
Применение статистических и прогностических методов
(FAMD, Кластеризация у PLS-DA)
на сердечно-сосудистых данных, чтобы узнать, какие переменные вызывают проблемы с сердцем.
Ангел Лэнгдон & Игнасио Кано
1. Описание исследования и база данных.
1.1 Описание исследования
В этом исследовании будет проведен анализ взаимосвязи между некоторыми переменными, которые указывают на физические свойства состояния человека. (подробно позже) и есть ли у вас проблемы с сердцем. таким образом, самые важные переменные будут получены при определении, если у человека есть проблемы с сердцем. Также, Будет предпринята попытка классифицировать людей в соответствии с их физическим состоянием на две группы., если у них были проблемы с сердцем или нет. Возможность прогнозирования с использованием модели PLS-DA также будет изучена..
1.2 Описание базы данных
База данных состоит 14 переменные и 303 наблюдения. Переменные, с которыми мы работаем, являются общими и простыми для понимания.. Большинство из них имеют дело с техническими аспектами сердечных свойств и уровнями определенных веществ, которые влияют на определение наличия сердечных заболеваний.. затем, se explican las 14 переменные для большей ясности при выполнении анализа, Кроме того, важно знать, что тема собирается провести хороший анализ.
- Возраст: Возраст человека в годах
- секс: Пол человека (1 = мачо, 0 = женщина)
- Pain_chest: Тип боли в груди испытал
- Стоимость 0 -> Ангина типичная
- Стоимость 1 -> Атипичная стенокардия
- Стоимость 2 -> Боль в груди, но не стенокардия
- Стоимость 3 -> Бессимптомная боль
- (Ангина = сильная боль, вызванная недостаточным кровоснабжением <> к сердечным клеткам)
- p_sanguinea_mmHg: Измеренное артериальное давление в состоянии покоя, мм рт.ст.
- холестерин: Уровень холестерина человека измеряется в мг / дл
- гипергликемия: Уровень глюкозы в крови (свободная глюкоза в крови) постящийся человек (>120мг / дл, 1 = правда ; 0 = ложь). Если оно превышает 120 мг / дл, это называется гипергликемией, и если у пациента длительное время наблюдается гипергликемия, это способствует развитию диабета.
- electro_repost: ЭКГ покоя человека
- Стоимость 0 -> нормальный
- Стоимость 1 -> Аномалия волны сегмента ST-T (связаны с различными проблемами с сердцем в зависимости от типа аномалии)
- Стоимость 2 -> Гипертрофия левого желудочка (вызвано высоким кровяным давлением, может вызвать сердечный приступ)
- beats_minute: Самые высокие удары в минуту, записанные человеком
- angina_by_exercise: Если стенокардия была вызвана физическими упражнениями (1 = да; 0 = нет)
- s_st: Изучена депрессия сегмента ST, вызванная физическими упражнениями, по сравнению с депрессией сегмента ST, когда пациент находится в покое. Чем выше это значение, тем выше вероятность возникновения проблем с сердцем..
- pending_s_st: наклон сегмента ST на пике упражнений
- Стоимость 1 -> Наклон вверх
- Стоимость 2 -> Плоская серьга
- Стоимость 3 -> Отрицательный уклон
- Было бы интересно изменить эти значения на 1, 0 и -1 соответственно, чтобы быть немного более похожим на то, что они представляют.
- n_vasos_sanguineos: количество основных кровеносных сосудов (0-3)
- default_type: Это тест, проведенный с радиоактивным элементом (таллий) вводится в кровоток пациентов. Это позволяет изучать кровоток как в состоянии покоя, так и при физических нагрузках.:
- Стоимость 3 -> Нормальный кровоток.
- Стоимость 6 -> Никакого кровотока в области не наблюдается, ни в покое, ни при физической нагрузке. (исправленный дефект)
- Стоимость 7 -> Никакого кровотока не наблюдается в области во время тренировки, но в состоянии покоя. (обратимый дефект)
- problem_heart: Проблемы с сердцем:
- Стоимость 0 -> нет
- Стоимость 1 -> да
- Стоимость 2 -> да, наихудший
- Стоимость 3 -> да, намного хуже
- Стоимость 4 -> да, худший из возможных
- Следует отметить, что переменная problem_heart Он послужит справочной информацией, чтобы узнать, можем ли мы предсказать возможные случаи проблем с сердцем из значений, которые люди принимают в остальных переменных.. Поэтому эта переменная будет принята за дополнительную и послужит справочной..
2. Первоначальный разведочный анализ и предварительная обработка данных
2.1 Отсутствующие данные
Мы проверяем, что нет пропущенных данных, для этого график отсутствующих данных отображается в соответствии с переменной
Как вы можете видеть, что в любой переменной нет пустых полей?.
2.2 Переменные и / или удаленные записи.
Небольшое исследование, этот набор данных в столбце номера кровеносных сосудов некоторые наблюдения принимают значение ?, что неправильно. (В исходном наборе данных они представляют NaN). То же самое происходит с переменной дефектом, кто берет смелость ?, это плохо. Поэтому мы исключим эти наблюдения
2.3 Перекодирование переменных
Этот шаг выполняется для получения более описательных категорий. Таким образом, категории, которые ранее были «1» и «0», станут человек и женщина соответственно.
2.4 Переменное распределение
Этот шаг выполняется для того, чтобы увидеть, какие значения принимают переменные, а также убедиться, что нет ошибочных значений..
В приложении 8.2: Анализ распределения переменных все объяснил
После изучения распределения переменных, мы видим, что ни один из них не имеет неправильных значений, и поэтому, мы можем продолжить анализ.
3. Анализ 1 FAMD(factominer)
FAMD (Факторный анализ смешанных данных) является основным компонентом метода, предназначенного для исследования данных с непрерывными и категориальными переменными. Вообще говоря, это смесь PCA и AFC.
Конкретный, непрерывные переменные масштабируются до единичной дисперсии, а категориальные переменные преобразуются в дизъюнктивную таблицу, а затем масштабируются с использованием критериев AFC.. Это делает оба типа переменных представительными в анализе.. Так сказать, что один тип переменных не влияет больше, чем другой тип переменных. В таком случае, Корасонова проблема с сердцем »останется в качестве дополнительной переменной, так что мы можем видеть, если без их присутствия люди делятся на две группы, как если бы указанная переменная присутствовала. Если вы хотите найти больше информации о FAMD, вы можете сделать это на http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/115-famd-factor-analysis-of-mixed-data-in-r-essentials/ а также в https://rdrr.io/cran/FactoMineR/man/FAMD.html
3.1 цели
- Выполните предварительную обработку данных, которые являются числовыми и категориальными, чтобы получить их матрицу оценок (с наиболее значимыми X основными компонентами) чтобы иметь возможность использовать его в кластеризации (кластеризация не поддерживает смешанные данные)
- Изучите взаимосвязь между переменными физического состояния человека, оставив переменную проблемы с сердцем дополнительной, чтобы она не влияла на исследование, и посмотрите, есть ли у людей, сами, они делятся на две группы (с проблемой с сердцем да или нет).
3.2 Применение метода и числовые и графические результаты
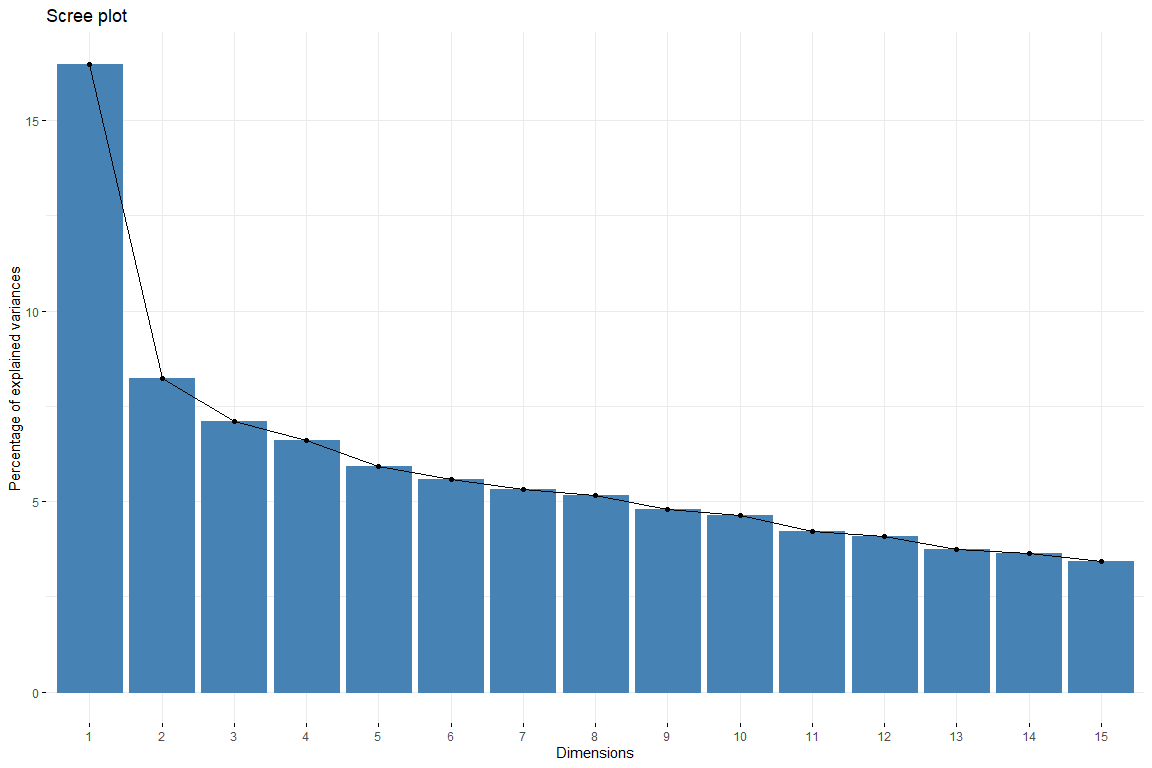
На графике осыпи мы видим, как из 6 измерение вклад размеров уменьшается равномерно. таким образом, будет выбран 6 размеры для представления наших данных. Мы также ловим 6 Размеры с тех пор мы получаем объяснение 50% изменчивости. Теперь мы собираемся изучить вклад переменных в первые измерения.
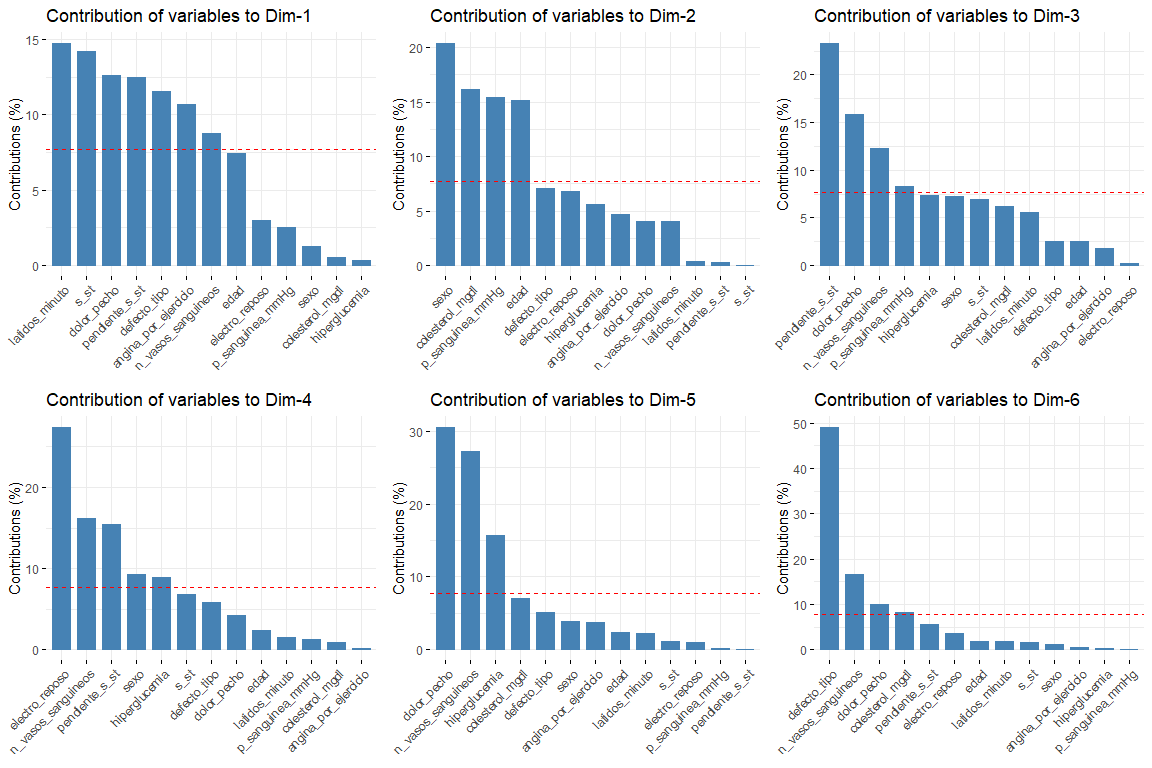
Наиболее интересными являются результаты первых двух измерений (поскольку именно они объясняют наибольшую изменчивость). Следует отметить, что первое измерение характеризуется несколькими переменными (логично, поскольку именно он объясняет наибольшую изменчивость) это default_type, боль и грудь. Во втором измерении, количество переменных, которые характеризуют это измерение, меньше, чем у первого измерения, а это секс, возраст, cholesterol_mgdl, p_sanguinea_mmHg. Как только первые два измерения характеризуются, мы увидим график переменных, нарисованный в векторном пространстве первых двух измерений, чтобы наблюдать отношения между переменными, и его характеристика в каждом из двух измерений более наглядным способом.
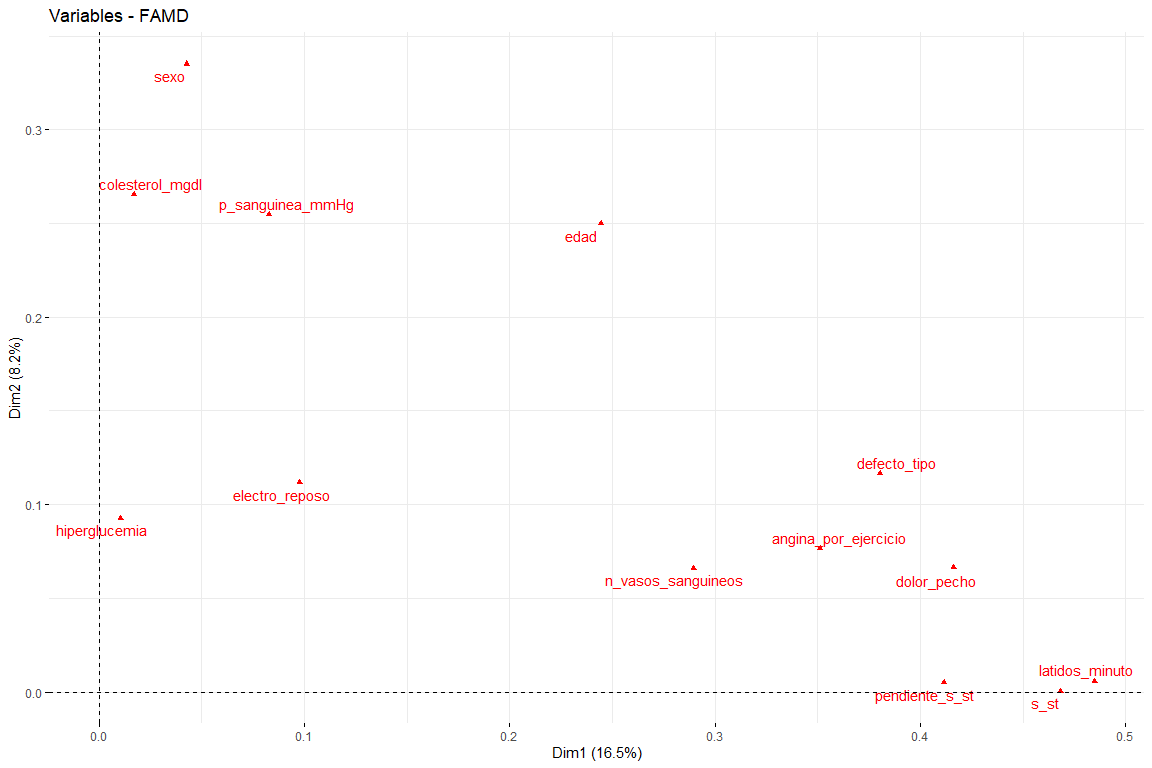
На этом графике мы можем видеть представленные первые два измерения (самое важное) и у нас есть результаты, которые подтверждают те, которые видны на графике вклада. Переменные, такие как latidos_minuto или s_st, являются теми, которые вносят наибольший вклад в первое измерение, а переменные пол или возраст имеют большой вклад во второе измерение..
3.3 Обсуждение результатов
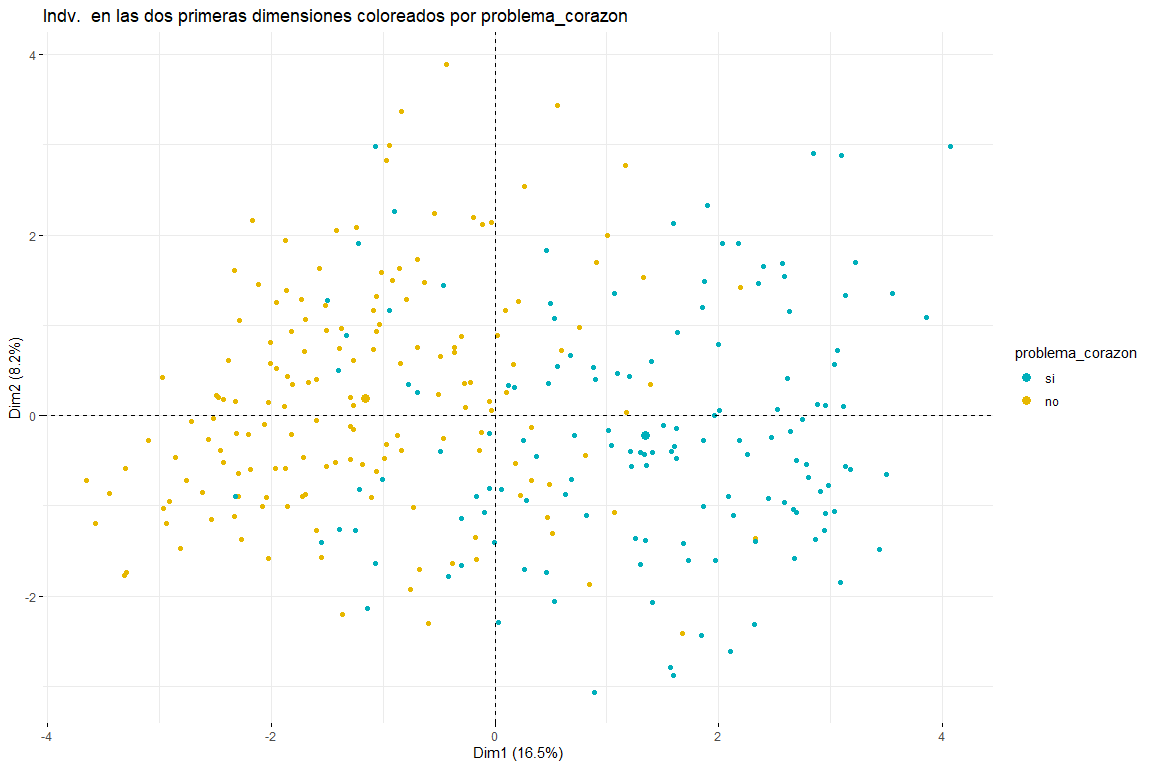
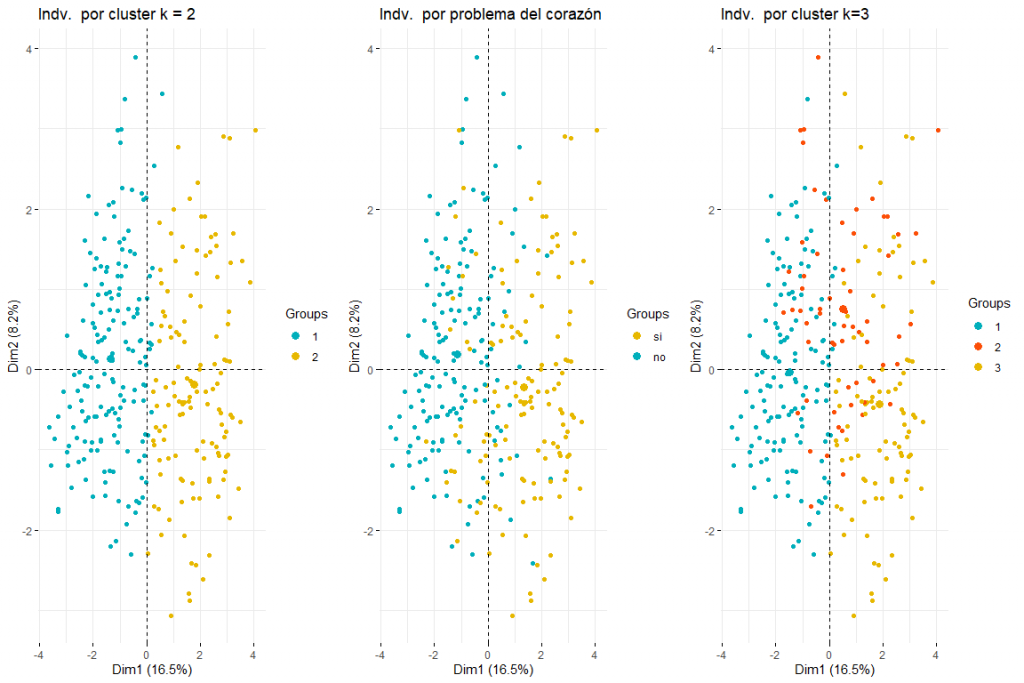
После просмотра графика лиц, раскрашенных с помощью problemma_corazon, мы можем различить две и три группы (для этого потребуется последующий кластерный анализ) оба возможных результата имеют смысл, поскольку две группы подразумевают, что значения в определенных переменных (default_type, pain_chest, секс, возраст, cholesterol_mgdl, p_sanguinea_mmHg) подразумевают разделение между случаями проблем с сердцем и теми, которые не. Три кластера также могут иметь смысл, так как, видя график, мы видим, как разделены значения problem_heart = yes и problem_heart = no., но мы также можем видеть, как в центре значения проблемы с сердцем да и проблемы с сердцем нет, поэтому наличие трех кластеров также возможно. Можно также утверждать, что основное направление разделения групп обусловлено первым измерением., поэтому переменные дефекта_типа, pain_chest, s_st, default_type, p_sanguinea_mmHg - это те, которые позволят идентифицировать тех пациентов, которые перенесли проблемы с сердцем. Также кажется, что люди, у которых были проблемы с сердцем, не только смещены вправо, но и вниз. Это будет означать, что переменные, которые вносят наибольший вклад во второе измерение (секс, возраст, cholesterol_mgdl, p_sanguinea_mmHg) они также должны были бы определить, есть ли у пациента проблемы с сердцем. Ожидается, что эти выводы будут подтверждены последующим кластерным анализом из этого анализа FAMD..
4. Иерархическая кластеризация
HCPC (Иерархическая кластеризация по основным компонентам) это алгоритм, который группирует похожих людей в кластеры, но с особенностью. Это сделано для работы с результатами метода главных компонент (PCA, МИД, FAMD ...). Чтобы получить больше информации: http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/117-hcpc-hierarchical-clustering-on-principal-components-essentials/
4.1 задача
- Посредством матрицы баллов, полученных в FMAD, проследите, получают ли путем иерархической кластеризации с этими людьми два кластера, которые группируют людей в людей с проблемами сердца и без них.. На случай, если этого не произойдет, изучить причину существования неожиданного количества кластеров.
4.2 Применение метода
Чтобы сделать кластеризацию, мы будем использовать координаты людей в 6 размеры, которые мы взяли в FAMD. Цель FAMD, как обсуждалось ранее, должен был предварительно обработать данные, чтобы иметь возможность впоследствии кластеризовать. тем не менее, Мы получили довольно показательные результаты только с FAMD, и ожидается, что с помощью кластерного анализа эти результаты будут подтверждены..
Для расчета матрицы баллов, которая в дальнейшем будет использоваться при кластеризации, все переменные, которые указывают физическое состояние человека, будут использованы. Подчеркнуто, что в иерархической кластеризации переменная problem_heart НЕ будет включена, так что она не будет иметь никакого эффекта при расчете кластеров.. Поскольку цель состоит в том, чтобы рассчитать кластеры через переменные физического состояния, чтобы увидеть, связано ли это с проблемой с сердцем.
4.2.1 Мы рассчитываем расстояния и статистику Хопкинса
Перед применением любого алгоритма кластеризации важно спросить себя, существует ли для него какой-либо тип группировки, Мы выполняем статистику Хопкинса, которая показывает, есть ли группировка в данных. Мы должны помнить, что библиотека 'clustertend' возвращает 1-H, где H - статистика Хопкинса..
$ЧАС
## [1] 0.2628502
В случае данных о сердце статистик имеет значение 0.26 очень далеко от 1, так, мы можем подтвердить, что в наших данных есть группировка.
4.2.2 Оптимальное количество кластеров
Чтобы можно было запустить алгоритм иерархической кластеризации, мы должны знать оптимальное количество кластеров. Для этого мы запустим следующие тесты.
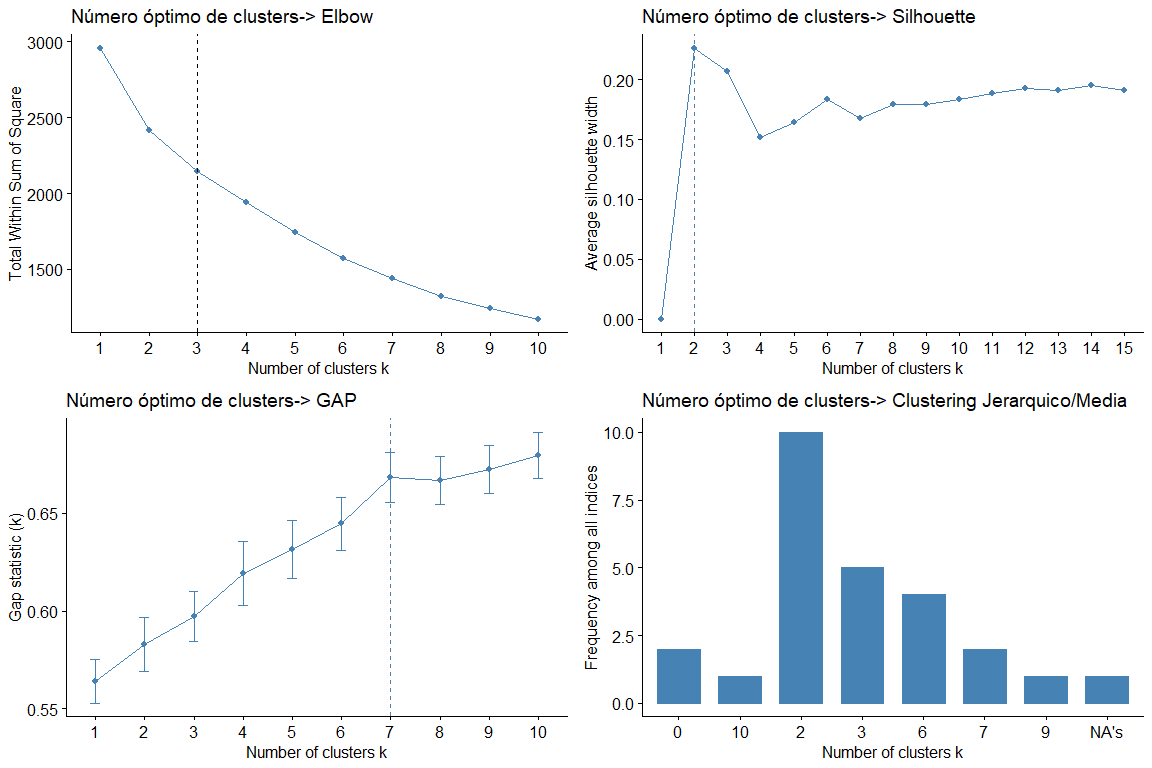
Глядя на графики и таблицы, мы видим, что для разных статистических данных и методов мы получаем разные значения кластеров.. Наиболее частым результатом является рассмотрение 2 кластеры, с последующим 3 кластеры. (результат 7 это также кажется повторным, но так как не имеет смысла рассматривать 7 группы мы отвергаем этот вывод)
затем, мы делаем кластерный сюжет 2 и 3 кластеры соответственно, чтобы увидеть, какой из них лучше всего соответствует нашим данным. Мы используем для получения данных Kmeans, так как при анализе данных мы видим, что данные не имеют очень экстремальных значений и, следовательно,, нет необходимости в более надежных методах, таких как PAM, например.
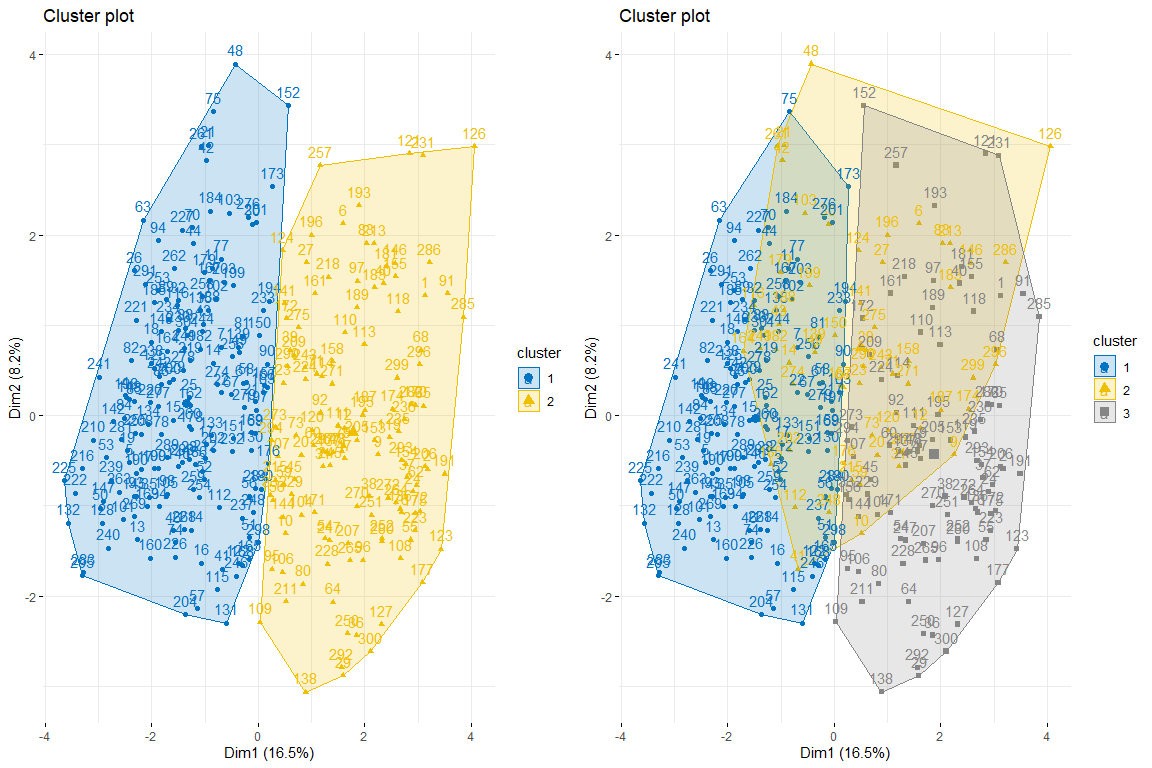
Как мы можем наблюдать 2 кластеры, кажется, лучший вариант, так как он создает 2 довольно естественные группы, то есть, те люди с проблемами сердца и те, кто не.
Мы продолжим сравнение между двумя и тремя кластерами, раскрасив индивидуумов из графика индивидуумов FAMD..
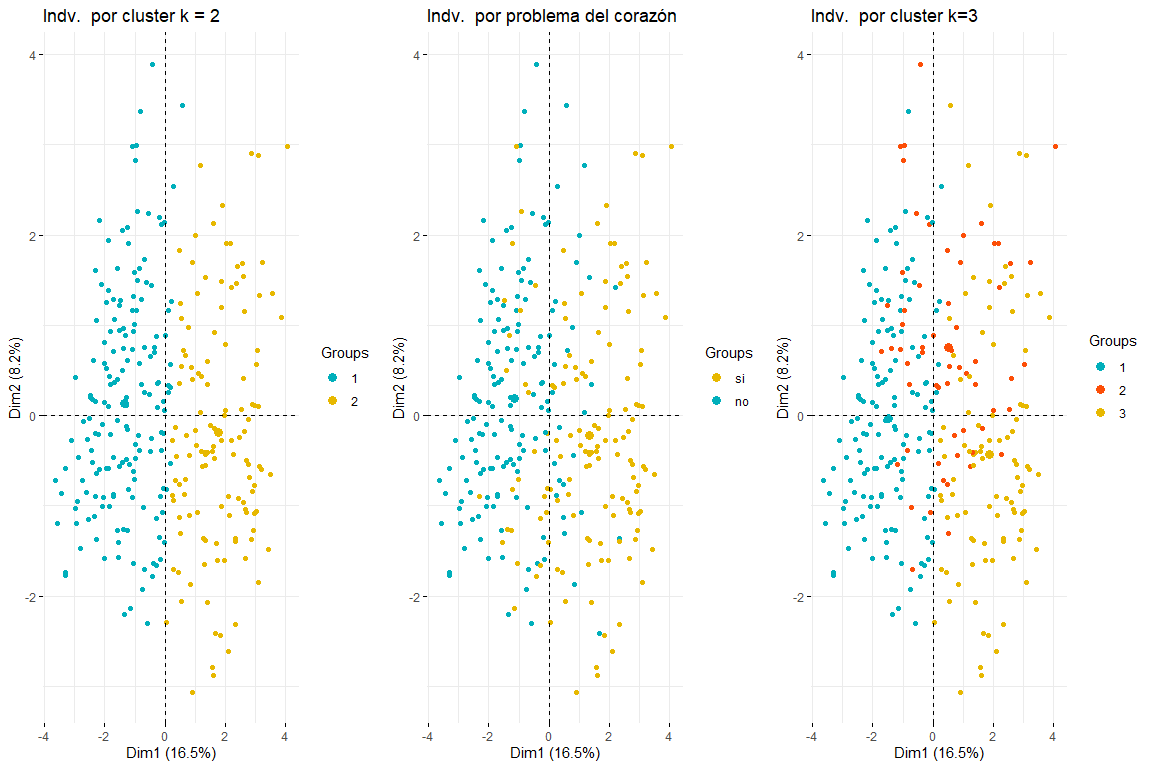
Как видно из трех графиков индивидуумов, раскрашенных кластером и проблемой с сердцем, понятно, что два кластера - это тот, который лучше всего адаптируется, и выглядит больше как список лиц, окрашенных в проблемы с сердцем. После сравнения этих трех групп графиков можно сделать вывод, что использование двух кластеров больше соответствует распределению данных в соответствии с problem_heart. Для всего этого, два кластера будут выбраны для иерархической кластеризации.
4.3 Числовые и графические результаты
Наконец, связь между переменными и двумя кластерами и, таким образом, их отношения с тем, есть ли у них проблемы с сердцем. Начнем с соотношения категорий качественных переменных и принадлежности к тому или иному кластеру.. Очевидно, что те категории, которые наиболее связаны с кластером, относятся к категории с более высоким v.test, в то время как те, чье значение v.test очень отрицательно, менее связаны будут с указанным кластером (и поскольку у нас есть только два кластера, вероятно, эти категории с очень отрицательным значением v.test будут связаны с другим кластером.).
res.hcpc2$desc.var$категория
## $`1`
## p.value v.test
## slope_s_st = положительный 2.930295e-25 10.384064
## angina_por_exercise = angina_no_exercise 1.061236e-23 10.035774
## default_type = normal 2.733441e-22 9.709997
## n_vasos_sanguineos = 0 4.846452e-13 7.229537
## pain_chest = angina_atipica 4.782592e-11 6.577551
## pain_chest = pain_no_angina 1.569061e-07 5.244266
## секс = женщина 4.235184e-05 4.094260
## electro_repost = нормальный 4.769950e-03 2.822173
## $`2`
## Cla / Mod Mod / Cla Global
## p.value v.test
## angina_por_exercise = angina_exercise 1.061236e-23 10.035774
## pendiente_s_st = plana 5.739929e-20 9.149120
## pain_chest = бессимптомно 8.164639e-19 8.857749
## дефект_тип = дефект_реверсивный 2.547142e-15 7.911300
## секс = мужчина 4.235184e-05 4.094260
## n_vasos_sanguineos = 2 4.952918e-05 4.057838
## n_vasos_sanguineos = 3 9.157912e-05 3.911883
## default_type = fixed_defect 1.073890e-04 3.873260
## n_vasos_sanguineos = 1 4.649990e-03 2.830331
## electro_reposto = гипертрофия_izq 2.225498e-02 2.285988
## electro_repost = ненормальность_st 3.297443e-02 2.132394
## slope_s_st = отрицательный 4.472770e-02 2.007206
Теперь мы увидим связь между количественными переменными и двумя кластерами. Наиболее репрезентативными являются переменные с наивысшим значением v.test (в абсолютном значении) и, глядя на разницу между значениями «среднее в категории» и «общим значением», мы можем получить представление о том, какие значения люди в кластере принимают за эти переменные.
## $`1`
## v.test Среднее в категории Общее среднее значение sd в категории
## beats_minute 10.133353 161.3313609 149.597973 16.6608075
## p_sanguinea_mmHg -3.346967 128.6508876 131.648649 16.2372212
## возраст -6.575012 51.5147929 54.513514 8.9085469
## s_st -9.798909 0.4757396 1.051351 0.6908983
##
## $`2`
## v.test Среднее в категории Общее среднее значение sd в категории
## s_st 9.798909 1.817323 1.051351 1.222434
## возраст 6.575012 58.503937 54.513514 7.537699
## p_sanguinea_mmHg 3.346967 135.637795 131.648649 18.848618
## beats_minute -10.133353 133.984252 149.597973 20.744028
Так что, вы можете видеть, что индивидуумы, которые составляют первый кластер, определяются высокими значениями в beats_minute (по отношению к среднему), низкий возраст, p_sanguinea y s_st. Мы также можем увидеть, как люди в кластере 1, то есть те случаи, которые не перенесли проблемы с сердцем, Они женщины, чья боль в груди не является атипичной стенокардией или стенокардией и не вызвана физическими упражнениями. Также, твой электро в состоянии покоя нормальный, его значение после теста с Thalium нормальное, а значение n_vasos_sanguíneos 0.
С другой стороны, люди во втором кластере - преимущественно мужчины, чье кровяное давление выше среднего, чьи удары в минуту меньше среднего, а s_st больше среднего. Они также выделяются тем, что имеют плоский slope_st, некоторые значения 1, 2 В 3 в n_vasos_sanguíneos, чья стенокардия вызвана физическими упражнениями, у него бессимптомная боль, и его значение после талиевого теста обратимо или фиксировано. Наконец, его значения покоя электро являются гипертрофией или ненормальностью.
4.4 Обсуждение результатов
Как вы можете видеть переменные, которые наиболее характеризуют кластеры и, следовательно,, также, если у человека есть проблемы с сердцем или нет, те переменные, которые внесли наибольший вклад в первое и второе измерения FAMD, сделанные ранее. Также, мы можем видеть, что полученные выводы имеют смысл; те, кто страдал от проблемы с сердцем (принадлежность к кластеру 2) иметь очень низкую максимальную частоту сердечных сокращений в минуту, пожилой возраст, они мальчики, выше нормального кровяного давления, бессимптомная боль в груди ... все это факторы риска сердечно-сосудистых заболеваний.
5. Анализ 3: PLS-DA
Регрессия частичных наименьших квадратов или Регрессия частичных наименьших квадратов (PLS регрессия) это статистический метод, который связан с регрессией основных компонентов, вместо нахождения максимальной дисперсии гиперплоскостей между переменной отклика и независимыми переменными, линейная регрессия находится путем проецирования переменных предсказания и наблюдаемых переменных в новое пространство. Поскольку данные X и Y проецируются в новые пространства, семейство моделей PLS известно как билинейный модельный фактор. В нашем случае, мы будем использовать дискриминантный анализ частичных наименьших квадратов (PLS-DA) которые являются вариантом, который используется, когда Y является двоичным.
5.1 цели
Есть две цели при выполнении PLS-DA:
Первый - сравнить результаты, полученные в FAMD, используя графики оценок и нагрузок, и посмотреть, можно ли интерпретировать один и тот же результат.. Также с помощью графика диагностики наблюдений мы можем наблюдать наличие или отсутствие экстремальных данных..
Вторая цель состоит в том, чтобы оценить прогнозирующую способность модели PLS-DA с данными, которые будут разделены на тренировочные данные и тестовые данные. Это поможет увидеть, возможно ли предсказать новые случаи проблем с сердцем с помощью доступных переменных..
5.2 Применение метода
Для применения метода был использован другой препроцесс «независимых» переменных, которые будут формировать нашу матрицу X, поскольку функция opls требует, чтобы все столбцы матрицы X имели тип «числовой» (код доступен в приложении)
Как это можно наблюдать благодаря диаграмме диагностики наблюдений, нет экстремальных ценностей, поэтому мы можем продолжить анализ PLS-DA без необходимости удалять какое-либо значение.
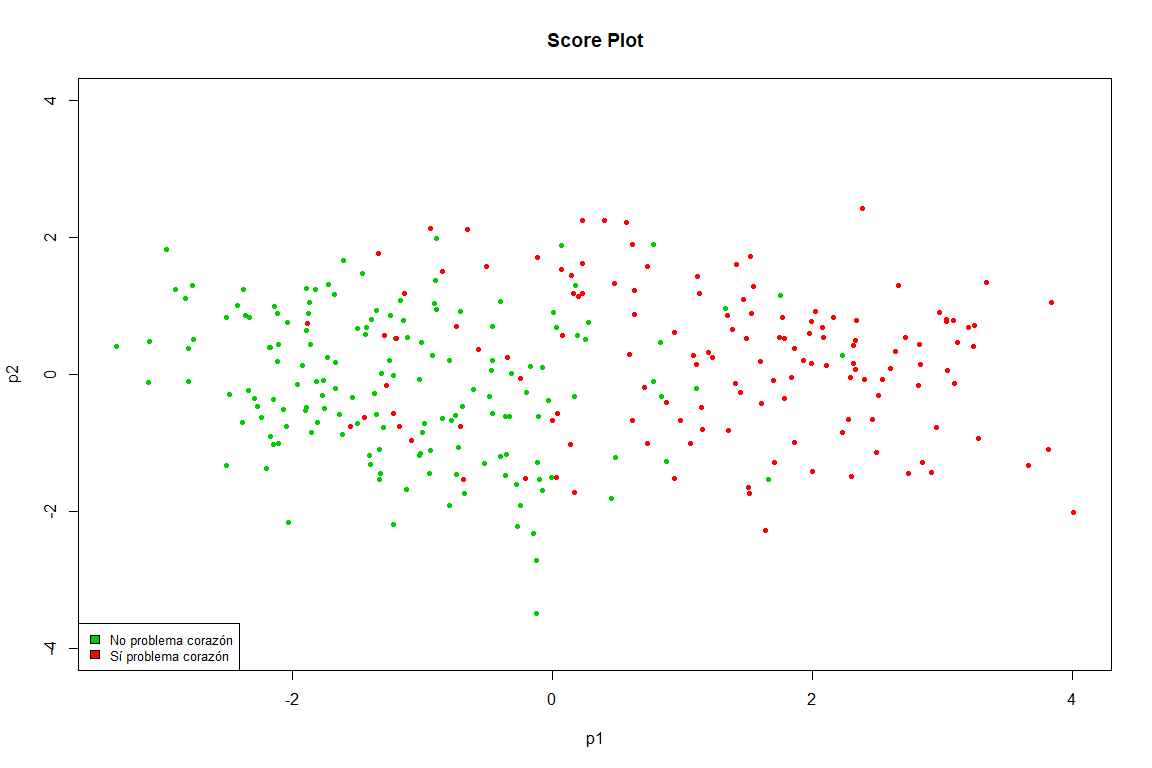
Этот график является практически копией полученного в FAMD, мы видим, насколько четко точки разделены на две группы (проблема с сердцем, а не с сердцем)
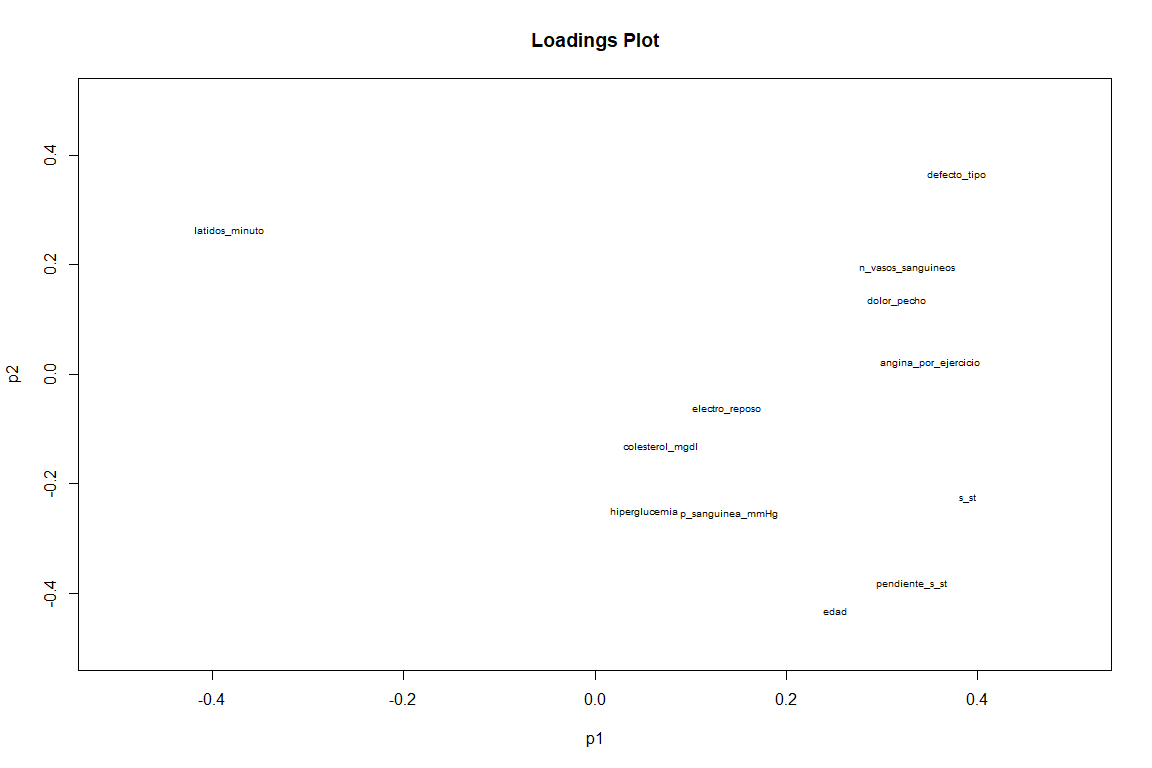
На графике нагрузок, если мы увидим несколько иной результат из графика нагрузок FAMD. Мы видим как переменные как slope_s_st, default_type и minute_beats (хотя это с отрицательным значением ) иметь большой вклад в эти два компонента. В то время как переменные, такие как angina_por_exercicio и pain_chest, способствуют прежде всего первому компоненту.
Теперь мы переходим к анализу прогнозирующей способности PLS-DA с использованием данных обучения и тестовых данных..
mypred = прогнозировать(myplsda)
confuTrain = стол(trainData$problem_heart, mypred)
confusionMatrix(confuTrain)
## Матрица путаницы и статистика
## mypred точность : 0.8487
## 0 1 Каппа : 0.6946
## 0 113 15
## 1 21 89 Сбалансированная точность : 0.8495
Как мы можем увидеть модель, предсказывающую свои собственные строки, Имеет точность 0.85, очень хорошая ценность, которую поддерживает каппа 0.7, что указывает на хорошее согласие наших данных. (https://es.wikipedia.org/wiki/Coeficiente_kappa_de_Cohen)
Следующая вещь - попытаться предсказать данные, которые PLS-DA никогда не «видел»
mypred = прогнозировать(myplsda, TestData[,—14])
confuTest = стол(TestData$problem_heart, mypred)
confusionMatrix(confuTest)
## Матрица путаницы и статистика
## mypred точность : 0.8448
## 0 1
## 0 28 3 Каппа : 0.6859
## 1 6 21 Сбалансированная точность : 0.8493
Модель имеет аналогичные значения (точность у каппа) для данных, которые вы никогда не видели, с помощью которого можно сделать вывод, что эта модель, Прогнозирует достаточно хорошо, если у нового случая будет проблема с сердцем или нет с вероятностью приблизительно 84% (точность 0.84)
5.4 Обсуждение результатов
Вы можете увидеть, как PLS-DA является очень хорошим методом для прогнозирования новых случаев проблем с сердцем у пациентов., тем не мение, Следует отметить, что исследование состояло из 300 приблизительно пациентов, поэтому нужно было бы увеличить количество людей, чтобы увидеть, действительно ли эта модель PLS-DA предсказывает с такой уверенностью (84%) будет ли у пациента проблема с сердцем или нет. С другой стороны, И матрица баллов, и матрица нагрузок были изучены в двух компонентах. (самый значительный) и различия с результатами FAMD были изучены.
6. Выводы
6.1 Использованные сравнительные методы
В этой работе, три метода были использованы: FAMD, Иерархическая кластеризация и PLS-DA.
И FAMD, и кластеризация показали практически одинаковые результаты. (информация найдена в разделе выводов соответствующего метода) это имеет смысл, поскольку координаты отдельных лиц в первых шести основных компонентах были использованы для выполнения иерархической кластеризации, поэтому FAMD послужил нам предварительной обработкой данных (для кластеризации) а также в качестве первого анализа отношений между переменными и отдельными лицами в нашей базе данных. При кластеризации мы подтвердили те первые наблюдения, которые мы сделали о существовании двух групп и переменных, которые на них влияют.. PLS-DA, хотя он также использовался для сравнения результатов с результатами FAMD из-за возможного сходства графиков Scores и Loadings., в основном он использовался для оценки прогностической способности модели с нашими данными. Таким образом, обнаружение большой прогностической способности модели с точностью 85% в данных, которые я никогда не видел (данные испытаний).
6.2 Обсуждение неприменимых методов
Методы, которые не были использованы в этой работе: Правила ассоциации, дискриминантный анализ.
Первый, правила ассоциации не используются, потому что мы считаем, что они не соответствуют нашей базе данных (наши переменные не являются качественными, и факт преобразования всех переменных означал бы значительную потерю информации). Вместо, кластеризация и возможность на самом деле видеть кластеры, на которые была разделена наша база данных, показались нам гораздо более интересным.
Относительно дискриминантного анализа, Это правда, что это был бы очень интересный вариант, поскольку именно наше намерение с самого начала состоит в том, чтобы увидеть переменные, которые в наибольшей степени связаны с проблемами с сердцем или нет., затем предсказать будущие случаи или классифицировать лиц, которые у нас уже были. тем не мение, PLS или PLS-DA было обязательным для использования, а анализ FAMD и кластеризация уже проводились, которые считаются более актуальными в этом случае, чем дискриминантный анализ, поэтому было решено обойтись без него.
Последним, выбор между PLS и PLS-DA очевиден, поскольку целью всегда было изучение взаимосвязи между проблемой сердца и другими переменными, поэтому лучшим вариантом в этом случае является выбор PLS-DA., используя в качестве Y проблему с сердцем и в качестве X остальные переменные, чтобы изучить взаимосвязь между ними и способность прогнозировать.
7 Другие темы
7.1 Комментарии к прочитанным статьям
Идея удаления как FAMD, так и иерархической кластеризации (а также с использованием матрицы оценок для иерархической кластеризации) ха хирургидо дель либро ‘Практическое руководство по основным компонентам методов в R (Kassambara)’Y del libro‘ Исследовательский многомерный анализ на примере с использованием R (коробейник & Hall / CRC Computer Science & Анализ данных)Франсуа Хуссон. Мы считаем, что это очень мощный инструмент для объединения обоих методов (FAMD и кластеризация) с первого, позволяет нам удалить шум из наших данных, и второй, используя FAMD в качестве предварительной обработки, мы можем использовать «смешанные данные» в кластеризации, что приносит нам большую пользу.
8. Приложение:
8.1 Blibliography
- HCPC I
- FAMD I
- Информация в ожидании сегмента ST
- ‘Практическое руководство по основным компонентам методов в R (Kassambara)»
- ‘Исследовательский многомерный анализ на примере с использованием R (коробейник & Hall / CRC Computer Science & Анализ данных)Франсуа Хуссон
- FactoMineR Документация
- Изменения в сердце и кровеносных сосудах вследствие старения
- Максимальное количество ударов в минуту
- Факторы риска сердечно-сосудистых заболеваний
- Используемые данные
8.2 Анализ распределения переменных
Переменная возраста не принимает экстремальные значения, а переменная пола не содержит ошибочных значений.
Переменная боль в груди не содержит неправильных значений, так же, как и переменное кровяное давление.
Две переменные холестерина мг / дл и гипергликемия не принимают неправильные значения.
Результаты двух переменных электрокардиограммы и максимальных ударов в минуту не принимают неправильных значений.. Однако следует подчеркнуть, что существуют несколько высокие значения для возраста пациентов. (по формуле Хаскелла & Лиса, Использование которых широко используется для определения максимальных пульсаций в зависимости от возраста).
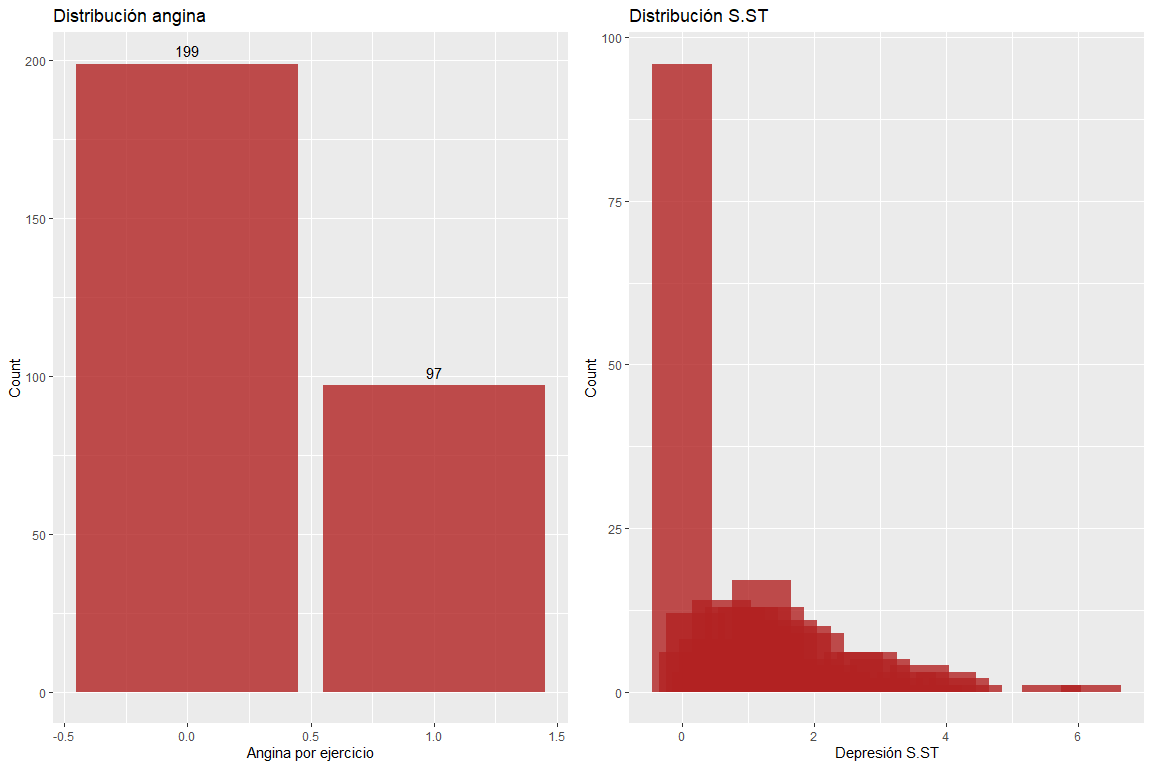
Две переменные упражнения стенокардия и депрессия сегмента ST не имеют ошибочных значений.. Но следует подчеркнуть, что есть наблюдения с очень высоким значением депрессии сегмента ST.
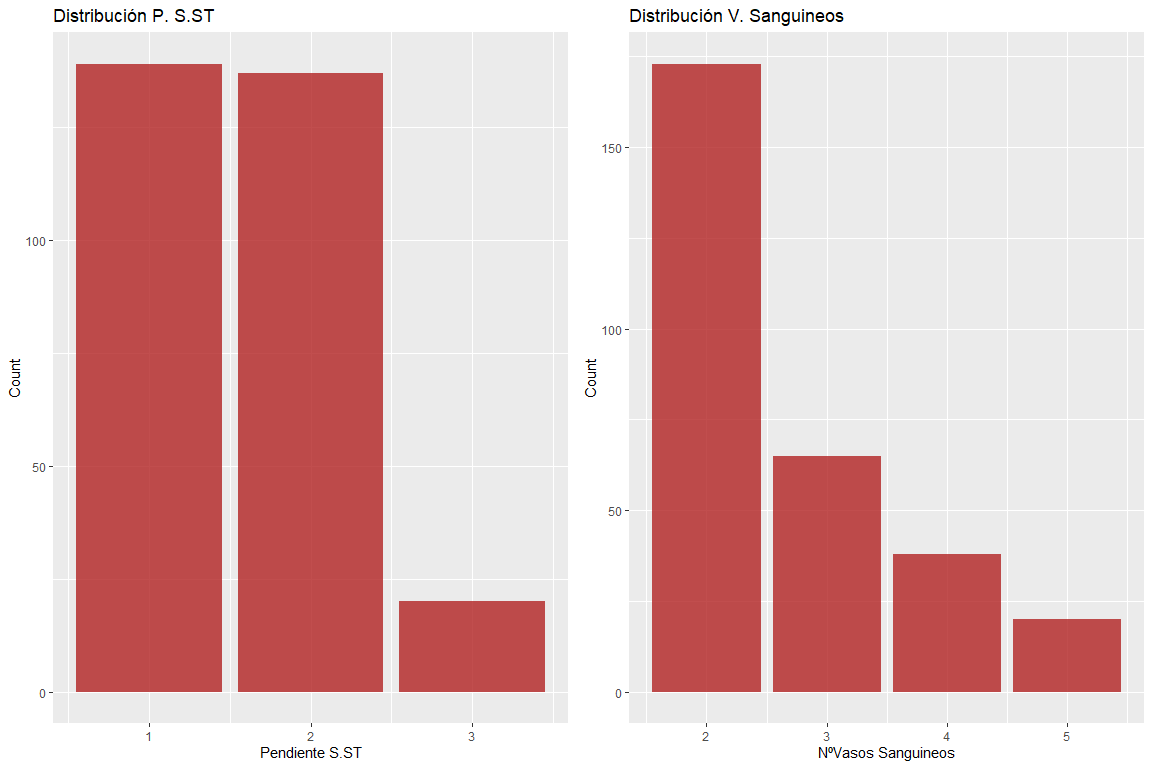
Две переменные в ожидании сегмента ST и количества кровеносных сосудов не имеют ошибочных значений.
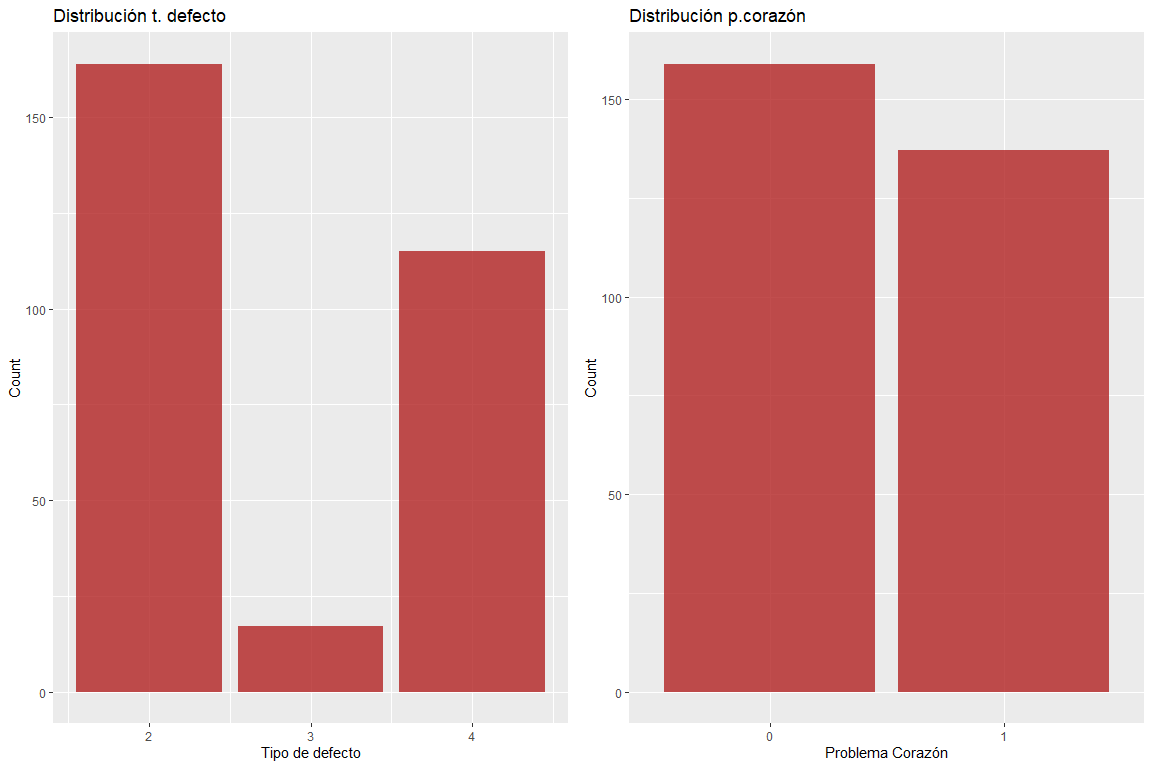
Дефект типа двух переменных и проблемы с сердцем не имеют ошибочных значений.