующей функции, и наблюдается, что нет значения этого типа.
## [1] 0
2.2 — ТРАНСФОРМАЦИЯ ПЕРЕМЕННЫХ
Одним из преобразований, которое было проведено, было изменение качества вина.. Как вы видете, Есть несколько значений для этих наблюдений, которые они принимают 3, 4, 8 В 9.
## 3 4 5 6 7 8 9
## 20 163 1447 2178 870 175 5
таким образом, Было решено сгруппировать значения, которые принимает эта переменная 3 отдельные группы:
- группа 1: Вина с оценкой 3 В 4. Они будут считаться «плохими» винами
- группа 2: Вина с оценкой между 5 и 7. Они будут считаться "хорошими" винами
- группа 3: Вина с оценкой 8 В 9. «Очень хорошие» вина будут считаться
2.3 — ПЕРЕМЕННЫЕ И / ИЛИ ОТКАЗАННЫЕ ЗАПИСИ
Предыдущее исследование базы данных было сделано, и было решено не исключать ни одной из переменных с, С одной стороны, все они важны и, для других, имея только 12, удаление одного из них может привести к потере информации при проведении исследования.
2.4 — РАСПРЕДЕЛЕНИЕ ПЕРЕМЕННЫХ
затем, каждая из доступных переменных будет наблюдаться, учиться, если он существует, априори, некоторые аномальные или экстремальные данные в них.
В В приложении 8.3: Анализ распределения переменных все объясняется более подробно, анализируя наличие нормальности или асимметрии в данных, в дополнение к коэффициенту Куртоза.
Априори, аномальных данных не наблюдается. Как единственная деталь, на графике плотности видно, что все наблюдения принимают значения около 1.
Вот некоторые из значений плотности некоторых вин.
- Белое сухое вино: 0,9880-0,9930 г / мл.
- Красное сухое вино: 0,9910-0,9950 г / мл.
- Игристое вино: 0,9890-1,0080 г / мл.
- Ликерное вино (Moscatel): 1,0500-1,0700 г / мл.
таким образом, это нормальное значение.
2.5 Масштабирование и центрирование данных
После проведения небольшого поискового анализа данных в этом файле, он уже передан в часть предварительной обработки, важная часть перед проведением соответствующих анализов.
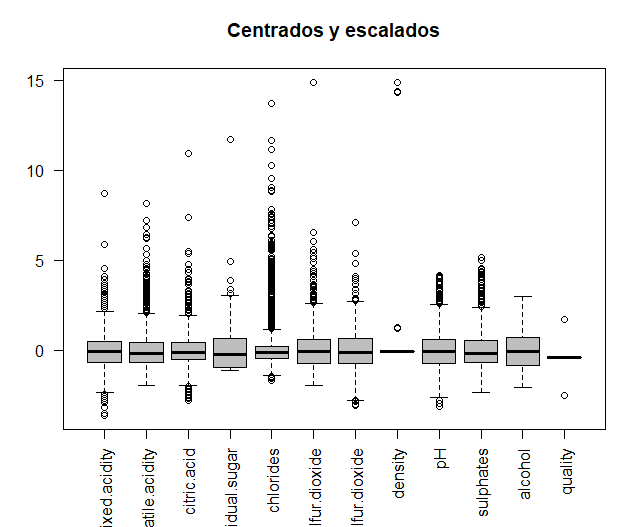
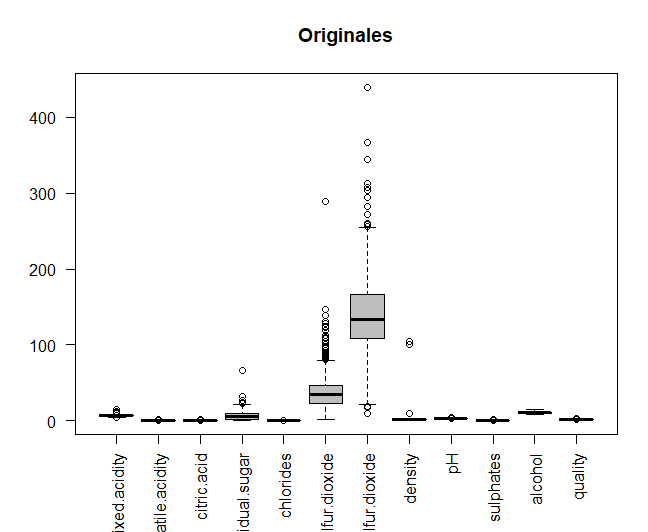
Исходные данные будут сравниваться с данными после центрирования и масштабирования., для того, чтобы увидеть, если переменные измеряются на разных величинах. Данные центрированы и масштабированы.
затем, два графика, которые делают сравнение, печатаются в одном окне, используя функцию крутящего момента. Видно, как некоторые переменные измеряются при разных величинах, например, два типа серы. таким образом, для дальнейшего анализа, центрированные и масштабированные данные будут использованы.
3. АНАЛИЗ 1 — АНАЛИЗ ГЛАВНЫХ КОМПОНЕНТОВ (PCA)
После проведения поискового анализа и центрирования и масштабирования данных, Вы можете перейти к первому из трех анализов, которые будут проведены в этом проекте предмета. Первый из них, как видно из названия, является основным компонентом анализа. Полезность этого метода двояка:
- Оптимально визуализировать в небольшом пространстве, наблюдения p-мерного общего пространства. Это первый шаг для определения возможных «скрытых» или ненаблюдаемых переменных, которые генерируют изменчивость данных.
- Позволяет преобразовать исходные переменные, вообще коррелированный, в новых некоррелированных переменных, облегчение интерпретации данных.
3.1 ЦЕЛИ
Цель при использовании этого метода будет состоять в том, чтобы получить переменные, которые больше всего влияют на измерения, которые объясняют наибольшую изменчивость. Используя этот метод, можно будет получить более конкретное представление о том, как ведут себя обрабатываемые данные. Отдельно, небольшое исследование будет проведено на некоторых винах, которые имеют экстремальные данные.
3.2 ПРИМЕНЕНИЕ МЕТОДА / ЧИСЛЕННЫЕ И ГРАФИЧЕСКИЕ РЕЗУЛЬТАТЫ
Осыпь-ГРАФИК
Уже передано применение метода. Все это делается через функцию PCA, уже реализованную в R. Данные не масштабируются, потому что это уже было сделано ранее.
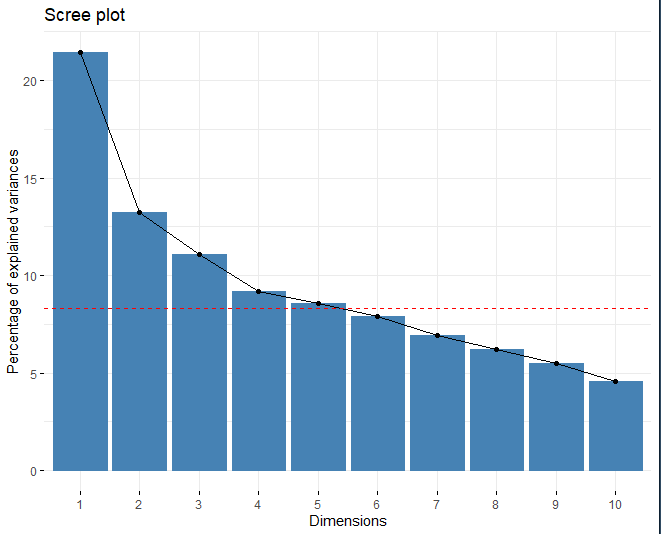
## Собственное значение дисперсия.процент кумулятивный.вариант.процент
## Dim.1 2.571633 21.434687 21.43469
## Dim.2 1.585109 13.211958 34.64665
## Dim.3 1.330253 11.087723 45.73437
## Dim.4 1.102265 9.187435 54.92180
## Dim.5 1.029659 8.582255 63.50406
Метод применяется и наблюдается, как идеальное количество основных компонентов 5. С одной стороны, используя осыпь, красная линия врезается в пятое измерение. С другой стороны, Другой метод выбора подходящего числа измерений состоит в том, чтобы получить те компоненты, которые имеют собственное значение больше 1. Также, Получив таблицу с указанным собственным значением, соответствующим каждому из измерений, можно видеть, что, из пятого компонента, собственное значение больше чем 1.
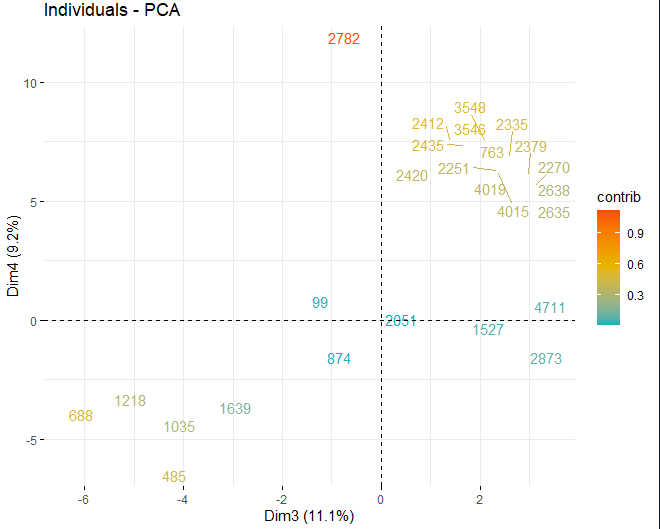
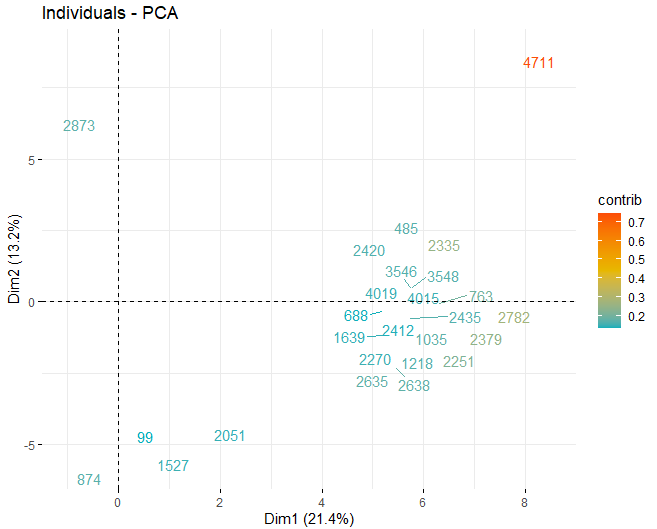
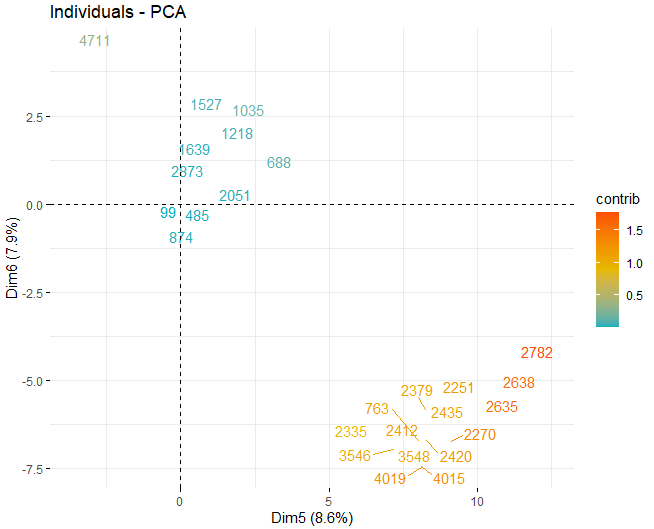
SCORE-ГРАФИК
затем, получен оценочный график с оценками вин в каждом из измерений, которые были получены ранее. Эти вина окрашены их вкладом в компоненты.
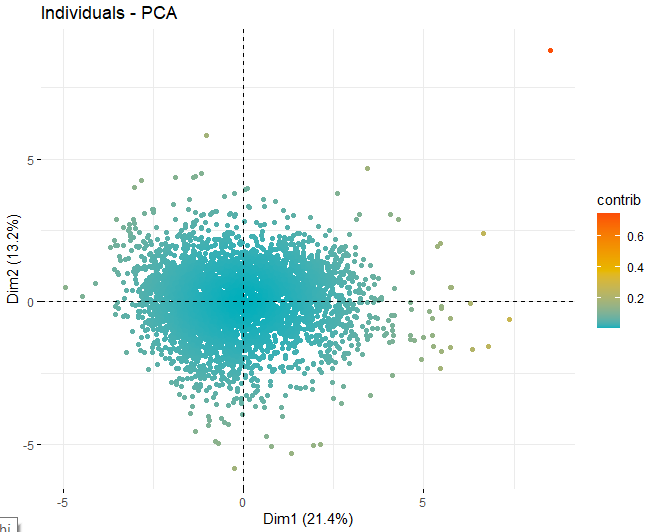
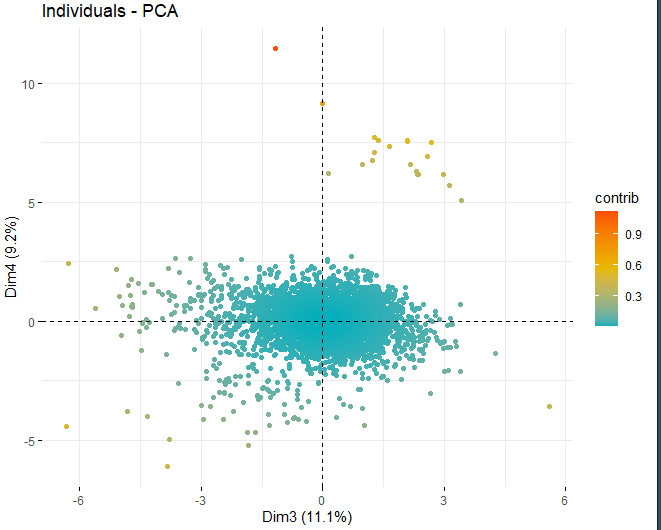
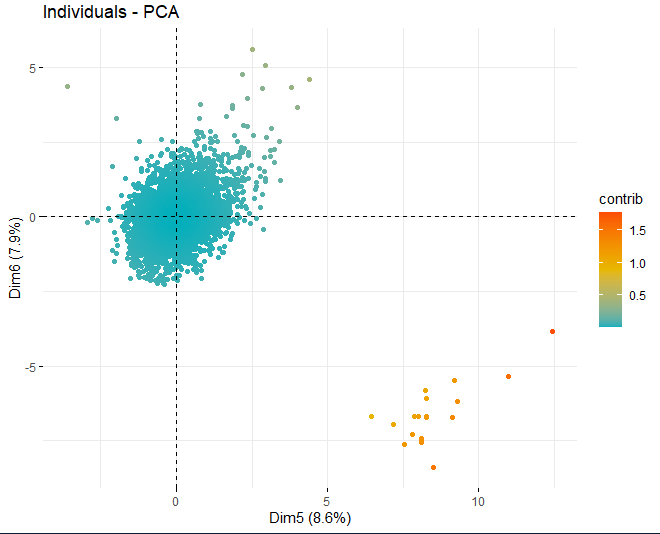
Можно увидеть, как есть некоторые аномальные значения в разных компонентах, кроме нескольких экстремальных наблюдений, которые побили счет, в абсолютном значении, лучше чем 5 и даже из 10. Для того, чтобы получить больше информации о том, что эти аномальные наблюдения, они продолжают получать те же графики, как и раньше, но, в таком случае, только с наблюдениями, которые превышают оценку, в абсолютном значении, из 5.
T2 ГОСТИНИЦА
Некоторые наблюдения, конкретно вина 4711, 2782 В 2635, у них очень экстремальные ценности, которые, если они остались в базе данных, может исказить выводы будущих анализов. Конкретный, Любые наблюдения, которые превышают предел 99% используя Hotelling's T2.
затем, Вы можете увидеть некоторые из вин, которые превышают этот предел.
Замечено, что есть, конкретный, в общей сложности 156 наблюдения, которые превышают 99%. 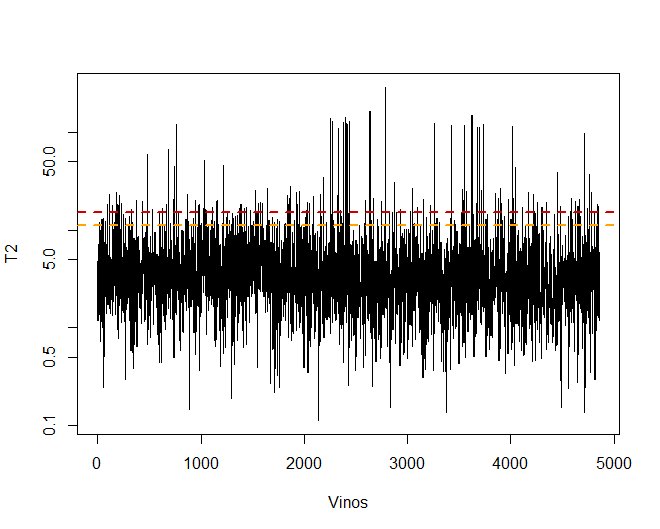
## [1] 156
таким образом, для лучшего анализа, эти вина устранены.
## [1] 4702 12
затем, вспомогательная переменная создается для хранения в ней переменной качества, для использования в следующем анализе окраски.
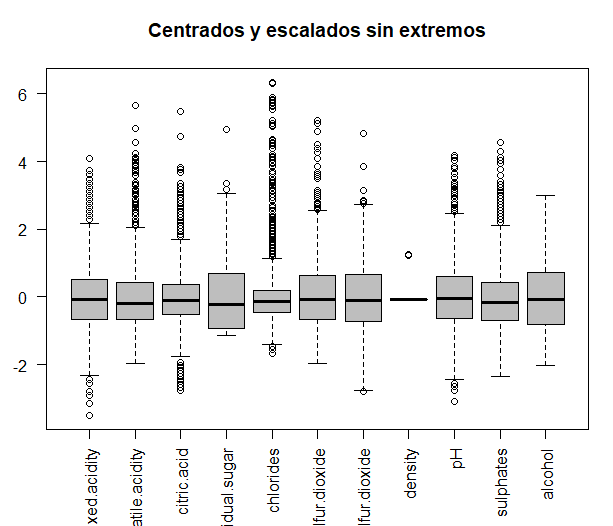
В таком случае, наблюдая ось ‘и’ коробок, удаление предыдущих значений, экстремальные ценности больше не существуют. 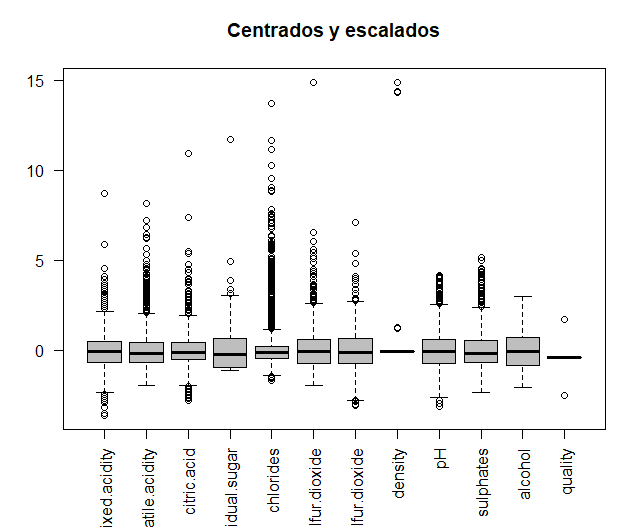
Теперь СПС придется сделать снова, с новыми наблюдениями. В таком случае, следуя тем же критериям, что и раньше (используя график осадки и собственные значения каждого из измерений), получены 3 основные компоненты, так как они имеют собственное значение больше 1.
## Собственное значение дисперсия.процент кумулятивный.вариант.процент
## Dim.1 2.3094622 26.079639 26.07964
## Dim.2 1.4442754 16.309503 42.38914
## Dim.3 1.0534806 11.896446 54.28559
## Dim.4 0.8526690 9.628779 63.91437
## Dim.5 0.8060166 9.101956 73.01632
Погрузочно-ГРАФИК
Как только соответствующие размеры были получены, загрузочные площадки каждого из размеров, которые были получены ранее, получены: 
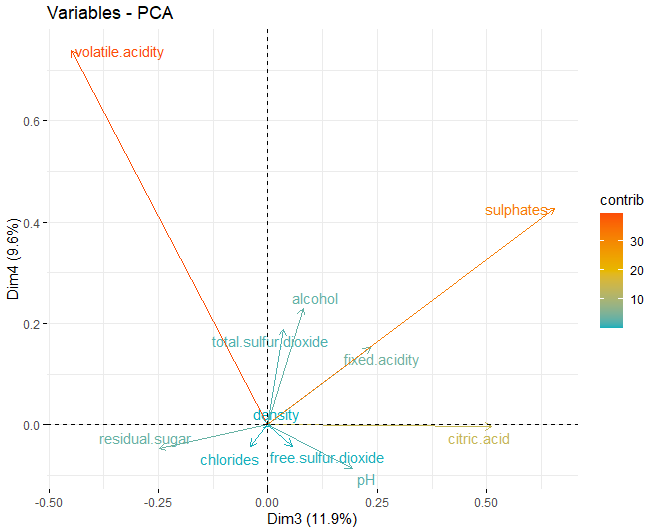
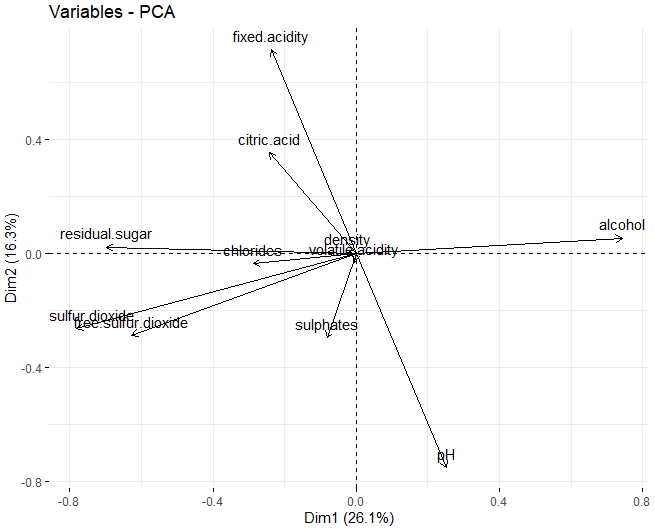
В этом случае видно, что, в первом измерении, переменные, которые больше всего влияют на эти измерения, являются физико-химическими компонентами, остаточный сахар и два типа серы, как бесплатно, так и полностью. С другой стороны, во втором измерении, те, которые больше всего влияют на pH и фиксированную кислотность.
3.3 ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
В этой первой цели было отмечено, что необходимо провести более одного анализа PCA из-за аномальных наблюдений, которые могут появиться с использованием Hotelling T2.. Если эти результаты были проигнорированы, вероятно, графики оценок и нагрузок не будут интерпретироваться одинаково, и будут получены результаты, которые не будут полностью реальными.
Помимо этого, используя эту технику, удалось получить более подробное представление о базе данных, которая обрабатывается, анализ переменных, которые больше всего влияют на создание измерений. Было замечено, что это алкоголь, остаточный сахар и два типа серы, свободная сера и общее количество.
4. АНАЛИЗ 2 — КЛАСТЕРИЗАЦИЯ
4.1 ЦЕЛИ
Вторым анализом, который будет проводиться в этом проекте, будет анализ конгломератов или кластерный анализ.. Цель применения этого метода, в частности, состоит в том, чтобы определить, какие характеристики являются наиболее важными при оценке качества вина с использованием методов иерархической кластеризации и алгоритмов разделения.. С точки зрения этой базы данных, цель состоит в том, чтобы получить те химические переменные, которые влияют на значение, которое переменная ответа в конечном итоге принимает, то есть, переменное качество.
в заключение, Вы получите цветной график качества, учиться, если на самом деле, кластеры, которые образуют эти переменные, они хорошо отделены или нет.
4.2 ПРИМЕНЕНИЕ МЕТОДА — ЧИСЛЕННЫЕ РЕЗУЛЬТАТЫ
4.2.1 Группировка данных — ХОПКИНС СТАТИСТИКА
Прежде всего, до применения указанного способа, Вы должны изучить, есть ли группировка в обрабатываемых данных. Это можно сделать с помощью коэффициента Хопкинса. Следует помнить, что чем ближе этот коэффициент 1, больше данных будет существовать в данных.
Функция Хопкинса, уже реализованная в R, используется, но, Ты должен быть осторожен, потому что эта функция получает коэффициент несколько другим способом. Рассчитать статистику в обратном направлении, то есть, реальное значение указанного коэффициента составляет 1-H. таким образом, в таком случае 1-0.08 знак равно 0.92. Посредством чего, можно сказать, что в данных есть большая группировка.
## $ЧАС
## [1] 0.1029338
4.2.2 HCPC — ИЕРАРХИЧЕСКОЕ КЛАСТЕРСТВО НА ОСНОВНЫХ КОМПОНЕНТАХ
HCPC - это алгоритм, который группирует похожих людей в кластеры, но с особенностью, предназначен для работы с результатами метода главных компонент. Этот алгоритм позволяет получить оптимальное количество кластеров, используя технику, основанную на инерции.. В В приложении 8.1: Библиография Ссылка прилагается для получения дополнительной информации об этом.
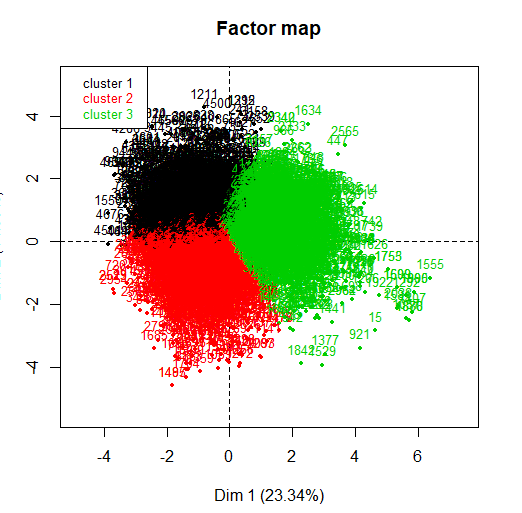
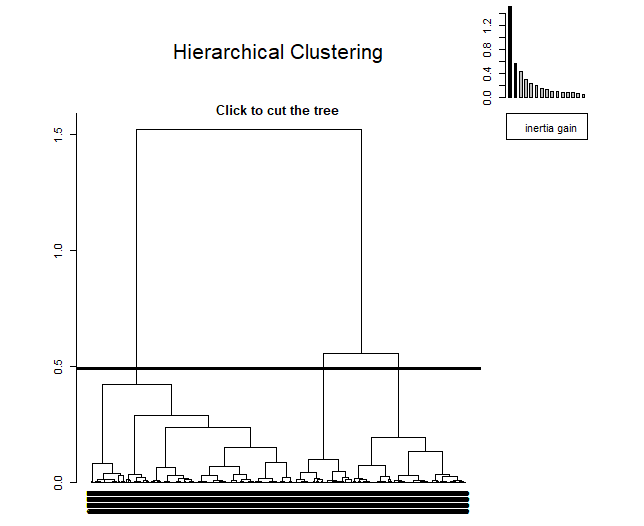
При применении, можно рассматривать как, в правом верхнем углу, появляется маленький график, показывающий инерцию в каждом из измерений. Метод решает взять три кластера, так как, из третьего компонента, инерция сохраняется.
4.2.3 ПОЛУЧЕНИЕ ДИСТАНЦИОННОЙ МАТРИЦЫ
После представления первого метода для получения оптимального количества кластеров, мы продолжаем получать матрицу расстояний, используя евклидово расстояние, так как цель состоит в том, чтобы найти вина с аналогичными характеристиками, потом, изучить, классифицированы ли они как хорошие или плохие.
4.2.4 МЕТОД УОРДА
Первый, Метод Уорда будет использоваться. Первый метод нашел 3 как оптимальное количество кластеров, таким образом, К = 3 будет назначен.
## группах1
## 1 2 3
## 1743 2031 928
Можно заметить, что, используя указанный метод, три сформированные группы кажутся хорошо сгруппированными, нет, казалось бы, аномальных данных.
затем, Методы Elbow и Silhouette будут использоваться для проверки оптимального количества кластеров для метода Уорда.. 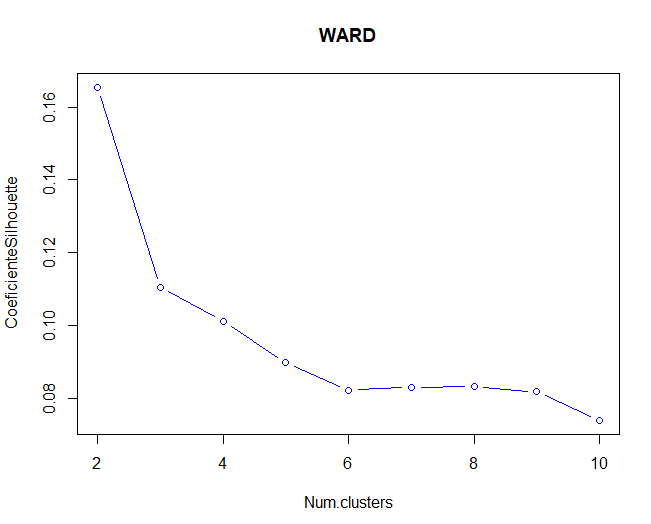
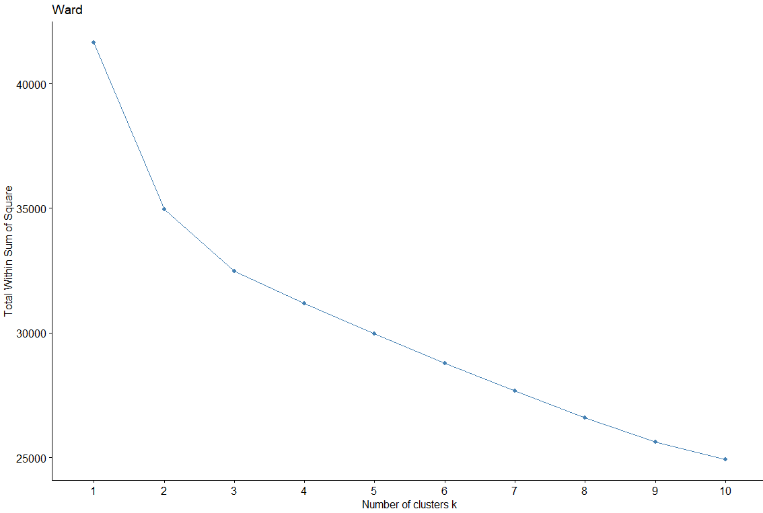
Замечено, что, как для метода силуэта, так и для метода локтя (хотя это не кажется таким ясным), оптимальное количество кластеров будет 2 кластеры. В таком случае, используя два кластера, больше, чем 1000 наблюдения в одной группе относительно другой.
## groups1b
## 1 2
## 1743 2959
4.2.5 K-Means
Далее изучается еще один метод, в этом случае метод Kmeans или Kmedias. Как это было сделано с помощью метода Уорда, К = 3 также будет назначен в этом случае. Хорошая группировка данных также наблюдается с использованием трех кластеров..
##
## 1 2 3
## 1683 1475 1544
Оптимальный метод кластеризации получается с использованием этого метода., также с коэффициентом силуэта и методом локтя. 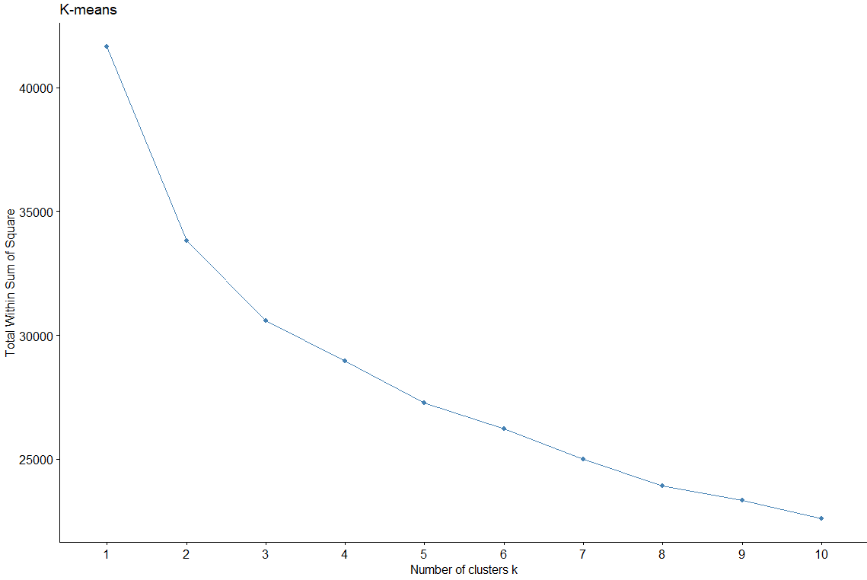
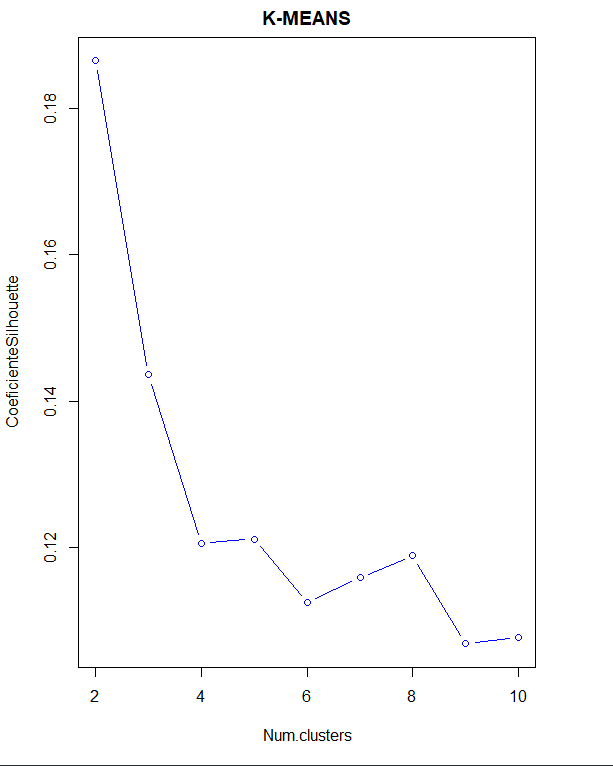
В таком случае, в методе локтя, вы не видите такого определенного локтя. тем не мение, изучение коэффициента силуэта, указывает на то, что количество кластеров 2 очередной раз.
4.3 ОПТИМАЛЬНОЕ ЧИСЛО КЛАСТЕРОВ — ВАЛИДАЦИЯ РЕЗУЛЬТАТОВ
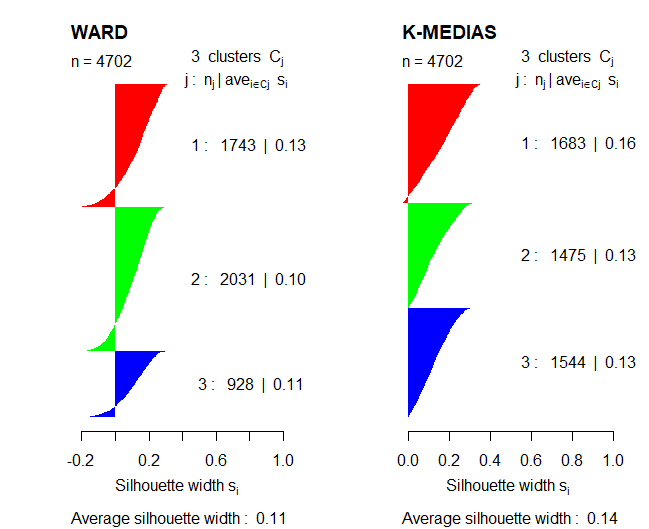
После изучения некоторых методов получения оптимального количества кластеров, эти методы будут сравниваться с использованием коэффициента Силуэт для подтверждения результатов.
Сравнивая два представления, Вы можете сказать метод раздела, алгоритм k-средних, работает лучше, чем иерархический метод Уорда, потому что в этом случае коэффициент Силуэт выше. Также, в случае метода Уорда, появляются несколько наблюдений с отрицательными значениями в используемом коэффициенте.
таким образом, в следующем разделе, интерпретация результатов кластеризации будет изучена с использованием метода K-средних. Также, этот алгоритм будет использоваться с 3 кластеры с, предварительно, было замечено, что с этим значением К, группы были более сбалансированы, нет аномальных значений.
4.4 ГРАФИЧЕСКИЕ РЕЗУЛЬТАТЫ
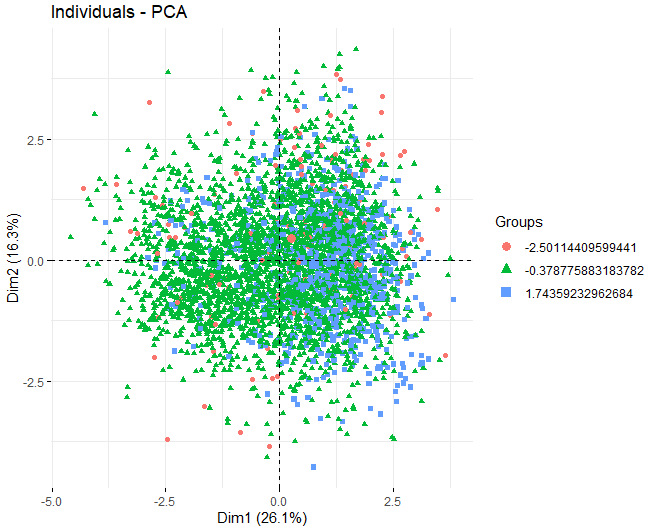
Прокомментировав, что будет использован метод K-средних, мы переходим к получению PCA, чтобы увидеть, какие переменные вносят наибольший вклад в формирование кластеров. В таком случае, Можно заметить, что, используя алгоритм k-средних с 3 кластеры, los 3 группы разделяются очень хорошо, они сбалансированы.
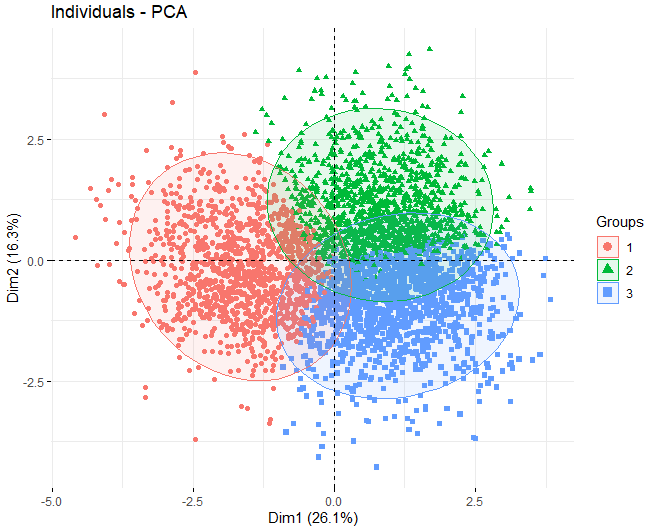
Можно заметить, что, в первых двух измерениях, переменные, которые больше всего влияют на создание кластеров - это остаточный сахар, алкоголь, и два типа серы, как общая сера, так и свободная сера.
в заключение, далее мы покажем график, на котором представлено каждое из вин, чтобы увидеть, влияет ли переменная качества на создание кластеров.. Вы можете видеть, что кластеры не очень хорошо разделены, большинство точек совпадают с другими.
4.5 ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
С помощью этой техники было замечено, что переменная качества не влияет на создание кластеров. Это может быть связано с различными факторами, которые не были учтены при анализе с самого начала.. Кластеры могут быть сформированы в соответствии с другими переменными, такими как, наименование места происхождения товара, тип винограда, который используется для изготовления этих вин, и т.д.
5 АНАЛИЗ 3 — Частичные наименьшие квадраты — ДИСКРИМИНАНТНЫЙ АНАЛИЗ (PLS-DA)
Техника PLS представляет собой сочетание множественной регрессии и PCA.. Имейте в виду, что если есть мультиколлинеарность, регрессия может быть выполнена неправильно, и желаемые результаты могут не появиться. тем не мение, PLS ранее использует PCA, чтобы наблюдать, какие переменные являются наиболее влиятельными при создании изучаемых переменных, и каждый из компонентов ортогонален следующему, который больше всего влияет, и так далее.. По этой причине, благодаря тому, что компоненты линейно независимы друг от друга, регрессия может быть выполнена без каких-либо проблем.
Одним из вариантов PLS является PLS-DA, который будет использоваться в этом проекте, который включает в себя технику дискриминантного анализа. Различия, относительно предшествующего уровня техники, является то, что переменная ответа является категориальной. Из этой категориальной переменной будет создано столько «фиктивных» переменных, сколько есть разных значений, которые может принимать переменная ответа..
5.1 ЦЕЛИ
Цель при использовании этой техники двояка. С одной стороны, изучить возможные аномальные наблюдения (затем, будет объяснено как их лечить). С другой стороны, оценить прогнозирующую способность модели PLS-DA с помощью переменной качества вина.
В первой технике, которая была использована, СПС, было замечено, что, используя Hotelling's T2, появились некоторые наблюдения, которые превысили 99%, учитывая аномальные и экстремальные наблюдения те, которые были самыми дальними от этого разреза. Аналогичная процедура будет проведена в PLS. во-первых, первая модель PLS будет сделана и, используя технику Hotelling T2, возможные аномальные или экстремальные наблюдения будут изучены.
Любые наблюдения, которые превышают предел 99% используя Hotelling's T2, а затем снова будет создана новая модель PLS, чтобы получить более надежную модель, чем в другой с аномальными случаями, которые могут изменить ее характеристики.
5.2 ПРИМЕНЕНИЕ МЕТОДА
Уже передано применение модели. Сначала вы должны преобразовать переменную ответа в фактор, так как, хотя это качественно, программа не определяет его таким образом, так как принимает числовые значения.
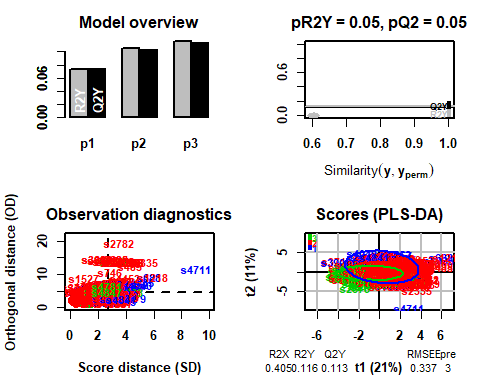
После применения, вы можете увидеть, как модель получает 3 как идеальное количество компонентов.
## PLS-DA
## 4858 образцы х 11 переменные и 1 ответ
## стандартное масштабирование предикторов и ответа(s)
## R2X(сперма) R2Y(сперма) Q2(сперма) RMSEE для орт pR2Y pQ2
## Общее количество 0.405 0.116 0.113 0.337 3 0 0.05 0.05
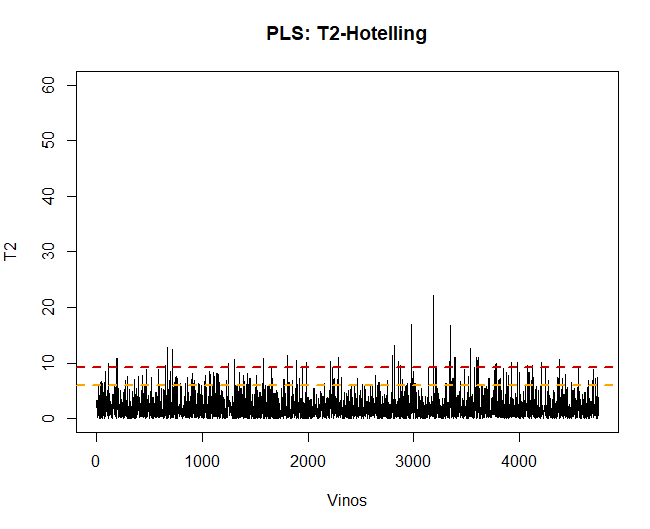
5.2.1 Т2-Хотеллинг
Первое, что нужно сделать, как только модель будет применена, это проверка данных, наблюдать, если есть ненормальные или экстремальные наблюдения, которые могут повлиять на результаты. Для этого, будет составлен график Т2 Хотеллинга и, таким образом, сможет их обнаружить.
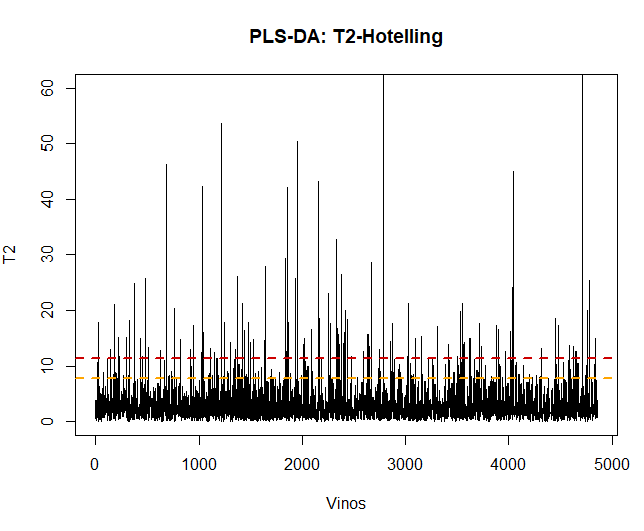
Используя эту технику, Вы можете увидеть, что есть некоторые 100 аномальные наблюдения. Такие данные будут удалены, а модель PLS-DA будет применена повторно..
## [1] 109
5.3 ПРИМЕНЕНИЕ МЕТОДА БЕЗ АНОМАЛЬНЫХ ДАННЫХ
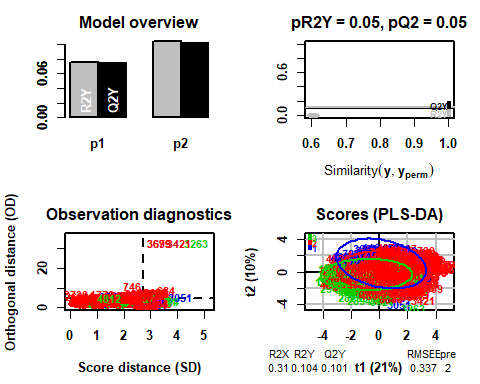
В этом случае вы можете увидеть, что, удаляя предыдущие наблюдения, модель выбирает в этом случае 2
## PLS-DA
## 4749 образцы х 11 переменные и 1 ответ
## стандартное масштабирование предикторов и ответа(s)
## R2X(сперма) R2Y(сперма) Q2(сперма) RMSEE для орт pR2Y pQ2
## Общее количество 0.31 0.104 0.101 0.337 2 0 0.05 0.05
5.3.1 Т2-Хотеллинг
Если теперь отображается график Hotelling T2, Больше нет аномальных данных, которые могут повлиять на модель.
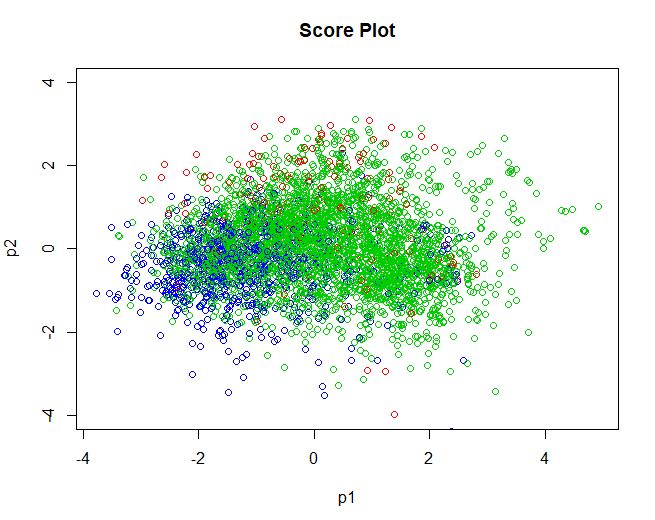
5.3.2 SCORE-ГРАФИК
Как только данные проверены, мы продолжаем получать график оценки, относящиеся к лицам. Результаты, очень похожие на полученные с помощью алгоритма k-средних, используемого в анализе 2. Группы не четко разделены, большинство пересекаются друг с другом. Как уже упоминалось в предыдущем анализе, это может быть потому, что группы не разделены по качеству, но другие переменные, которые в этом анализе не были организованы, такие как обозначение происхождения вина, тип винограда, используемого для его приготовления, и т.д.
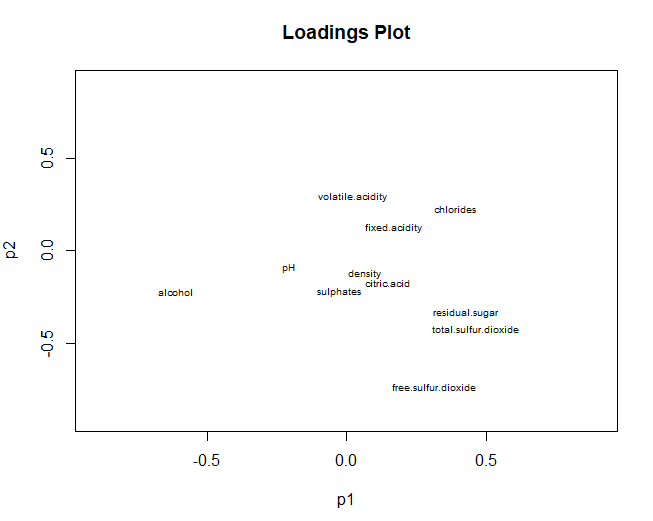
5.3.3 Погрузочно-ГРАФИК
С другой стороны, переходим к графику графика нагрузок, ссылаясь на переменные. В этом случае результаты очень похожи на результаты, полученные при анализе основных компонентов.. Общая сера, свободная сера и спирт, имеют большой вклад в обоих измерениях. тем не мение, с помощью PLS-DA получается, что pH не влияет ни на один из двух компонентов (в PCA внесли большой вклад во второй компонент)
5.4 ПРОГНОЗ МОДЕЛИ PLS-DA
В этом четвертом разделе будет сделан прогноз модели, использованной в этом третьем анализе.. Имея некоторые 5000 наблюдения, мы продолжаем создавать тренировочный набор и тестовый набор.
## PLS-DA
## 3800 образцы х 11 переменные и 1 ответ
## стандартное масштабирование предикторов и ответа(s)
## R2X(сперма) R2Y(сперма) Q2(сперма) RMSEE для орт pR2Y pQ2
## Общее количество 0.307 0.0982 0.0937 0.338 2 0 0.05 0.05
5.4.1 ОБУЧАЮЩИЙ НАБОР
Использование данных обучения, видно, что модель имеет точность 76,55%, что является очень приемлемым значением. тем не мение, внимательно посмотрите на наблюдения, которые вы прогнозируете для каждой из групп. Это значение точности является высоким, поскольку оно хорошо классифицирует почти все вина в группе. 2 («Хорошо» с рейтингом между 5 и 7). классифицирует 2801 вина в группе 2, и 43 оставаясь в группе 3.
тем не мение, из первой группы не классифицировали ни одного из этих скважин (120 в группе 2 и 1 в группе 3). в заключение, в группе 3 классифицировал 108 наблюдения, принадлежащие к этой группе и 727 для группы 2.
таким образом, можно сказать, что модель очень хорошо предсказывает вина второй группы. Должное, высокая точность.
## Матрица путаницы и статистика
##
## mypred
## 1 2 3
## 1 0 120 1
## 2 0 2801 43
## 3 0 727 108
##
## Общая статистика
##
## точность : 0.7655
## 95% CI : (0.7517, 0.7789)
## Нет информации Оценить : 0.96
## Р-значение [Точность > NIR] : 1
5.4.2 Тестовый набор
в заключение, проверить модель, то же самое будет сделано раньше, но, в таком случае, с наблюдениями модель ранее не видела (тестовый набор)
Тенденция, подобная той из обучающего набора, может наблюдаться. Модель имеет точность 76,92%, значение очень похоже на полученное в другом наборе. тем не мение, как обсуждалось ранее, модель очень хорошо классифицирует только вина группы 2 но две другие группы плохо их различают.
## Матрица путаницы и статистика
##
## mypred
## 1 2 3
## 1 0 30 0
## 2 0 692 19
## 3 0 170 38
##
## Общая статистика
##
## точность : 0.7692
## 95% CI : (0.7411, 0.7957)
## Нет информации Оценить : 0.9399
## Р-значение [Точность > NIR] : 1
6 ВЫВОДЫ
6.1 СРАВНЕНИЕ ИСПОЛЬЗОВАННЫХ МЕТОДОВ
в заключение, В этом проекте три метода были использованы для трех соответствующих анализов: Анализ главных компонентов, Кластеризация у частично наименьших квадратов — Дискриминантный анализ (PLS-DA).
Первый способ, СПС, послужил для получения предварительной обработки данных и таким образом, чтобы иметь возможность изучить базу данных немного более тщательно, Анализ переменных, которые имеют наибольший вклад в основные измерения, которые были получены. Аналогичные результаты могут быть найдены между PCA и PLS-DA, это, анализируя график загрузки обоих методов, были получены те же переменные, которые внесли больший вклад в эти два метода, за исключением некоторых исключений.
С другой стороны, СПС, благодаря очистке, которая была сделана в базе данных, послужил для второго анализа, кластеризация, так как это позволило получить кластеры более сбалансированным способом, нет ненормальных групп с небольшим количеством наблюдений.
в заключение, метод PLS-DA, в дополнение к тому, что было ранее прокомментировано о аналогичных результатах, полученных с PCA, был использован для оценки прогностической способности модели. Хорошая первая модель была получена, но она должна быть улучшена в будущем, потому что группы с более низкими наблюдениями не были предсказаны правильно.
6.2 ОБСУЖДЕНИЕ НЕПРИМЕННЫХ МЕТОДОВ
Три метода не были использованы в этом проекте: Факторный анализ соответствий (AFC), Правила ассоциации и дискриминантный анализ. Первые два метода не использовались, потому что база данных, использованная для этой работы, не имела качественных переменных. (только переменная ответа, качество вина). Факт преобразования всех переменных мог вызвать значительную потерю информации..
С другой стороны, Дискриминантный анализ также был хорошим вариантом для получения переменных, которые оказали наибольшее влияние при проведении различий между различными группами, в которых были классифицированы вина, и впоследствии, классифицировать новые наблюдения. PCA и кластеризация уже были применены и, потому что завершение PLS было обязательным, этот метод не мог быть изучен.
в заключение, Метод PLS-DA использовался в PLS, потому что переменная отклика была качественной. Таким образом, указанная переменная использовалась как Y, а другие физико-химические переменные как X.
7. ДРУГИЕ ТЕМЫ
7.1 КОММЕНТАРИИ К ЧИТАТЬ СТАТЬИ
Было возможно изучить, что различные группы не разделяются хорошо из-за качества. таким образом, видел это, было решено сделать небольшое исследование о том, как эта группа может выглядеть. Благодаря некоторым новостям и статьям стало возможным узнать, что качество вина не является линейной комбинацией физико-химических переменных, которые были доступны. таким образом, оценка вина не линейна, имеет глючные тенденции. На эти ошибки влияют критерии каждого судьи.
таким образом, переменная "качество", в случае получения из оценок экспертов-судей, У этого есть определенные неточности, которые являются из-за вкусов каждого из этих.
8. ПРИЛАГАЕМЫМ
8.1 БИБЛИОГРАФИЯ
- Руководство по характеристикам вина
- Как узнать, наслаждаюсь ли я качественным вином??
- HCPC
- Практическое руководство по основным компонентам методов в R (Kassambara)
- FactoMineR
- МУЛЬТИВАРИАНТНЫЙ АНАЛИЗ ДАННЫХ — Даниэль Пенья
- ЭЛЕМЕНТЫ СТАТИСТИЧЕСКОГО ОБУЧЕНИЯ
8.2 РАСПРЕДЕЛИТЕЛЬНЫЙ АНАЛИЗ ПЕРЕМЕННЫХ
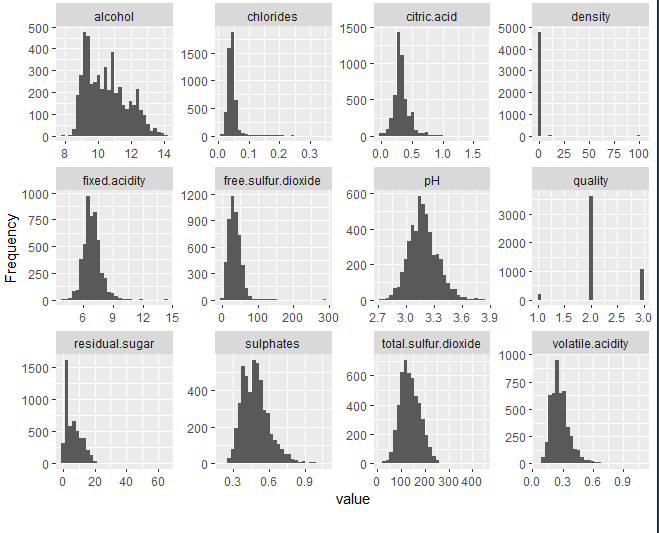
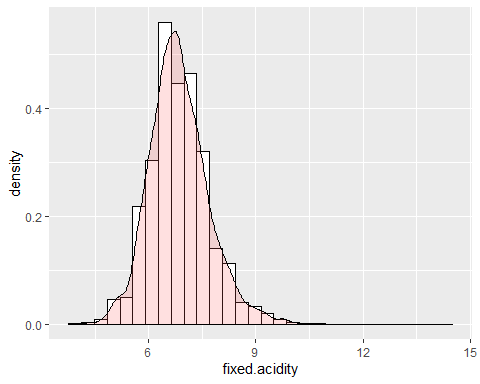
ГИСТОГРАММА ФИКСИРОВАННОЙ КИСЛОТЫ
Первой из переменных является фиксированная кислотность. Эта переменная имеет асимметрию 0.647 но эксцесс 5.16. Это указывает на то, что указанная переменная не соответствует нормальному распределению. Кроме того, наблюдаются экстремальные данные, которые принимают значение 14,2.
ГИСТОГРАММА ЛЕТУЧЕЙ КИСЛОТЫ
Летучая кислотность имеет форму, аналогичную предыдущей переменной. Эта переменная имеет асимметрию 1,576 и эксцесс 8,08 что также указывает на то, что оно не соответствует нормальному распределению.
Замечено, что две предыдущие переменные имеют длинные и положительные хвосты и, из-за этого, среднее значение намного выше, чем должно быть. 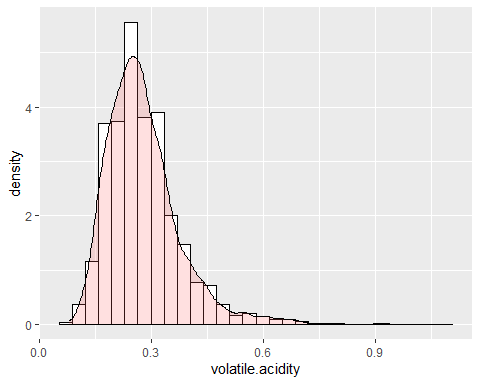
КИСЛОТНАЯ ГИСТОГРАММА
В кислоте можно наблюдать некоторые нетипичные данные, такие как 1,66 г / дм ^ 3, который отмечает максимум переменной. Помимо этого, асимметрия 1,28 и эксцесс 9,16. таким образом, и при этом оно не следует нормальному распределению.
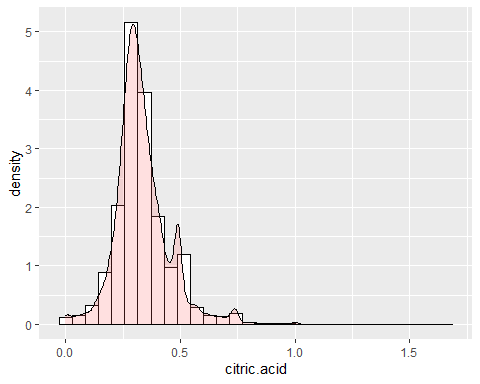
ОСТАТОЧНАЯ САХАРНАЯ ГИСТОГРАММА
Остаточный сахар имеет положительное смещение. Наблюдается, что он имеет асимметрию 1,07 и эксцесс 6,46, то есть, не следует нормальному распределению. Наблюдается очень высокий пик.
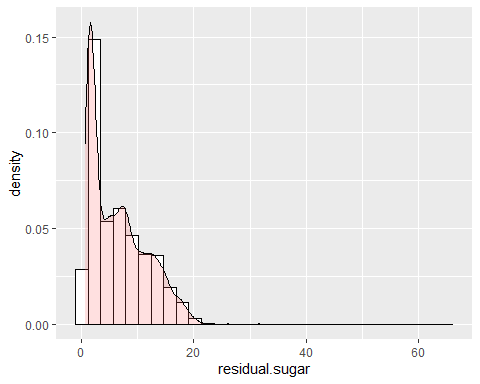
ХЛОРИНГИСТОГРАММА
Хлор имеет несколько экстремальных данных с коэффициентом эксцесса 40,52. Он также имеет положительную асимметрию с коэффициентом 5,02. Следовательно, указанная переменная не распределена в соответствии с гауссовым колоколом..
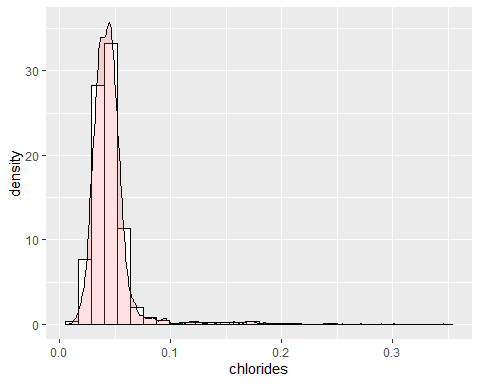
ВСЕГО И БЕСПЛАТНЫЕ ГИСТОГРАММЫ ДИОКСИДА СЕРЫ
Распределения по диоксиду серы, как бесплатно, так и полностью, симметричны, потому что они имеют коэффициенты перекоса 1,40 и 0,39 соответственно. В обоих случаях есть экстремальные данные (если не считать 14,45 и 3,57). Они не следуют нормальному распределению. 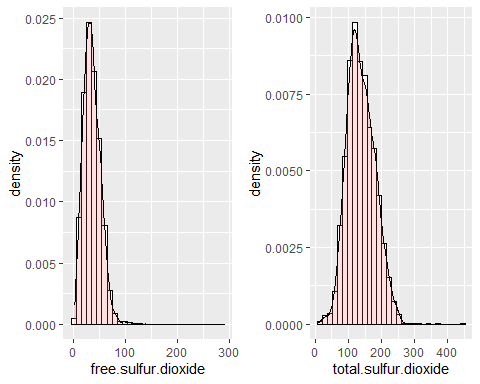
СУЛЬФАТНАЯ ГИСТОГРАММА
Сульфат имеет положительную асимметрию с коэффициентом 0.9768. Поскольку он имеет коэффициент эксцесса выше, чем 2, аномальные данные существуют и, так, не следует за звонкомде Гаусс.
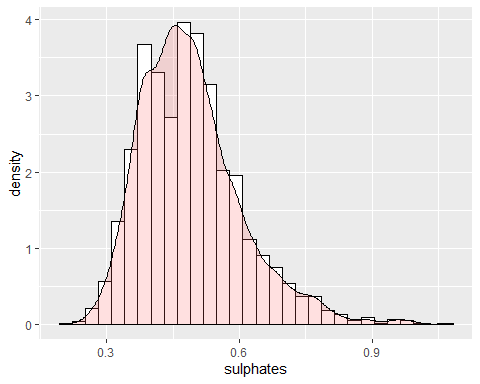
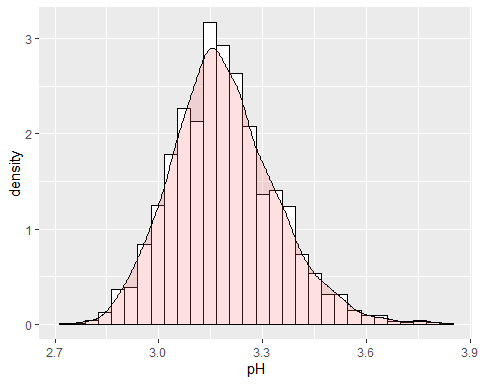
PH ГИСТОГРАММА
РН вина около 3,15 с некоторыми аномальными данными, потому что коэффициент эксцесса выше, чем 2.