Anwendung statistischer und prädiktiver Methoden (PCA, Clustering y PLS-DA) auf Weindaten, um zu erhalten, welche Faktoren bei der Herstellung eines guten Weins am meisten Einfluss haben.
Miquel Marín Colomé & Álvaro Mazcuñán Herreros
1 – BESCHREIBUNG DER STUDIE UND DER DATENBANK
1.1 – STUDIENBESCHREIBUNG
Die folgende Arbeit bezieht sich auf eine Datenbank, die sich mit der Sorte Rot- und Weißwein des portugiesischen 'Vinho Verde' befasst.. Die Weinzertifizierung umfasst physikalisch-chemische Tests wie, Dichtebestimmung, pH, Menge Alkohol, etc. Mit diesem Projekt, Sie möchten die Variablen untersuchen, die bei der Analyse der Qualität eines Weins den größten Einfluss haben, Wenn ist schlecht, gut / fair oder sehr gut.
1.2 – BESCHREIBUNG DER DATENBANK
Die Datenbank besteht aus 12 Variablen und 4858 Beobachtungen. Die meisten Variablen sind physikochemische Komponenten, aus denen Weine hergestellt werden. Diese Variablen sind wie folgt:
- Feste Säure
- Flüchtige Säure
- Zitronensäure
- Restzucker
- Chloride
- Freies Schwefeldioxid
- Gesamtschwefeldioxid
- Dichte
- pH
- Sulfate
- Alkohol
Diese oben angegebenen Variablen sind stetig. Ein Teil, Eine Ziel- oder Antwortvariable ist verfügbar. Diese Variable entspricht der Bewertung des Weins und ist diskret. Nimm Werte von 0 ein 10.
2 – ERSTE EXPLORATORISCHE UND VORVERARBEITETE ANALYSE DER DATEN
2.1 – FEHLENDE DATEN
Zuerst, Zuerst, Es wird untersucht, ob Werte in der Datendatei fehlen. Es wird mit der folgenden Funktion überprüft und es wird festgestellt, dass es keinen Wert dieses Typs gibt.
## [1] 0
2.2 – TRANSFORMATION VON VARIABLEN
Eine der durchgeführten Transformationen war die der variablen Qualität des Weins. Wie du siehst, Es gibt nur wenige Werte dieser Beobachtungen, die sie als Bewertung heranziehen 3, 4, 8 Das 9.
## 3 4 5 6 7 8 9
## 20 163 1447 2178 870 175 5
So, Es wurde beschlossen, die Werte zu gruppieren, die diese Variable annimmt 3 verschiedene Gruppen:
- Gruppe 1: Weine mit einer Bewertung von 3 Das 4. Sie gelten als „schlechte“ Weine
- Gruppe 2: Weine mit einer Bewertung zwischen 5 und 7. Sie gelten als „gute“ Weine
- Gruppe 3: Weine mit einer Bewertung von 8 Das 9. "Sehr gute" Weine werden berücksichtigt
2.3 – VARIABLEN UND / ODER VERWorfenE AUFZEICHNUNGEN
Eine frühere Untersuchung der Datenbank wurde durchgeführt und es wurde beschlossen, seitdem keine der Variablen mehr zu entfernen, Auf der einen Seite, sie sind alle wichtig und, für andere, nur haben 12, Das Löschen eines dieser Elemente kann zu einem Informationsverlust bei der Durchführung der Studie führen.
2.4 – VERTEILUNG VON VARIABLEN
Dann, Jede der verfügbaren Variablen wird beobachtet, studieren, ob es existiert, a priori, einige anomale oder extreme Daten in ihnen.
Beim Im Anhang 8.3: Analyse der variablen Verteilung alles wird genauer erklärt, Analysieren, ob die Daten Normalität oder Asymmetrie aufweisen, zusätzlich zum Kurtosis-Koeffizienten.
A priori, anomale Daten werden nicht beobachtet. Als einziges Detail, Im Dichtediagramm ist zu sehen, dass alle Beobachtungen Werte annehmen 1.
Dies sind einige der Dichtewerte einiger Weine.
- Trockener Weißwein: 0,9880-0,9930 g / ml.
- Trockener Rotwein: 0,9910-0,9950 g / ml.
- Schaumwein: 0,9890-1,0080 g / ml.
- Schnapswein (moscatel): 1,0500-1,0700 g / ml.
So, Es ist ein normaler Wert.
2.5 Skalieren und Zentrieren von Daten
Nach einer kleinen explorativen Analyse der Daten in dieser Datei, es wird bereits an den Teil der Vorverarbeitung übergeben, wichtiger Teil vor der Durchführung der entsprechenden Analysen.
Die Originaldaten werden mit den Daten verglichen, sobald sie zentriert und skaliert sind, um zu sehen, ob die Variablen in unterschiedlichen Größen gemessen werden. Daten werden zentriert und skaliert.
Dann, Die beiden Diagramme, mit denen der Vergleich durchgeführt wird, werden im selben Fenster gedruckt, mit der Drehmomentfunktion. Es ist ersichtlich, wie einige der Variablen in unterschiedlichen Größen gemessen werden, beispielsweise, die zwei Arten von Schwefel. So, zur weiteren Analyse, Es werden zentrierte und skalierte Daten verwendet.
3. ANALYSE 1 – HAUPTKOMPONENTENANALYSE (PCA)
Sobald die explorative Analyse durchgeführt wurde und die Daten zentriert und skaliert wurden, Sie können zur ersten der drei Analysen gehen, die in diesem Projekt des Themas durchgeführt werden. Der erste von ihnen, wie der Titel schon sagt, ist die Hauptkomponentenanalyse. Die Nützlichkeit dieser Methode ist zweifach:
- Optimal auf kleinem Raum rendern, Beobachtungen eines p-dimensionalen allgemeinen Raums. Dies ist der erste Schritt, um mögliche „latente“ oder nicht beobachtete Variablen zu identifizieren, das erzeugt die Variabilität der Daten.
- Ermöglicht die Transformation der ursprünglichen Variablen, im Allgemeinen korreliert, in neuen unkorrelierten Variablen, Erleichterung der Interpretation von Daten.
3.1 ZIELE
Das Ziel bei Verwendung dieser Technik besteht darin, die Variablen zu erhalten, die die Dimensionen am meisten beeinflussen, die die größte Variabilität erklären. Mit dieser Methode erhalten Sie eine genauere Ansicht des Verhaltens der verarbeiteten Daten. Ein Teil, An einigen Weinen mit extremen Daten wird eine kleine Studie durchgeführt.
3.2 ANWENDUNG DER METHODE / NUMERISCHE UND GRAFISCHE ERGEBNISSE
SCREE-PLOT
Es geht weiter zur Anwendung der Methode. All dies erfolgt über die bereits in R implementierte PCA-Funktion. Daten werden nicht skaliert, da dies bereits zuvor geschehen ist.
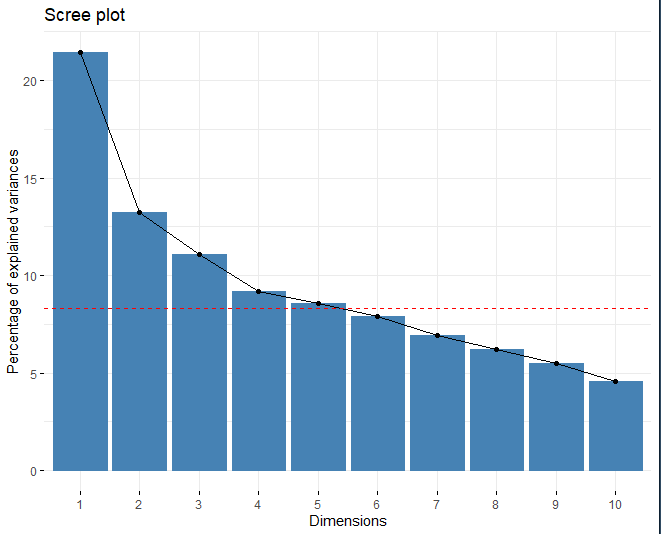
## Eigenwert Varianz.Prozent kumulativ.Varianz.Prozent
## Dim.1 2.571633 21.434687 21.43469
## Dim.2 1.585109 13.211958 34.64665
## Dim.3 1.330253 11.087723 45.73437
## Dim.4 1.102265 9.187435 54.92180
## Dim.5 1.029659 8.582255 63.50406
Die Methode wird angewendet und es wird beobachtet, wie die ideale Anzahl von Hauptkomponenten ist 5. Auf der einen Seite, mit dem Geröllplot, Die rote Linie schneidet in die fünfte Dimension. Andererseits, Eine andere Technik zur Auswahl der geeigneten Anzahl von Dimensionen besteht darin, diejenigen Komponenten zu erhalten, deren Eigenwert größer als ist 1. Auch, Wenn man eine Tabelle mit dem Eigenwert erhält, der jeder der Dimensionen entspricht, ist dies ersichtlich, von der fünften Komponente, der Eigenwert ist größer als 1.
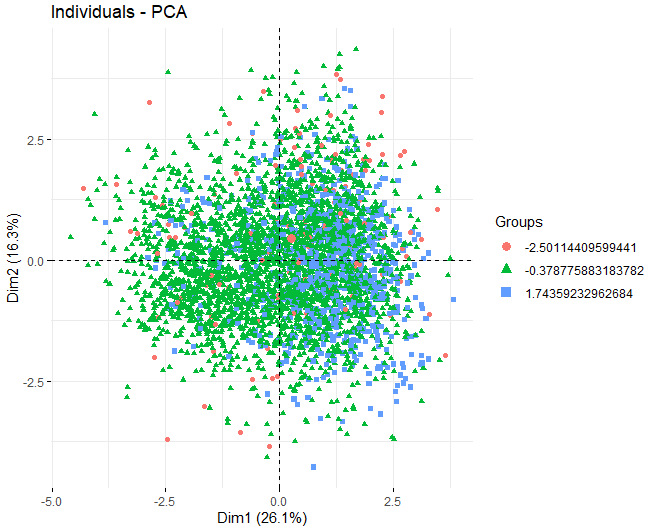
SCORE-PLOT
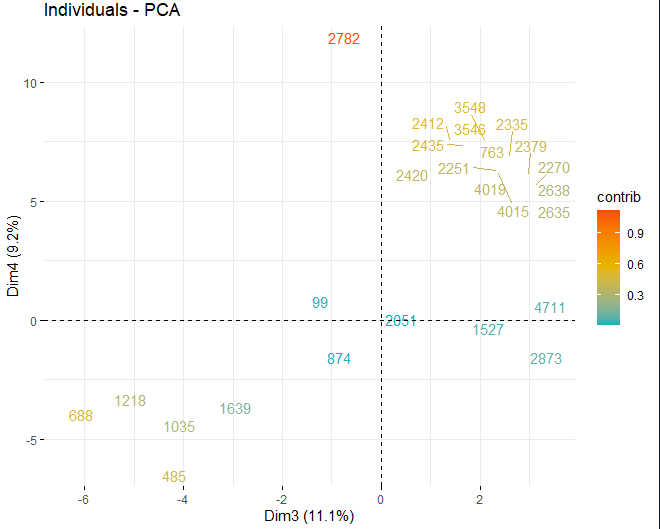
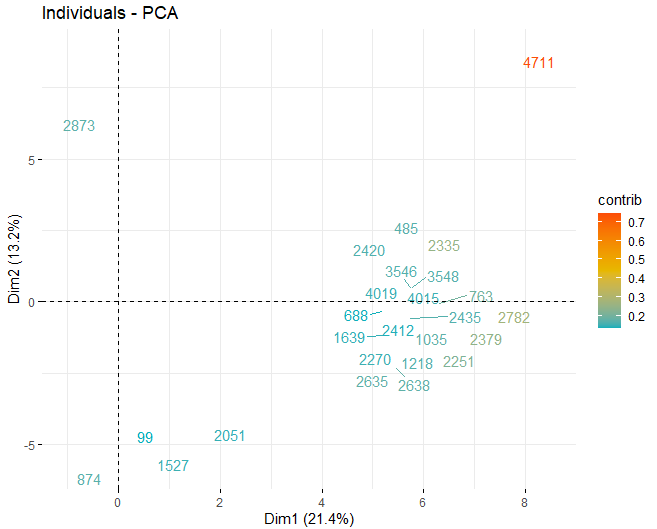
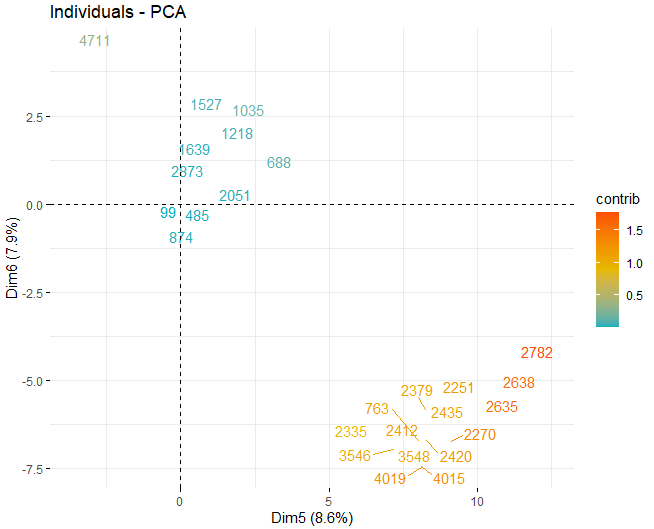
Dann, Es wird ein Bewertungsdiagramm mit den Bewertungen der Weine in jeder der zuvor erhaltenen Dimensionen erhalten. Diese Weine werden durch ihren Beitrag in den Komponenten gefärbt.
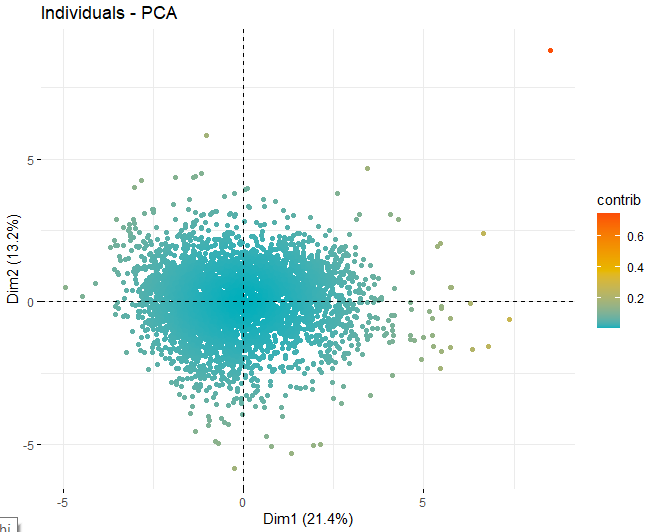
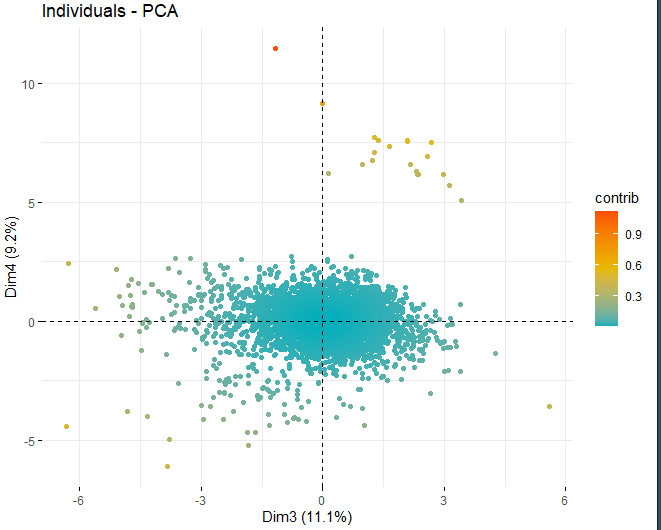
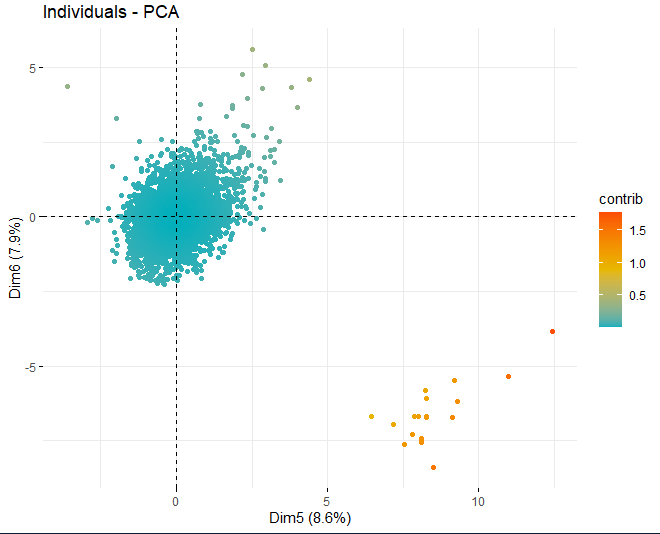
Es ist ersichtlich, dass die verschiedenen Komponenten einige anomale Werte aufweisen, abgesehen von ein paar extremen Beobachtungen, die eine Punktzahl schlagen, im absoluten Wert, größer als 5 und sogar von 10. Um mehr Informationen über diese anomalen Beobachtungen zu erhalten, Sie erhalten weiterhin die gleichen Score-Plots wie zuvor, aber, in diesem Fall, nur bei Beobachtungen, die eine Punktzahl überschreiten, im absoluten Wert, von 5.
T2 HOTELLING
Einige Beobachtungen, speziell die Weine 4711, 2782 Das 2635, Sie haben sehr extreme Werte, die, wenn sie in der Datenbank verbleiben, kann die Schlussfolgerungen zukünftiger Analysen verfälschen. Spezifisch, Alle Beobachtungen, die eine Grenze der 99% mit Hotellings T2.
Dann, Sie können einige der Weine sehen, die diese Grenze überschreiten.
Es wird beobachtet, dass es gibt, Spezifisch, insgesamt 156 Beobachtungen, die die überschreiten 99%. 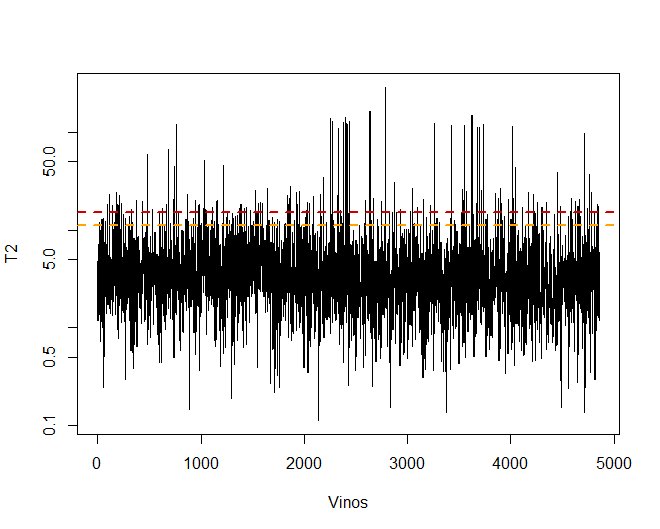
## [1] 156
So, zur besseren Analyse, Diese Weine werden eliminiert.
## [1] 4702 12
Dann, Es wird eine Hilfsvariable erstellt, in der die Qualitätsvariable gespeichert wird, zur Verwendung in der folgenden Farbanalyse.
In diesem Fall, Beobachtung der "und" -Achse der Boxplots, Entfernen der vorherigen Werte, Extremwerte existieren nicht mehr. 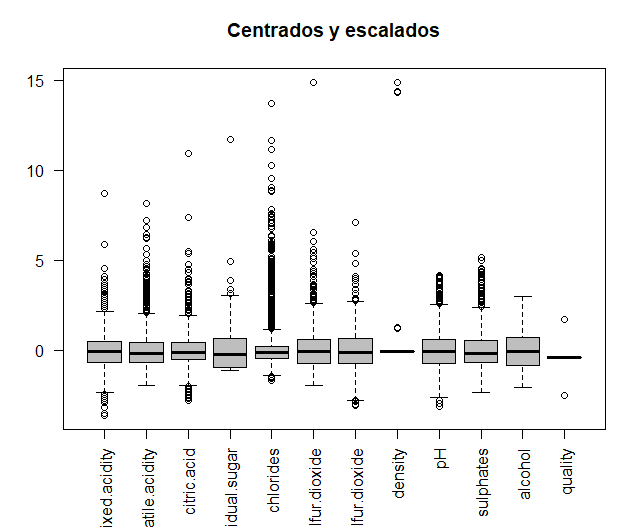
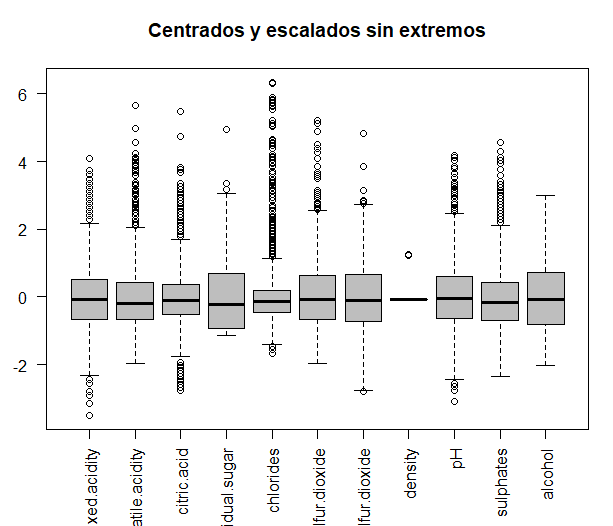
Jetzt müsste die PCA erneut durchgeführt werden, mit den neuen Beobachtungen. In diesem Fall, nach den gleichen Kriterien wie zuvor (unter Verwendung des Geröllplots und der Eigenwerte jeder der Dimensionen), werden erhalten 3 Hauptkomponenten, da sie einen Eigenwert größer als haben 1.
## Eigenwert Varianz.Prozent kumulativ.Varianz.Prozent
## Dim.1 2.3094622 26.079639 26.07964
## Dim.2 1.4442754 16.309503 42.38914
## Dim.3 1.0534806 11.896446 54.28559
## Dim.4 0.8526690 9.628779 63.91437
## Dim.5 0.8060166 9.101956 73.01632
LADEPLAN
Sobald die entsprechenden Abmessungen erreicht wurden, Es werden die Belastungsdiagramme jeder der zuvor erhaltenen Dimensionen erhalten: 
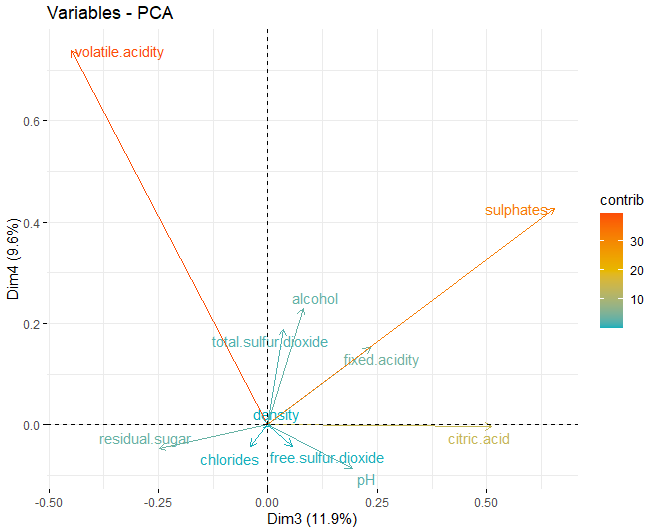
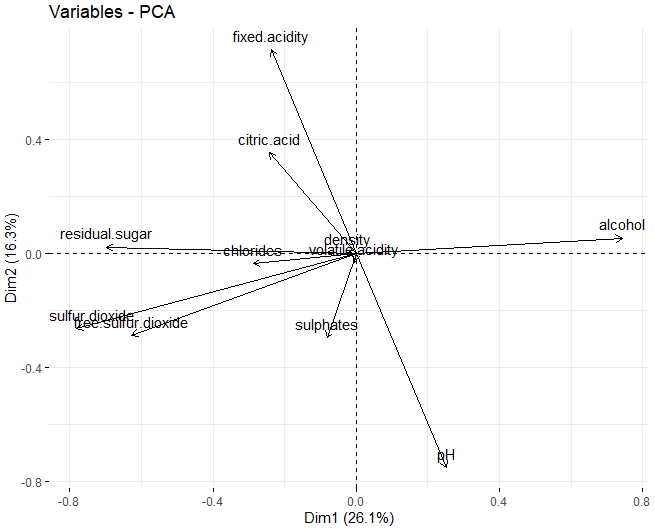
In diesem Fall ist das zu sehen, in der ersten Dimension, Die Variablen, die diese Dimensionen am meisten beeinflussen, sind die physikochemischen Komponenten von Alkohol, Restzucker und die beiden Arten von Schwefel, sowohl kostenlos als auch total. Andererseits, in der zweiten Dimension, Diejenigen, die den größten Einfluss haben, sind sowohl der pH-Wert als auch der feste Säuregehalt.
3.3 DISKUSSION DER ERGEBNISSE
Bei diesem ersten Ziel wurde beobachtet, dass aufgrund der anomalen Beobachtungen, die unter Verwendung des Hotelling T2 auftreten können, mehr als eine PCA-Analyse durchgeführt werden muss.. Wenn diese Ergebnisse ignoriert wurden, Wahrscheinlich würden die Diagramme der Bewertungen und Belastungen nicht auf die gleiche Weise interpretiert und es würden Ergebnisse erhalten, die nicht ganz real wären.
Abgesehen davon, mit dieser Technik, Es war möglich, eine detailliertere Ansicht der Datenbank zu erhalten, die verarbeitet wird, Analyse der Variablen, die die Erstellung von Dimensionen am meisten beeinflussen. Es wurde beobachtet, dass dies Alkohol ist, Restzucker und die beiden Arten von Schwefel, freier Schwefel und insgesamt.
4. ANALYSE 2 – CLUSTERING
4.1 ZIELE
Die zweite Analyse, die in diesem Projekt durchgeführt wird, ist die Analyse von Konglomeraten oder die Clusteranalyse. Das Ziel bei der Anwendung dieser Technik besteht insbesondere darin, herauszufinden, welche Eigenschaften bei der Bewertung der Qualität eines Weins unter Verwendung hierarchischer Clustering-Techniken und Partitionierungsalgorithmen am wichtigsten sind.. In Bezug auf diese Datenbank, Ziel ist es, die chemischen Variablen zu erhalten, die den Wert beeinflussen, den die Antwortvariable letztendlich annimmt, das heißt, la variable Qualität.
Schließlich, Sie erhalten eine farbige Grafik für die Qualität, wenn wirklich zu studieren, die Cluster, die diese Variablen bilden, Sind sie gut getrennt oder nicht?.
4.2 ANWENDUNG DER METHODE – NUMERISCHE ERGEBNISSE
4.2.1 GRUPPIEREN DER DATEN – HOPKINS STATISTIC
Zuerst, vor der Anwendung des Verfahrens, Sie müssen untersuchen, ob die verarbeiteten Daten eine Gruppierung enthalten. Dies kann unter Verwendung des Hopkins-Koeffizienten erfolgen. Es muss daran erinnert werden, dass je näher dieser Koeffizient von 1, Weitere Gruppierungen sind in den Daten vorhanden.
Die bereits in R implementierte Hopkins-Funktion wird aber verwendet, Du musst vorsichtig sein, weil diese Funktion den Koeffizienten auf etwas andere Weise erhält. Berechnen Sie die Statistik rückwärts, das heißt, der reale Wert dieses Koeffizienten ist 1-H. So, in diesem Fall 1-0.08 = 0.92. Wodurch, Man kann sagen, dass die Daten eine große Gruppierung aufweisen.
## $H.
## [1] 0.1029338
4.2.2 HCPC – HIERARCHISCHES CLUSTERING AUF PRINZIPALEN KOMPONENTEN
Der HCPC ist ein Algorithmus, der ähnliche Personen in Clustern gruppiert, jedoch mit einer Besonderheit, wird gemacht, um mit den Ergebnissen einer Hauptkomponentenmethode zu arbeiten. Dieser Algorithmus ermöglicht das Erhalten einer optimalen Anzahl von Clustern unter Verwendung einer auf Trägheit basierenden Technik.. Beim Im Anhang 8.1: Literaturverzeichnis Ein Link ist für weitere Informationen dazu beigefügt.
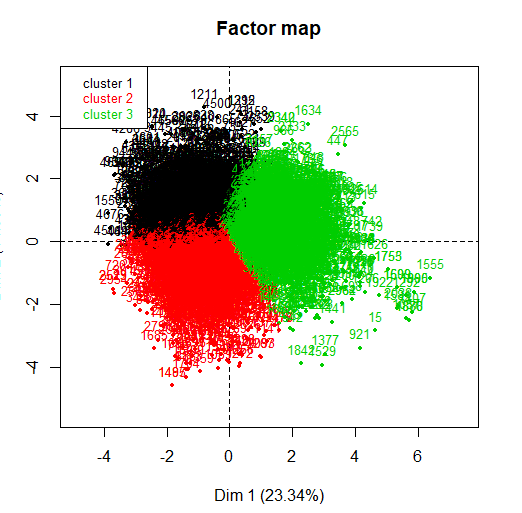
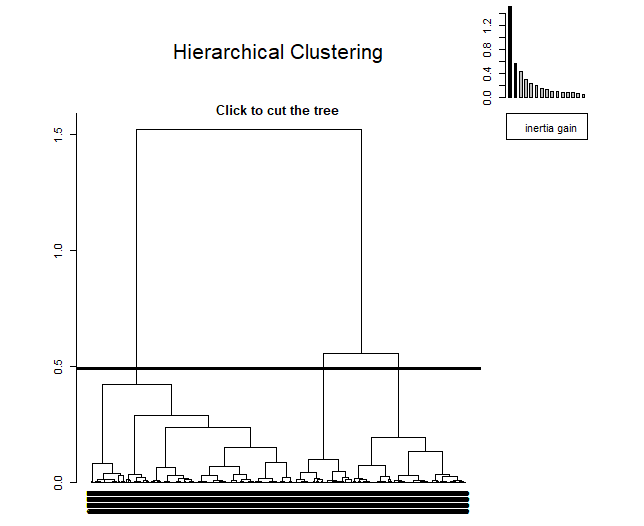
Bei der Anwendung, kann als gesehen werden, oben rechts, Ein kleines Diagramm zeigt die Trägheit in jeder der Dimensionen an. Die Methode entscheidet sich seitdem für drei Cluster, von der dritten Komponente, Trägheit bleibt erhalten.
4.2.3 ERHALTEN DER ENTFERNUNGSMATRIX
Nach der Vorstellung einer ersten Technik, um die optimale Anzahl von Clustern zu erhalten, Wir fahren fort, um die Distanzmatrix zu erhalten, Verwendung der euklidischen Distanz, da das Ziel darin besteht, Weine mit ähnlichen Eigenschaften wie zu finden, später, untersuchen, ob sie als gut oder schlecht eingestuft sind.
4.2.4 Ward-Methode
Zuerst, Wards Methode wird angewendet. Die erste Methode hat die gefunden 3 als optimale Anzahl von Clustern, so, k = 3 wird zugewiesen.
## Gruppen1
## 1 2 3
## 1743 2031 928
Es kann beobachtet werden, dass, unter Verwendung dieser Methode, Die drei gebildeten Gruppen scheinen gut gruppiert zu sein, Keine scheinbar anomalen Daten.
Dann, Elbow- und Silhouette-Methoden werden verwendet, um die optimale Anzahl von Clustern für die Ward-Methode zu validieren. 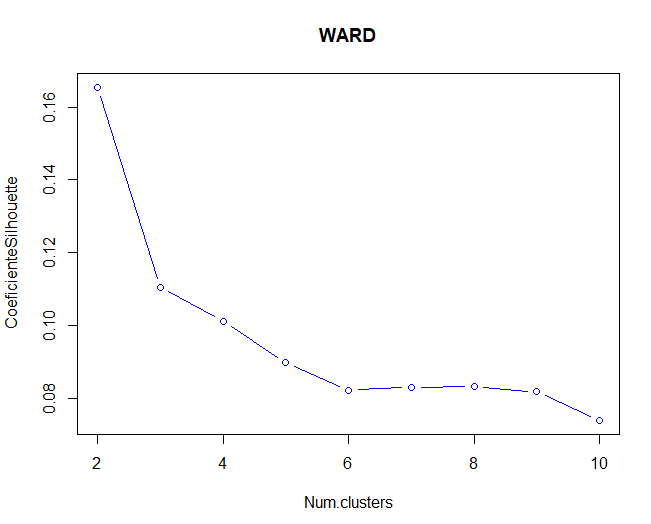
Es wird beobachtet, dass, sowohl für die Silhouette-Methode als auch für die Ellbogenmethode (obwohl es nicht so klar scheint), Die optimale Anzahl von Clustern wäre 2 Cluster. In diesem Fall, mit zwei Clustern, mehr als 1000 Beobachtungen in einer Gruppe relativ zu einer anderen.
## Gruppen1b
## 1 2
## 1743 2959
4.2.5 K-MEANS
Als nächstes wird eine andere Methode untersucht, in diesem Fall die Kmeans- oder Kmedias-Methode. Wie es mit Wards Methode gemacht wurde, In diesem Fall wird auch k = 3 zugewiesen. Eine gute Gruppierung der Daten wird auch unter Verwendung von drei Clustern beobachtet..
##
## 1 2 3
## 1683 1475 1544
Die optimale Clustering-Methode wird mit dieser Methode erhalten., auch mit Silhouette-Koeffizient und Ellbogenmethode. 
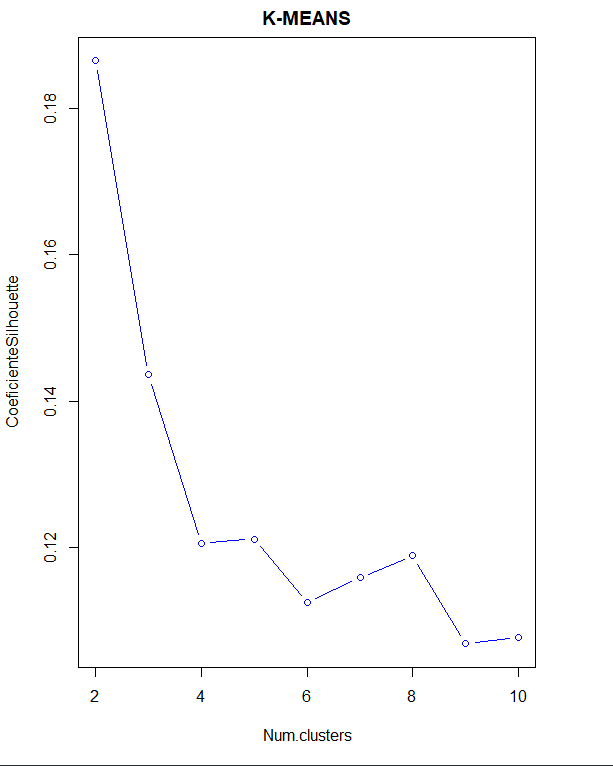
In diesem Fall, in der Ellbogenmethode, Sie sehen keinen so definierten Ellbogen. jedoch, Studium des Silhouette-Koeffizienten, gibt an, dass die Anzahl der Cluster ist 2 nochmal.
4.3 OPTIMALE ANZAHL DER CLUSTER – Validierung der Ergebnisse
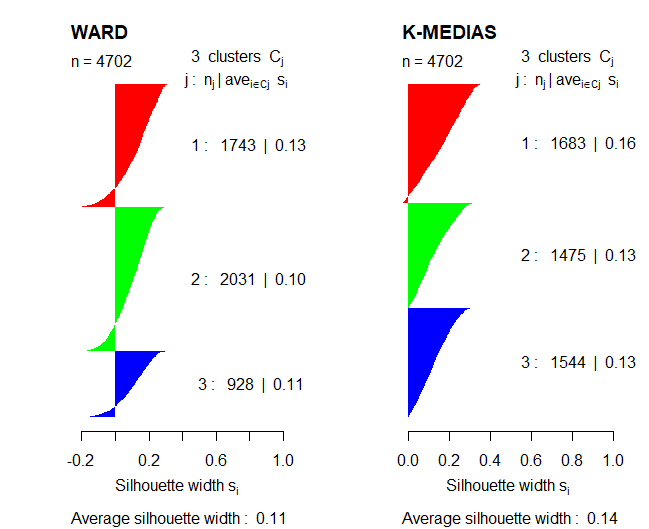
Nach dem Studium einiger Methoden, um die optimale Anzahl von Clustern zu erhalten, Diese Methoden werden mit dem Silhouette-Koeffizienten verglichen, um die Ergebnisse zu validieren.
Vergleich der beiden Darstellungen, Sie können die Partitionsmethode mitteilen, der k-means-Algorithmus, funktioniert besser als die hierarchische Methode von Ward, da der Koeffizient von Silhouette in diesem Fall höher ist. Ebenfalls, im Fall von Wards Methode, Einige Beobachtungen erscheinen mit negativen Werten im verwendeten Koeffizienten.
So, im nächsten Abschnitt, Die Interpretation der Clustering-Ergebnisse wird mit der K-Means-Methode untersucht. Ebenfalls, Dieser Algorithmus wird mit verwendet 3 Cluster seit, vorher, es wurde beobachtet, dass mit diesem K-Wert, Gruppen waren ausgeglichener, keine anomalen Werte.
4.4 GRAFISCHE ERGEBNISSE
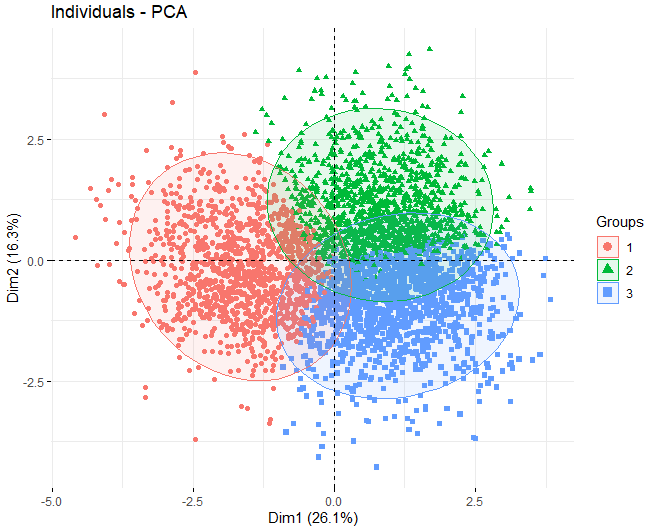
Nachdem kommentiert wurde, dass die K-Mittel-Methode verwendet wird, Wir erhalten eine PCA, um festzustellen, welche Variablen am meisten zur Bildung der Cluster beitragen. In diesem Fall, Es kann beobachtet werden, dass, unter Verwendung des k-means-Algorithmus mit 3 Cluster, das 3 Gruppen trennen sich sehr gut, Sie sind ausgeglichen.
Es kann beobachtet werden, dass, in den ersten beiden Dimensionen, Die Variablen, die die Bildung von Clustern am meisten beeinflussen, sind Restzucker, der Alkohol, und die zwei Arten von Schwefel, sowohl Gesamtschwefel als auch freier Schwefel.
Schließlich, Anschließend zeigen wir eine Grafik, in der jeder der Weine dargestellt wird, um festzustellen, ob die Qualitätsvariable die Bildung der Cluster beeinflusst. Sie können sehen, dass die Cluster nicht gut getrennt sind, Die meisten Punkte überschneiden sich mit anderen.
4.5 DISKUSSION DER ERGEBNISSE
Durch diese Technik wurde beobachtet, dass die Qualitätsvariable die Erzeugung der Cluster nicht beeinflusst. Dies könnte auf verschiedene Faktoren zurückzuführen sein, die von Anfang an in der Analyse nicht berücksichtigt wurden.. Cluster können gemäß anderen Variablen wie z, die Ursprungsbezeichnung, die Art der Traube, aus der diese Weine hergestellt werden, etc.
5 ANALYSE 3 – TEILWEISE MINDESTQUADRATE – DISKRIMINANTE ANALYSE (PLS-DA)
Die PLS-Technik ist eine Mischung aus multipler Regression und PCA. Denken Sie daran, dass bei Multikollinearität, Die Regression wird möglicherweise nicht korrekt durchgeführt und die gewünschten Ergebnisse werden möglicherweise nicht angezeigt. jedoch, Das PLS verwendet zuvor die PCA, um zu beobachten, welche Variablen bei der Erstellung der untersuchten Variablen den größten Einfluss haben, und jede der Komponenten ist orthogonal zu der nächsten, die am meisten Einfluss hat, und so weiter. Aus diesem Grund, dank der Tatsache, dass die Komponenten linear unabhängig voneinander sind, Die Regression kann problemlos durchgeführt werden.
Eine der PLS-Varianten ist der PLS-DA, Welches ist dasjenige, das in diesem Projekt verwendet werden soll, welches die Diskriminanzanalysetechnik einschließt. Der Unterschied, in Bezug auf den Stand der Technik, ist, dass die Antwortvariable kategorisch ist. Aus dieser kategorialen Variablen werden so viele "Dummy" -Variablen erstellt, wie es unterschiedliche Werte gibt, die die Antwortvariable annehmen kann..
5.1 ZIELE
Das Ziel bei der Verwendung dieser Technik ist zweierlei. Auf der einen Seite, mögliche anomale Beobachtungen untersuchen (dann, Es wird erklärt, wie man sie behandelt). Andererseits, Bewerten Sie die Vorhersagekapazität eines PLS-DA-Modells mit der Weinqualitätsvariablen.
In der ersten Technik, die verwendet wurde, die der PCA, es wurde beobachtet, dass, mit Hotellings T2, Es erschienen einige Beobachtungen, die die 99%, unter Berücksichtigung anomaler und extremer Beobachtungen derjenigen, die am weitesten von diesem Schnitt entfernt waren. Ein ähnliches Verfahren wird im PLS durchgeführt. zuerst, ein erstes PLS-Modell wird hergestellt und, unter Verwendung der Hotelling T2-Technik, mögliche anomale oder extreme Beobachtungen werden untersucht.
Alle Beobachtungen, die die Grenze des 99% Wenn Sie Hotellings T2 verwenden, wird erneut ein neues PLS-Modell erstellt, um ein zuverlässigeres Modell als ein anderes mit anomalen Fällen zu erhalten, die seine Eigenschaften verändern können.
5.2 ANWENDUNG DER METHODE
Es ist bereits an die Anwendung des Modells übergeben. Zuerst müssen Sie die Antwortvariable in Faktor umwandeln, da, obwohl es qualitativ ist, Das Programm erkennt es nicht so, da es numerische Werte annimmt.
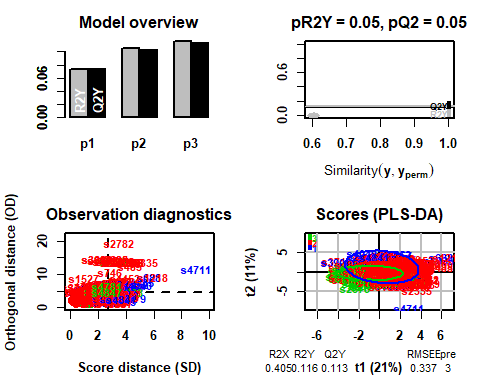
Einmal angewendet, Sie können sehen, wie das Modell kommt 3 als ideale Anzahl von Komponenten.
## PLS-DA
## 4858 Proben x 11 Variablen und 1 Antwort
## Standardskalierung von Prädiktoren und Antwort(s)
## R2X(cum) R2Y(cum) Q2(cum) RMSEE für oder pR2Y pQ2
## Gesamt 0.405 0.116 0.113 0.337 3 0 0.05 0.05
5.2.1 T2-HOTELLING
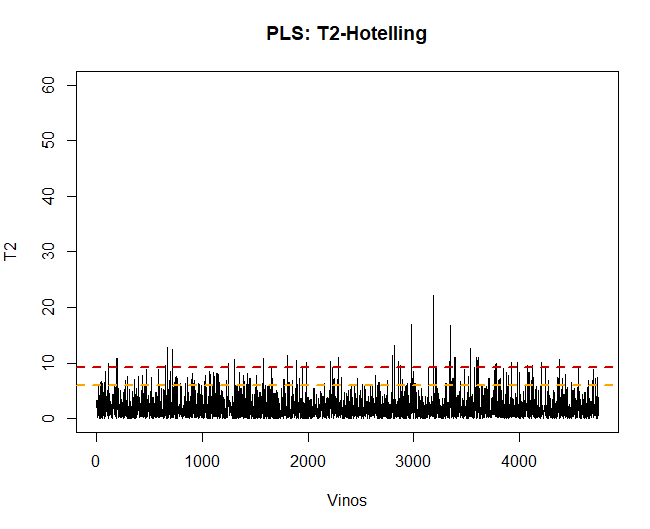
Das erste was zu tun ist, Sobald das Modell angewendet wird, ist die Validierung der Daten, Beobachten Sie, ob es abnormale oder extreme Beobachtungen gibt, die die Ergebnisse beeinflussen können. Dafür, Es wird ein Diagramm von Hotellings T2 erstellt, das sie erkennen kann.
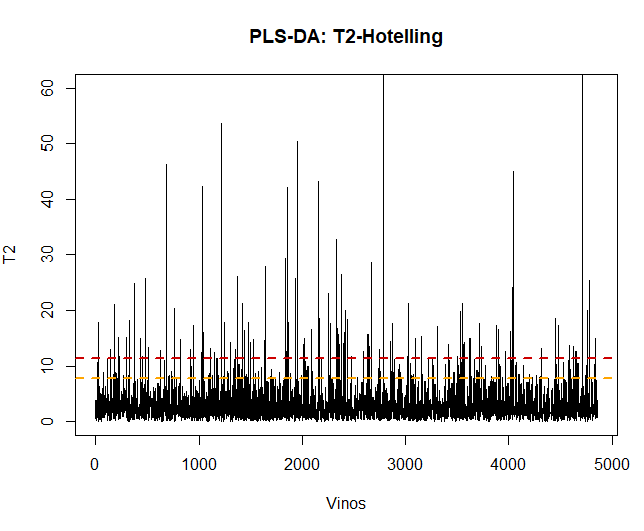
Mit dieser Technik, Sie können sehen, dass es einige gibt 100 anomale Beobachtungen. Diese Daten werden entfernt und das PLS-DA-Modell wird erneut angewendet.
## [1] 109
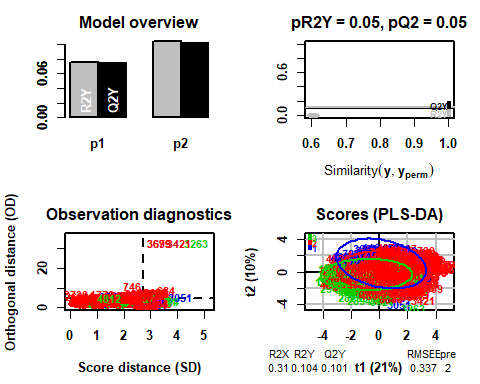
5.3 ANWENDUNG DER METHODE OHNE ABNORMALE DATEN
In diesem Fall können Sie das sehen, Entfernen der vorherigen Beobachtungen, Das Modell wählt in diesem Fall 2
## PLS-DA
## 4749 Proben x 11 Variablen und 1 Antwort
## Standardskalierung von Prädiktoren und Antwort(s)
## R2X(cum) R2Y(cum) Q2(cum) RMSEE für oder pR2Y pQ2
## Gesamt 0.31 0.104 0.101 0.337 2 0 0.05 0.05
5.3.1 T2-HOTELLING
Wenn das Hotelling T2-Diagramm jetzt angezeigt wird, Es gibt keine anomalen Daten mehr, die das Modell beeinflussen können.
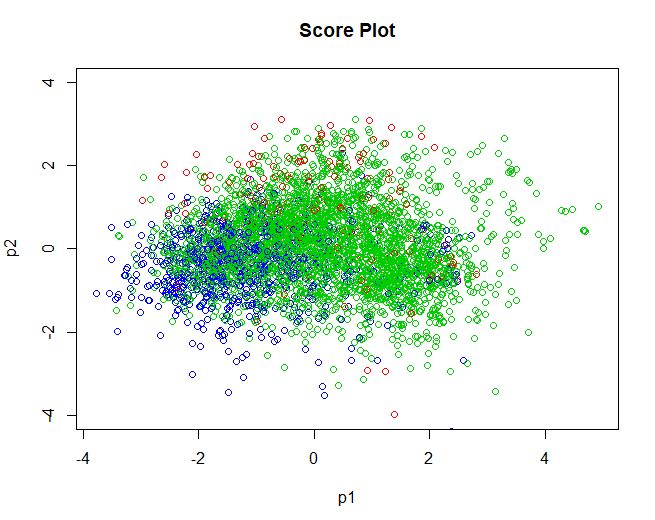
5.3.2 SCORE-PLOT
Sobald die Daten validiert sind, Wir erhalten dann das Score-Diagramm, in Bezug auf Einzelpersonen. Es werden sehr ähnliche Ergebnisse erhalten wie mit dem in der Analyse verwendeten k-Mittelwert-Algorithmus 2. Gruppen sind nicht klar getrennt, die meisten überlappen sich. Wie in der vorherigen Analyse erwähnt, Dies kann daran liegen, dass die Gruppen nicht nach Qualität getrennt sind, aber durch andere Variablen, die in dieser Analyse nicht angeordnet wurden, wie die Ursprungsbezeichnung des Weins, die Art der Traube, aus der es hergestellt wurde, etc.
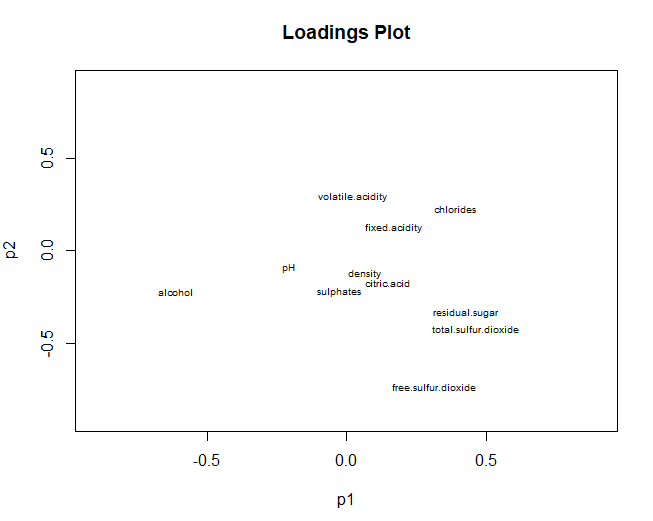
5.3.3 LADEPLAN
Andererseits, Wir gehen weiter, um das Ladungsdiagramm grafisch darzustellen, unter Bezugnahme auf Variablen. In diesem Fall sind die Ergebnisse denen der Hauptkomponentenanalyse sehr ähnlich.. Gesamtschwefel, freier Schwefel und Alkohol, haben einen hohen Beitrag in beiden Dimensionen. jedoch, Mit PLS-DA wird erhalten, dass der pH-Wert in keiner der beiden Komponenten einen Beitrag leistet (in PCA hatte einen großen Beitrag in der zweiten Komponente)
5.4 PLS-DA-MODELLVORHERSAGE
In diesem vierten Abschnitt wird die Vorhersage des in dieser dritten Analyse verwendeten Modells vorgenommen.. Indem ich welche habe 5000 Beobachtungen, Anschließend erstellen wir ein Trainingsset und ein Testset.
## PLS-DA
## 3800 Proben x 11 Variablen und 1 Antwort
## Standardskalierung von Prädiktoren und Antwort(s)
## R2X(cum) R2Y(cum) Q2(cum) RMSEE für oder pR2Y pQ2
## Gesamt 0.307 0.0982 0.0937 0.338 2 0 0.05 0.05
5.4.1 TRAININGSSET
Trainingsdaten verwenden, Es ist ersichtlich, dass das Modell eine Genauigkeit von hat 76,55%, Das ist ein sehr akzeptabler Wert. jedoch, Schauen Sie sich die Beobachtungen, die Sie für jede der Gruppen vorhersagen, genau an. Dieser Präzisionswert ist hoch, da fast alle Weine der Gruppe gut klassifiziert werden. 2 ("Gut" mit einer Bewertung zwischen 5 und 7). Klassifiziert 2801 Weine in der Gruppe 2, und das 43 verbleiben zu gruppieren 3.
jedoch, der ersten Gruppe hat keine dieser gut klassifiziert (120 in der Gruppe 2 und 1 in der Gruppe 3). Schließlich, in der Gruppe 3 hat klassifiziert 108 Beobachtungen dieser Gruppe und 727 für die Gruppe 2.
So, Man kann sagen, dass das Modell die Weine der zweiten Gruppe sehr gut vorhersagt. Fällig, Der Präzisionswert ist hoch.
## Verwirrungsmatrix und Statistik
##
## mypred
## 1 2 3
## 1 0 120 1
## 2 0 2801 43
## 3 0 727 108
##
## Gesamtstatistik
##
## Richtigkeit : 0.7655
## 95% CI : (0.7517, 0.7789)
## Keine Informationsrate : 0.96
## P-Wert [Acc > NIR] : 1
5.4.2 TEST SET
Schließlich, um das Modell zu validieren, das gleiche wird aber vorher gemacht, in diesem Fall, mit Beobachtungen hat das Modell bisher nicht gesehen (Testset)
Ein ähnlicher Trend wie beim Trainingssatz ist zu beobachten. Das Modell hat eine Genauigkeit von 76,92%, Wert sehr ähnlich dem im anderen Satz erhaltenen. jedoch, wie zuvor besprochen, Das Modell klassifiziert nur die Weine der Gruppe sehr gut 2 aber die anderen beiden Gruppen unterscheiden sie nicht gut.
## Verwirrungsmatrix und Statistik
##
## mypred
## 1 2 3
## 1 0 30 0
## 2 0 692 19
## 3 0 170 38
##
## Gesamtstatistik
##
## Richtigkeit : 0.7692
## 95% CI : (0.7411, 0.7957)
## Keine Informationsrate : 0.9399
## P-Wert [Acc > NIR] : 1
6 SCHLUSSFOLGERUNGEN
6.1 VERGLEICH DER VERWENDETEN METHODEN
Schließlich, In diesem Projekt wurden drei Methoden für die drei entsprechenden Analysen verwendet: Hauptkomponentenanalyse, Clustering y Partial Least Squares – Diskriminanzanalyse (PLS-DA).
Die erste Methode, die PCA, hat dazu gedient, eine Vorverarbeitung der Daten zu erhalten und auf diese Weise, um die Datenbank etwas gründlicher studieren zu können, Analyse der Variablen, die den größten Beitrag zu den erhaltenen Hauptdimensionen leisten. Ähnliche Ergebnisse konnten zwischen der PCA und der PLS-DA gefunden werden, das ist, Analyse des Ladeplots beider Techniken, Es wurden die gleichen Variablen erhalten, die mehr zu den beiden Techniken beigetragen haben, mit Ausnahme einiger Ausnahmen.
Andererseits, die PCA, dank der Reinigung, die in der Datenbank durchgeführt wurde, hat für die zweite Analyse gedient, Clustering, da es ermöglicht hat, die Cluster auf ausgewogenere Weise zu erhalten, Keine abnormalen Gruppen mit wenigen Beobachtungen.
Schließlich, die PLS-DA-Methode, zusätzlich zu dem, was zuvor zu den ähnlichen Ergebnissen mit der PCA kommentiert wurde, wurde verwendet, um die Vorhersagekapazität des Modells zu bewerten. Ein gutes erstes Modell wurde erhalten, sollte aber in Zukunft verbessert werden, weil Gruppen mit niedrigeren Beobachtungen nicht richtig vorhergesagt wurden.
6.2 DISKUSSION ÜBER NICHT ANGEWANDTE METHODEN
Drei Methoden wurden in diesem Projekt nicht verwendet: Faktorielle Analyse von Korrespondenzen (AFC), Assoziationsregeln und Diskriminanzanalyse. Die ersten beiden Techniken wurden nicht verwendet, da die für diese Arbeit verwendete Datenbank keine qualitativen Variablen enthielt. (nur die Antwortvariable, Weinqualität). Die Tatsache, dass alle Variablen transformiert wurden, könnte zu einem erheblichen Informationsverlust geführt haben.
Andererseits, Die Diskriminanzanalyse war auch eine gute Option, um die Variablen zu erhalten, die bei der Unterscheidung zwischen den verschiedenen Gruppen, in die die Weine eingestuft wurden, und anschließend am stärksten beeinflusst wurden, neue Beobachtungen klassifizieren. PCA und Clustering wurden bereits angewendet und, weil der Abschluss des PLS obligatorisch war, Diese Methode konnte nicht untersucht werden.
Schließlich, Die PLS-DA-Technik wurde innerhalb des PLS verwendet, da die Antwortvariable qualitativ war. Auf diese Weise wurde diese Variable als Y und die anderen physikalisch-chemischen Variablen als X verwendet.
7. ANDERE THEMEN
7.1 KOMMENTARE ZU LESEN VON ARTIKELN
Es konnte untersucht werden, dass sich die verschiedenen Gruppen aufgrund der Qualität nicht gut trennen. So, das gesehen, Es wurde beschlossen, ein wenig darüber zu recherchieren, wie diese Gruppe aussehen könnte. Durch einige Nachrichten und Artikel konnte festgestellt werden, dass die Qualität des Weins keine lineare Kombination der verfügbaren physikalisch-chemischen Variablen ist. So, Die Bewertung eines Weins ist nicht linear, hat Buggy-Trends. Diese Fehler werden von den Kriterien jedes Richters beeinflusst.
So, la Variable „Qualität“, im Falle von Bewertungen von Sachverständigen, Es hat bestimmte Ungenauigkeiten, die auf den Geschmack von jedem von diesen zurückzuführen sind.
8. ANHANG
8.1 LITERATURVERZEICHNIS
- Handbuch für Weinmerkmale
- Woher weiß ich, ob ich einen Qualitätswein genieße??
- HCPC
- Praktischer Leitfaden zu Hauptkomponentenmethoden in R. (Kassambara)
- FactoMineR
- MULTIVARIANTEN DATENANALYSE – Daniel Peña
- DIE ELEMENTE DES STATISTISCHEN LERNENS
8.2 VERTRIEBSANALYSE VON VARIABLEN
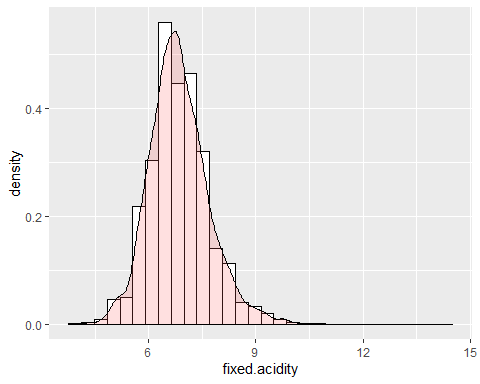
HISTOGRAMM DER FESTEN SÄURE
Die erste der Variablen ist der feste Säuregehalt. Diese Variable hat eine Asymmetrie von 0.647 aber eine Kurtosis von 5.16. Dies zeigt an, dass diese Variable keiner Normalverteilung folgt. Außerdem werden extreme Daten beobachtet, die den Wert von annehmen 14,2.
HISTOGRAMM FLÜCHTIGE SÄURE
Die flüchtige Säure hat eine ähnliche Form wie die vorherige Variable. Diese Variable hat eine Asymmetrie von 1,576 und eine Kurtosis von 8,08 was auch darauf hinweist, dass es keiner Normalverteilung folgt.
Es wird beobachtet, dass die beiden vorherigen Variablen lange und positive Schwänze haben und, aus diesem Grund, Der Mittelwert ist viel höher als er sein sollte. 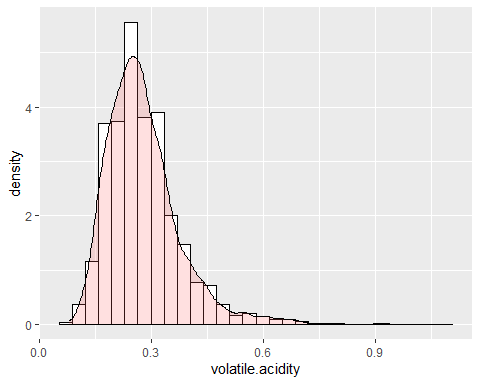
CITRUS ACID HISTOGRAM
In der Säure können einige atypische Daten beobachtet werden, wie z 1,66 g / dm ^ 3, das das Maximum der Variablen markiert. Abgesehen davon, eine Asymmetrie von 1,28 und eine Kurtosis von 9,16. So, es folgt auch keiner Normalverteilung.
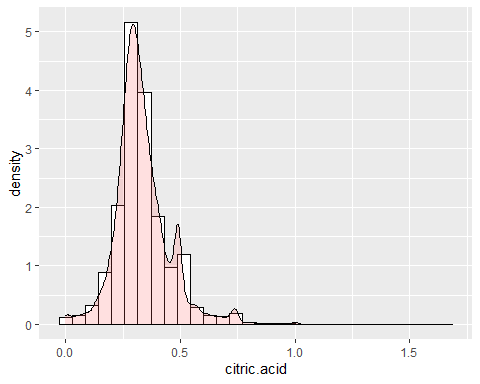
RESIDUAL SUGAR HISTOGRAM
Restzucker hat eine positive Tendenz. Es wird beobachtet, dass es eine Asymmetrie von hat 1,07 und eine Kurtosis von 6,46, das heißt, folgt keiner Normalverteilung. Es wird ein sehr hoher Peak beobachtet.
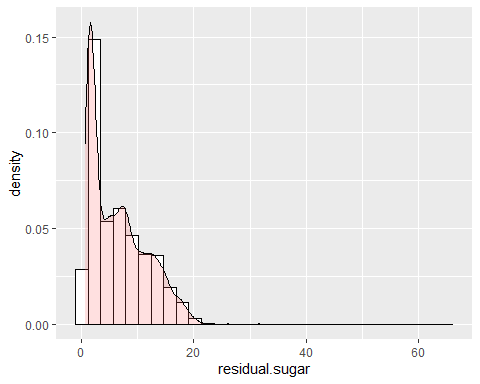
CHLORHISTOGRAMM
Chlor hat mehrere extreme Daten mit einem Kurtosis-Koeffizienten von 40,52. Es hat auch eine positive Asymmetrie mit einem Koeffizienten von 5,02. Daher ist diese Variable nicht gemäß der Gaußschen Glocke verteilt..
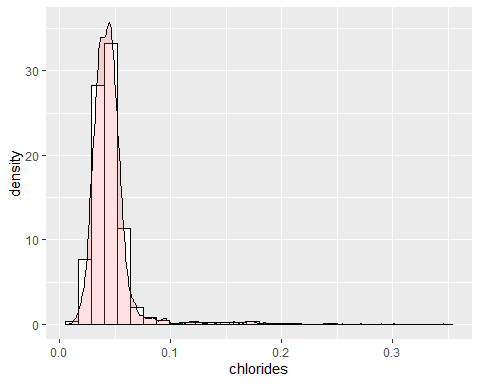
GESAMT- UND KOSTENLOSE SCHWEFELDIOXID-HISTOGRAMME
Verteilungen für Schwefeldioxid, sowohl kostenlos als auch total, sind symmetrisch, weil sie Schräglaufkoeffizienten von haben 1,40 und 0,39 beziehungsweise. In beiden Fällen liegen extreme Daten vor (knapp an 14,45 und 3,57). Sie folgen keiner Normalverteilung. 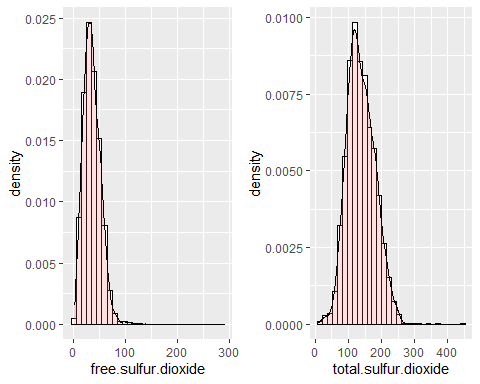
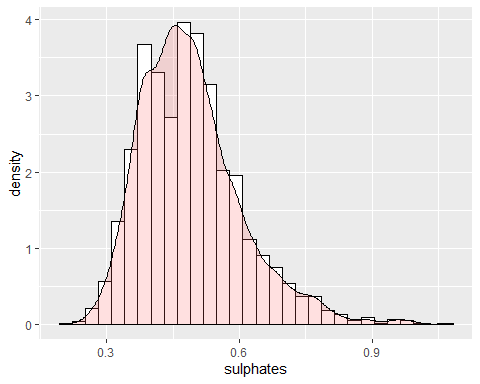
SULFATHISTOGRAMM
Sulfat hat eine positive Schiefe mit einem Koeffizienten von 0.9768. Da es einen Kurtosis-Koeffizienten hat, der höher als ist 2, anomale Daten existieren und, so, folgt keiner Glockea de Gauss.
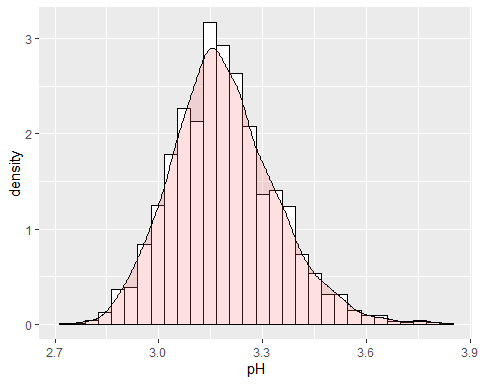
PH-HISTOGRAMM
Der pH-Wert des Weins liegt bei 3,15 mit einigen anomalen Daten, weil der Kurtosis-Koeffizient höher ist als 2.