
Anwendung statistischer und prädiktiver Methoden
(FAMD, Clustering y PLS-DA)
auf Herz-Kreislauf-Daten, um zu erfahren, welche Variablen Herzprobleme verursachen.
Angel Langdon & Ignacio Cano
1. Beschreibung der Studie und der Datenbank.
1.1 Studienbeschreibung
In dieser Studie wird eine Analyse der Beziehung zwischen einigen Variablen durchgeführt, die physikalische Eigenschaften des Zustands einer Person anzeigen. (später detailliert) und ob Sie ein Herzproblem haben oder nicht. So, Was sind die wichtigsten Variablen bei der Bestimmung, ob eine Person ein Herzproblem hat?. Ebenfalls, Es wird versucht, Personen nach ihrer körperlichen Verfassung in zwei Gruppen einzuteilen., ob sie ein Herzproblem hatten oder nicht. Die Möglichkeit der Vorhersage unter Verwendung eines PLS-DA-Modells wird ebenfalls untersucht..
1.2 Datenbankbeschreibung
Die Datenbank besteht aus 14 Variablen und 303 Beobachtungen. Die Variablen, mit denen wir umgehen, sind allgemein und leicht zu verstehen. Die meisten von ihnen befassen sich mit technischen Aspekten der Herzeigenschaften und des Gehalts bestimmter Substanzen, die Einfluss auf die Existenz von Herzerkrankungen haben.. Dann, das 14 Variablen für mehr Klarheit bei der Durchführung der Analyse, Darüber hinaus ist es wichtig zu wissen, worum es bei dem Thema geht, um eine gute Analyse durchzuführen.
- Alter: Das Alter der Person in Jahren
- Sex: Das Geschlecht der Person (1 = Macho, 0 = weiblich)
- Pain_chest: Die Art der Brustschmerzen erfahren
- Wert 0 - -> Angina typisch
- Wert 1 - -> Atypische Angina pectoris
- Wert 2 - -> Brustschmerzen, aber kein Angina-Typ
- Wert 3 - -> Asymptomatischer Schmerz
- (Angina = drückender Schmerz durch unzureichende Blutversorgung <> zu Herzzellen)
- p_sanguinea_mmHg: Der Ruheblutdruck der Person betrug bei Krankenhauseintritt mm Hg
- Cholesterin: Der Cholesterinspiegel der Person, gemessen in mg / dl
- Hyperglykämie: Blutzuckerspiegel (freie Glukose im Blut) Fastende Person (>120mg / dl, 1 = wahr ; 0 = falsch). Wenn es größer als 120 mg / dl ist, spricht man von Hyperglykämie, und wenn der Patient lange Zeit an Hyperglykämie leidet, trägt dies zur Entwicklung von Diabetes bei.
- elektro_repost: Ein ruhendes Elektrokardiogramm der Person
- Wert 0 - -> normal
- Wert 1 - -> ST-T-Segmentwellenanomalie (abhängig von der Art der Anomalie mit verschiedenen Herzproblemen verbunden)
- Wert 2 - -> Hypertrophie im linken Datatikel (verursacht durch hohen Blutdruck, kann einen Herzinfarkt verursachen)
- beats_minute: Die höchsten von der Person aufgezeichneten Schläge pro Minute
- angina_by_exercise: Wenn Angina durch Bewegung verursacht wurde (1 = ja; 0 = nein)
- s_st: Eine durch körperliche Betätigung verursachte Depression des ST-Segments im Vergleich zu einer Depression des ST-Segments in Ruhe wird untersucht. Je höher dieser Wert ist, desto wahrscheinlicher ist es, dass Sie ein Herzproblem haben..
- anstehende_s_st: die Steigung des ST-Segments am Übungspeak
- Wert 1 - -> Ansteigenden
- Wert 2 - -> Flacher Ohrring
- Wert 3 - -> Negative Steigung
- Es wäre interessant, diese Werte in zu ändern 1, 0 und -1 jeweils ein bisschen ähnlicher zu sein, was sie darstellen.
- n_vasos_sanguineos: Anzahl der Hauptblutgefäße (0-3)
- Standardtyp: Es ist ein Test, der mit einem radioaktiven Element durchgeführt wurde (Thallium) in den Blutkreislauf der Patienten injiziert. Dies ermöglicht die Untersuchung des Blutflusses sowohl in Ruhe als auch während des Trainings:
- Wert 3 - -> Normaler Blutkreislauf.
- Wert 6 - -> In der Umgebung wird weder in Ruhe noch beim Training ein Blutfluss beobachtet. (Fehler behoben)
- Wert 7 - -> Während des Trainings wird in der Umgebung kein Blutfluss beobachtet, sondern in Ruhe. (reversibler Defekt)
- problem_heart: Herz Problem:
- Wert 0 - -> Nein
- Wert 1 - -> Ja
- Wert 2 - -> Ja, am schlimmsten
- Wert 3 - -> Ja, viel schlimmer
- Wert 4 - -> Ja, am schlimmsten möglich
- Es ist zu beachten, dass die Variable problem_heart Es wird als Referenz dienen, um zu wissen, ob wir mögliche Fälle von Herzproblemen anhand der Werte vorhersagen können, die Einzelpersonen in den übrigen Variablen annehmen.. Daher wird diese Variable als Ergänzung verwendet und dient als Referenz..
2. Erste explorative Analyse und Vorverarbeitung von Daten
2.1 Fehlende Daten
Wir prüfen, ob keine Daten fehlen, Dazu wird ein Diagramm fehlender Daten nach Variablen angezeigt
Wie können Sie sehen, dass in keiner Variablen ein leeres Feld vorhanden ist?.
2.2 Variablen und / oder verworfene Datensätze.
Ein bisschen recherchieren, In diesem Datensatz in der Spalte Blutgefäßnummer nehmen einige Beobachtungen den Wert an ?, was falsch ist. (Im Originaldatensatz repräsentieren sie NaNs). Gleiches gilt für die Variable defect_type, wer nimmt Mut ?, es ist schlecht. Deshalb werden wir diese Beobachtungen beseitigen
2.3 Neukodierung von Variablen
Dieser Schritt wird ausgeführt, um aussagekräftigere Kategorien zu erhalten. Auf diese Weise werden Kategorien, die zuvor "1" und "0" waren, zu Mann und Frau beziehungsweise.
2.4 Variable Verteilung
Dieser Schritt wird ausgeführt, um zu beobachten, welche Werte die Variablen annehmen, und um sicherzustellen, dass keine fehlerhaften Werte vorhanden sind.
In dem Nebengebäude 8.2: Die Analyse der variablen Verteilung wird erklärt
Nach dem Studium der Verteilung der Variablen, Wir beobachten, dass keiner von ihnen falsche Werte hat, und deshalb, Wir können mit der Analyse fortfahren.
3. Analyse 1 FAMD(Factominer)
FAMD (Analyse gemischter Datenfaktoren) ist eine Hauptkomponentenmethode zur Untersuchung von Daten mit kontinuierlichen und kategorialen Variablen. Im Großen und Ganzen ist es eine Mischung aus PCA und AFC.
Spezifisch, Kontinuierliche Variablen werden auf Einheitsvarianz skaliert und kategoriale Variablen werden in eine disjunktive Tabelle umgewandelt und dann unter Verwendung von AFC-Kriterien skaliert. Dies macht beide Arten von Variablen repräsentativ für die Analyse.. Das heißt, dass ein Variablentyp nicht mehr beeinflusst als der andere Variablentyp. In diesem Fall, corazón Herzproblem “wird als zusätzliche Variable belassen, so dass wir sehen können, ob die Individuen ohne ihre Anwesenheit in zwei Gruppen unterteilt sind, als ob diese Variable vorhanden wäre. Wenn Sie weitere Informationen zu FAMD erhalten möchten, können Sie dies unter tun http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/115-famd-factor-analysis-of-mixed-data-in-r-essentials/ und auch in https://rdrr.io/cran/FactoMineR/man/FAMD.html
3.1 Tore
- Führen Sie eine Vorverarbeitung der numerischen und kategorialen Daten durch, um die Bewertungsmatrix zu erhalten (mit den wichtigsten X-Hauptkomponenten) um es im Clustering verwenden zu können (Clustering unterstützt keine gemischten Daten)
- Untersuchen Sie die Beziehungen zwischen den Variablen des physischen Zustands einer Person und lassen Sie die Herzproblemvariable als Ergänzung, damit sie die Studie nicht beeinflusst, und prüfen Sie, ob Personen betroffen sind, selbst, Sie sind in zwei Gruppen unterteilt (mit einem Herzproblem ja oder nein).
3.2 Anwendung der Methode sowie numerische und grafische Ergebnisse
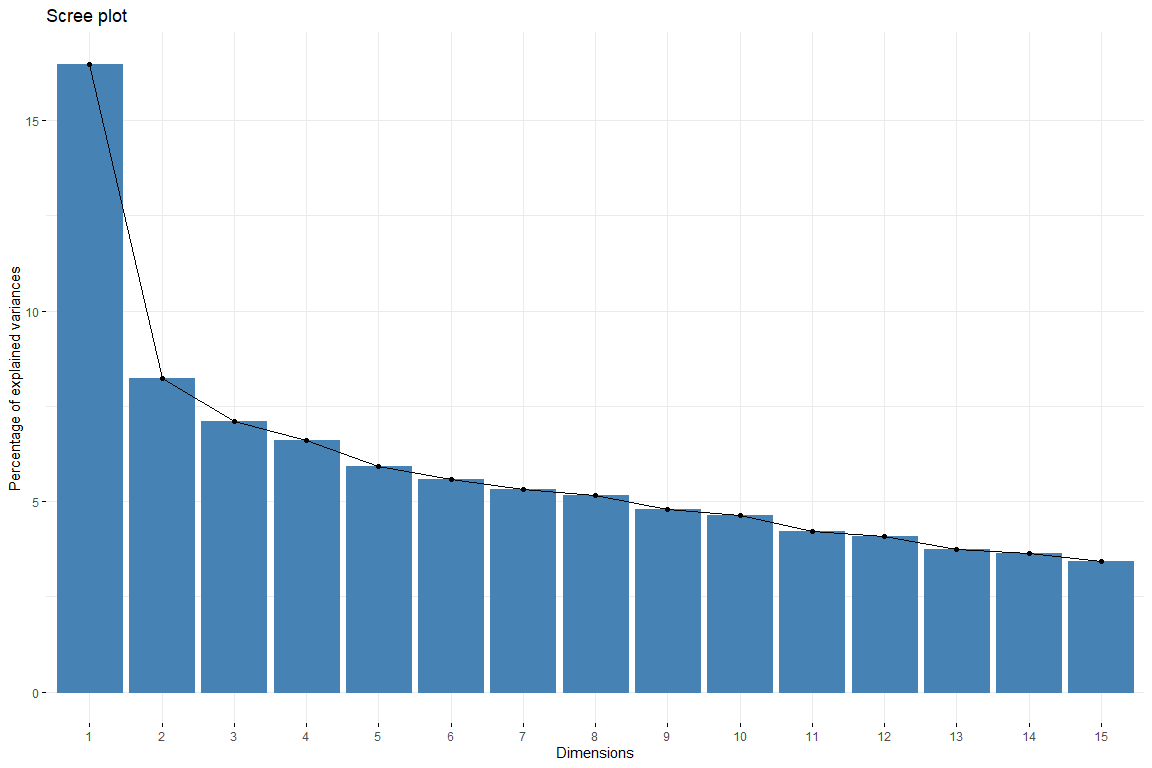
In der Geröllhandlung können wir sehen, wie aus dem 6 Dimension Der Beitrag der Dimensionen nimmt gleichmäßig ab. So, wird gewählt 6 Abmessungen zur Darstellung unserer Daten. Wir fangen auch 6 Dimensionen, da wir auf diese Weise eine Erklärung erhalten 50% der Variabilität. Nun werden wir den Beitrag der Variablen zu den ersten Dimensionen untersuchen.
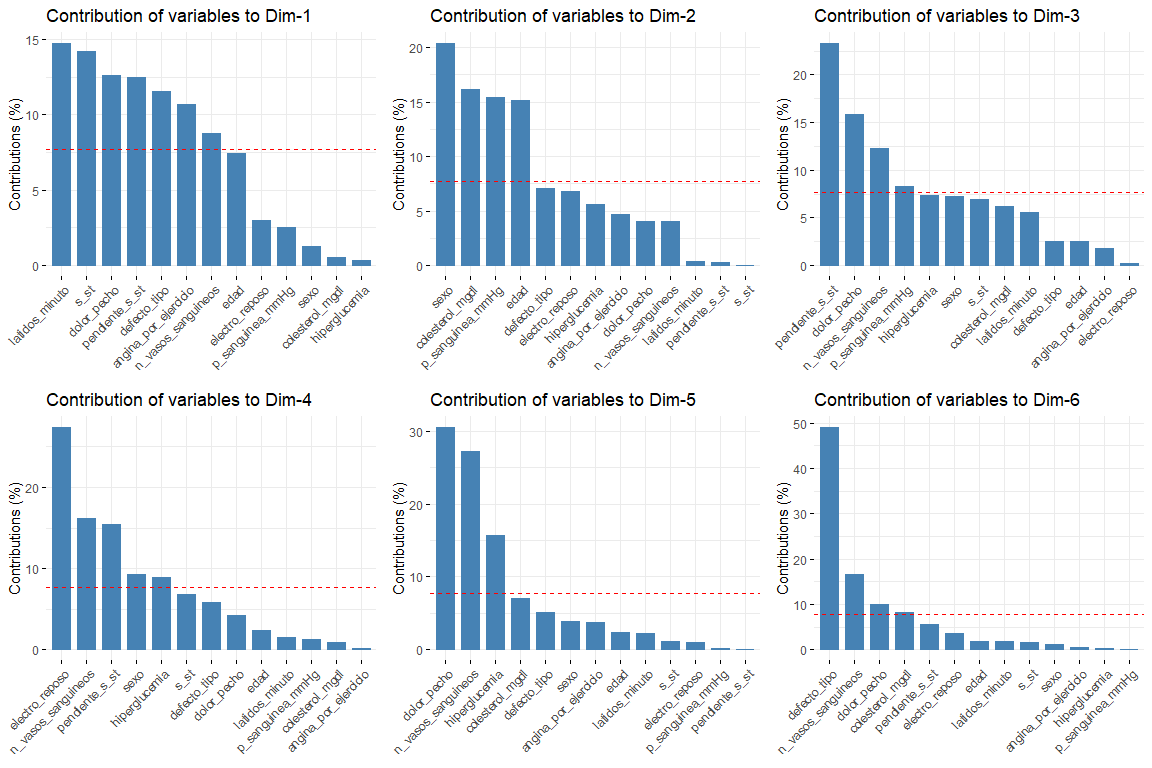
Die interessantesten Ergebnisse der Beiträge sind die der ersten beiden Dimensionen (da sie diejenigen sind, die die größte Variabilität erklären). Es ist zu beachten, dass die erste Dimension durch mehrere Variablen gekennzeichnet ist (logisch, da es diejenige ist, die die größte Variabilität von allen erklärt) Dies sind default_type, pain_chest und st. In der zweiten Dimension, Die Anzahl der Variablen, die diese Dimension charakterisieren, ist geringer als die der ersten Dimension, und das sind Sex, Alter, Cholesterin_mgdl, p_sanguinea_mmHg. Sobald die ersten beiden Dimensionen charakterisiert sind, Wir werden den Graphen der Variablen sehen, die im Vektorraum der ersten beiden Dimensionen gezeichnet sind, um die Beziehungen zwischen Variablen zu beobachten, und seine Charakterisierung in jeder der beiden Dimensionen auf visuellere Weise.
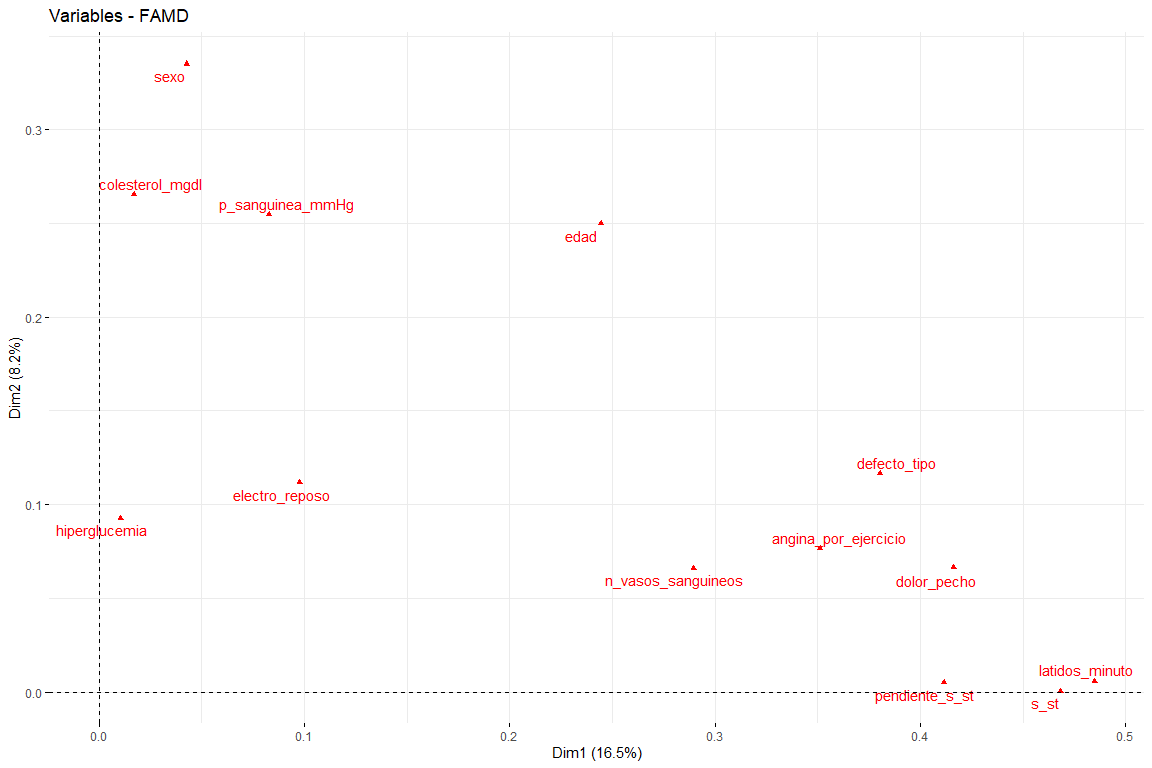
In diesem Diagramm sind die ersten beiden Dimensionen dargestellt (das wichtigste) und wir haben Ergebnisse, die die im Beitragsdiagramm gezeigten bestätigen. Variablen wie latidos_minuto oder s_st tragen am meisten zur ersten Dimension bei, und die Variablen Geschlecht oder Alter tragen wesentlich zur zweiten Dimension bei..
3.3 Diskussion der Ergebnisse
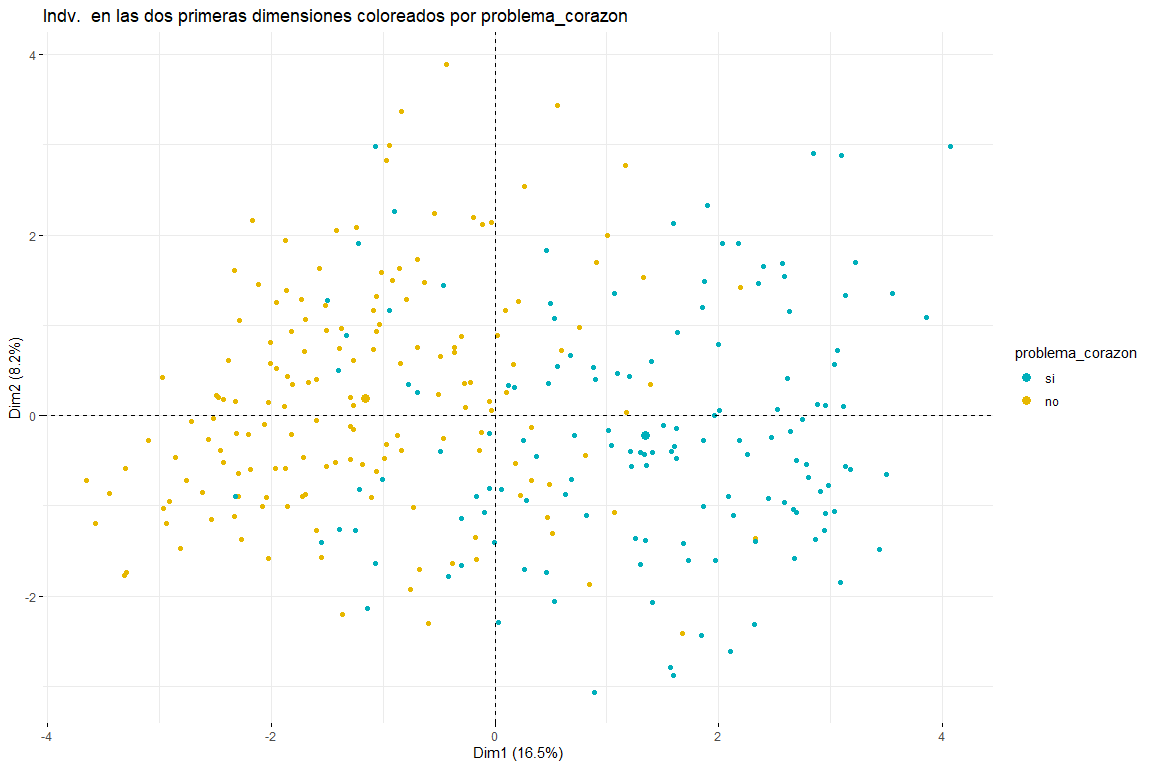
Nachdem wir die Grafik der mit problema_corazon gefärbten Personen gesehen haben, können wir zwischen zwei und drei Gruppen unterscheiden (Hierzu wären nachfolgende Clusteranalysen erforderlich) Beide möglichen Ergebnisse sind sinnvoll, da zwei Gruppen implizieren würden, dass die Werte in bestimmten Variablen (Standardtyp, pain_chest, Sex, Alter, Cholesterin_mgdl, p_sanguinea_mmHg) implizieren die Trennung zwischen Fällen von Herzproblemen und solchen, die dies nicht tun. Drei Cluster könnten auch sinnvoll sein, da wir im Diagramm sehen, wie die Werte problem_heart = yes und problem_heart = no getrennt sind, Wir können aber auch sehen, wie im Zentrum die Werte Herzproblem ja und Herzproblem nein stehen, daher könnte auch das Vorhandensein von drei Clustern möglich sein. Wir können auch bestätigen, dass die Hauptrichtung der Trennung der Gruppen auf die erste Dimension zurückzuführen ist., daher die Variablen defect_type, pain_chest, s_st, Standardtyp, p_sanguinea_mmHg wären diejenigen, die es ermöglichen würden, diejenigen Patienten zu identifizieren, die an einem Herzproblem leiden. Es scheint auch, dass Personen, die Herzprobleme hatten, nicht nur nach rechts, sondern auch nach unten verschoben werden. Dies würde bedeuten, dass Variablen, die am meisten zur zweiten Dimension beitragen (Sex, Alter, Cholesterin_mgdl, p_sanguinea_mmHg) Sie hätten auch damit zu tun, festzustellen, ob ein Patient ein Herzproblem hatte oder nicht. Diese Schlussfolgerungen werden voraussichtlich mit der nachfolgenden Clusteranalyse aus dieser FAMD-Analyse bestätigt..
4. Hierarchisches Clustering
Die HCPC (Hierarchisches Clustering auf Hauptkomponenten) ist ein Algorithmus, der ähnliche Personen in Clustern gruppiert, jedoch mit einer Besonderheit. Es wird gemacht, um mit den Ergebnissen einer Hauptkomponentenmethode zu arbeiten (PCA, MFA, FAMD…). Für mehr Informationen: http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/117-hcpc-hierarchical-clustering-on-principal-components-essentials/
4.1 Zielsetzung
- Beobachten Sie anhand der im FMAD erhaltenen Bewertungsmatrix, ob durch hierarchisches Clustering mit diesen Personen zwei Cluster erhalten werden, die die Personen in Personen mit und ohne Herzprobleme gruppieren.. Falls dies nicht passiert, Untersuchen Sie den Grund für die Existenz der unerwarteten Anzahl von Clustern.
4.2 Anwendung der Methode
Für das Clustering verwenden wir die Koordinaten der Personen in der 6 Dimensionen, die wir in der FAMD genommen haben. Das Ziel der FAMD, wie zuvor besprochen, war es, die Daten vorzuverarbeiten, um anschließend Cluster zu bilden. dennoch, Wir haben nur mit der FAMD ziemlich aufschlussreiche Ergebnisse erzielt, und es wird erwartet, dass diese Ergebnisse mit der Clusteranalyse bestätigt werden..
Zur Berechnung der Score-Matrix, die später beim Clustering verwendet wird, Es werden alle Variablen verwendet, die den physischen Zustand der Person angeben. Es wird betont, dass im hierarchischen Clustering die Variable problem_heart NICHT enthalten ist, damit sie bei der Berechnung der Cluster keine Auswirkung hat. Da das Ziel darin besteht, Cluster durch die Variablen des physikalischen Zustands zu berechnen, um zu sehen, ob es mit dem Herzproblem zusammenhängt.
4.2.1 Wir berechnen die Entfernungen und die Hopkins-Statistik
Bevor Sie einen Clustering-Algorithmus anwenden, müssen Sie sich fragen, ob es eine Gruppierung dafür gibt, Wir führen die Hopkins-Statistik durch, die angibt, ob die Daten eine Gruppierung enthalten. Wir müssen uns daran erinnern, dass die Bibliothek 'clustertend' 1-H zurückgibt, wobei H die Hopkins-Statistik ist.
$H.
## [1] 0.2628502
Bei Herzdaten hat der Statistiker einen Wert von 0.26 sehr weit von 1, so, Wir können bestätigen, dass unsere Daten gruppiert sind.
4.2.2 Optimale Anzahl von Clustern
Um den Hierarchical Clustering-Algorithmus ausführen zu können, Wir müssen die optimale Anzahl von Clustern kennen. Dazu führen wir folgende Tests durch.
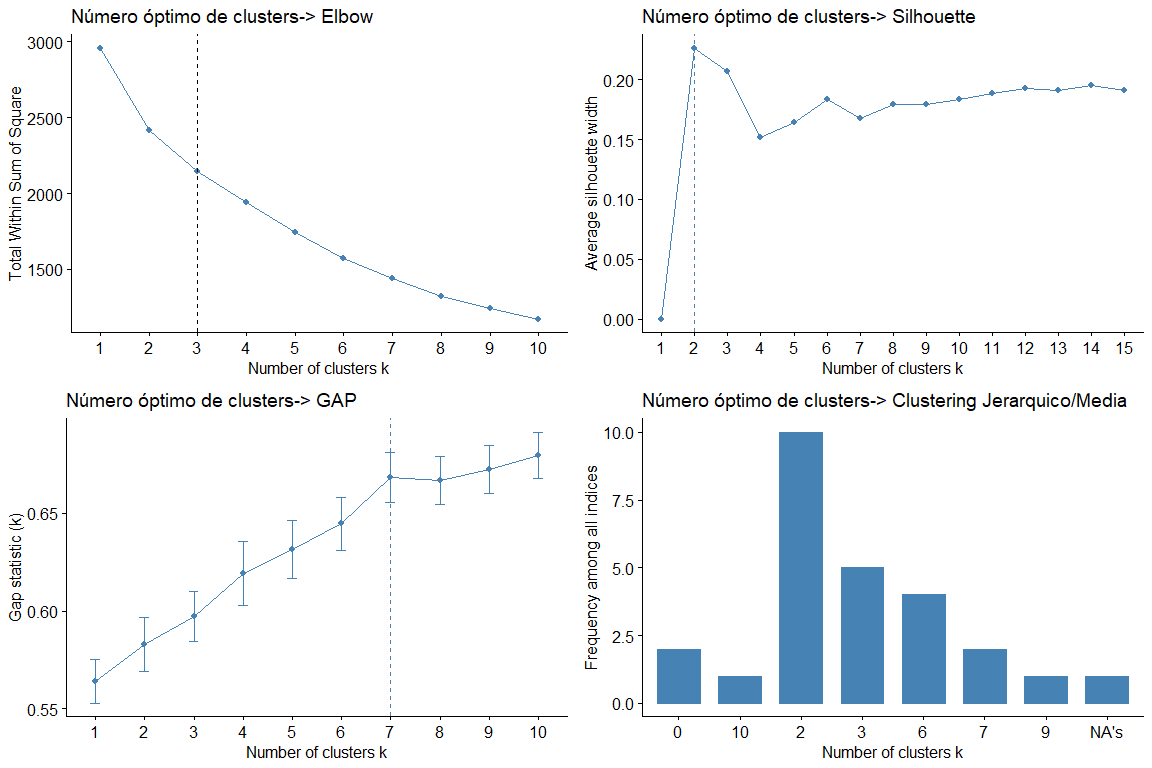
Wenn wir uns die Grafiken und Tabellen ansehen, können wir sehen, dass wir für die verschiedenen Statistiken und Methoden unterschiedliche Werte von Clustern erhalten. Das häufigste Ergebnis ist zu berücksichtigen 2 Cluster, gefolgt von 3 Cluster. (das Ergebnis 7 es erscheint auch wiederholt, aber da es keinen Sinn machen würde, darüber nachzudenken 7 Gruppen verwerfen wir diese Schlussfolgerung)
Dann, Wir machen ein Cluster-Diagramm von 2 und 3 Cluster jeweils, um zu sehen, welche am besten zu unseren Daten passt. Wir verwenden, um die kmeans-Daten zu erhalten, da wir bei der Analyse der Daten feststellen können, dass die Daten keine sehr extremen Werte haben und daher, Keine Notwendigkeit für robustere Methoden wie PAM, beispielsweise.
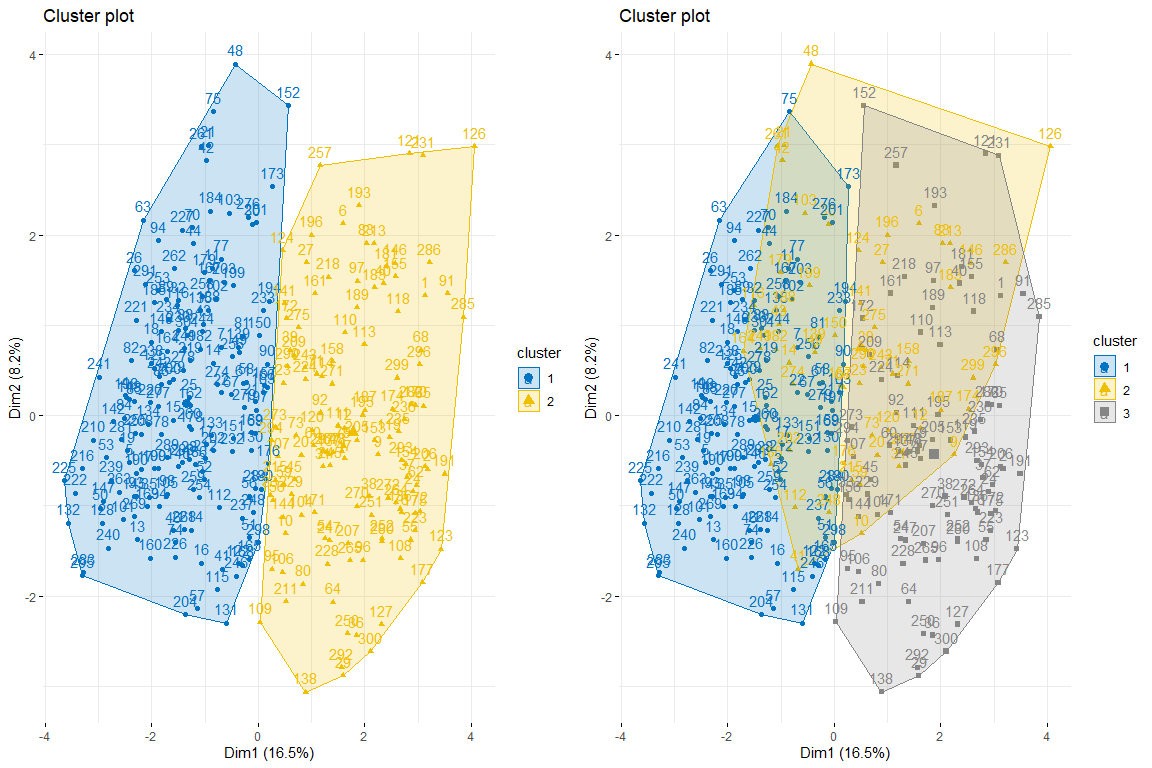
Wie wir beobachten können 2 Cluster scheinen die beste Option zu sein, da sie erstellt werden 2 ziemlich natürliche Gruppen, das heißt, Personen mit Herzproblemen und Personen ohne Herzprobleme.
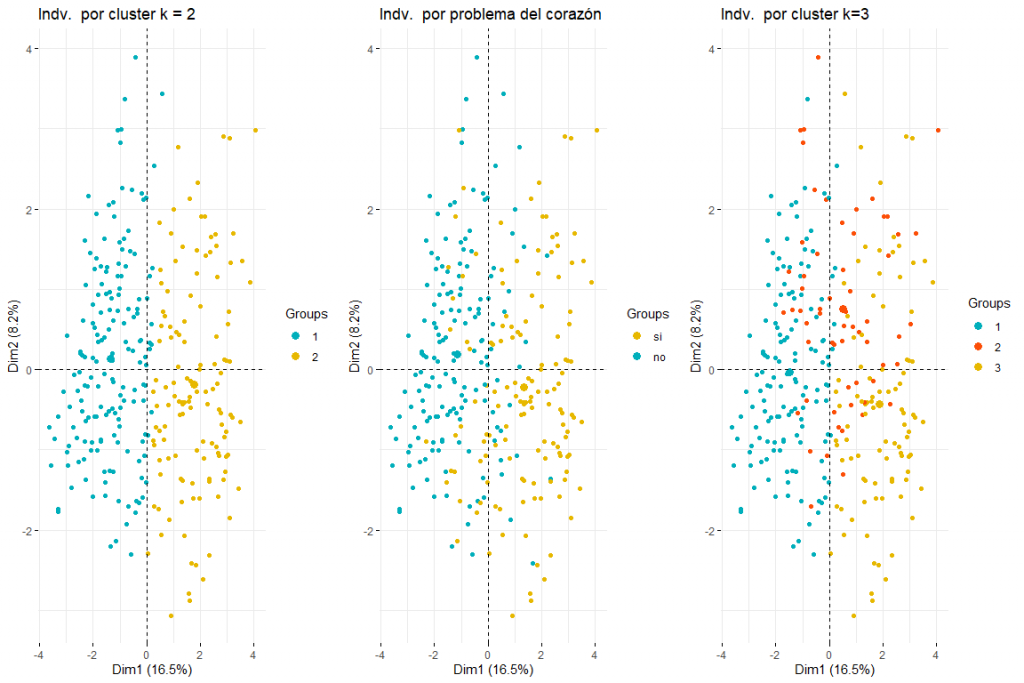
Wir werden mit dem Vergleich zwischen zwei und drei Clustern fortfahren, die die Individuen des FAMD-Individuenplots färben..
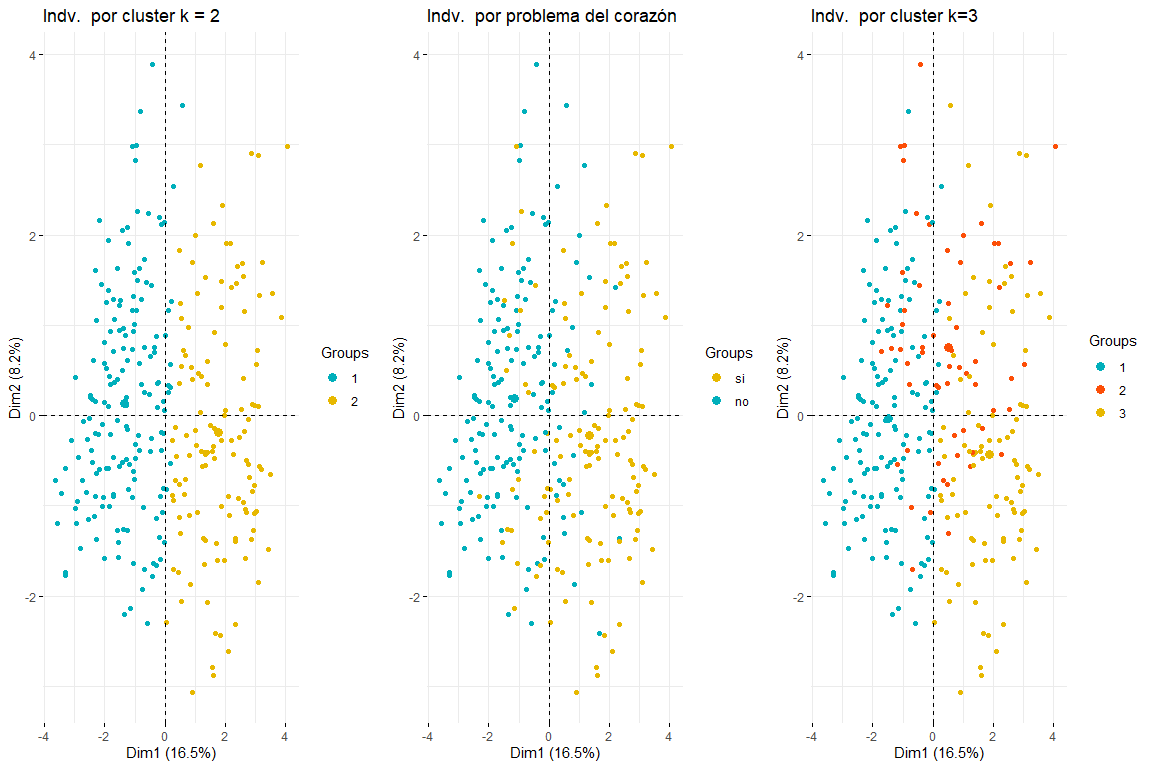
Wie aus den drei Diagrammen der Individuen hervorgeht, die nach Cluster- und Herzproblemen gefärbt sind, Es wird geschätzt, dass zwei Cluster derjenige sind, der sich am besten anpasst, und sieht eher aus wie die Tabelle der Personen, die durch Herzprobleme gefärbt sind. Nach dem Vergleich dieser drei Gruppen von Graphen können wir schließen, dass die Verwendung von zwei Clustern eher der Verteilung der Daten gemäß problem_heart entspricht. Für all das, Für die hierarchische Clusterbildung werden zwei Cluster ausgewählt.
4.3 Numerische und grafische Ergebnisse
Schließlich die Beziehung zwischen den Variablen und den beiden Clustern und, So, ihre Beziehung dazu, ob sie ein Herzproblem haben oder nicht. Wir beginnen mit der Beziehung zwischen den Kategorien qualitativer Variablen und der Zugehörigkeit zu dem einen oder anderen Cluster. Es ist offensichtlich, dass die Kategorien, die am meisten mit einem Cluster zusammenhängen, diejenigen mit einem höheren v.test sind, Während diejenigen, deren Wert von v.test sehr negativ ist, weniger mit dem Cluster verwandt sind (und da wir nur zwei Cluster haben, werden diese Kategorien mit einem sehr negativen v.test wahrscheinlich mit dem anderen Cluster verwandt sein.).
res.hcpc2$desc.var$Kategorie
## $`1`
## p.Wert v.test
## Steigung_s_st = positiv 2.930295e-25 10.384064
## angina_por_exercise = angina_no_exercise 1.061236e-23 10.035774
## default_type = normal 2.733441e-22 9.709997
## n_vasos_sanguineos = 0 4.846452e-13 7.229537
## pain_chest = angina_atipica 4.782592e-11 6.577551
## pain_chest = pain_no_angina 1.569061e-07 5.244266
## Geschlecht = Frau 4.235184e-05 4.094260
## elektro_repost = normal 4.769950e-03 2.822173
## $`2`
## Cla / Mod Mod / Cla Global
## p.Wert v.test
## angina_por_exercise = angina_exercise 1.061236e-23 10.035774
## pendiente_s_st = plana 5.739929e-20 9.149120
## pain_chest = asymptomatisch 8.164639e-19 8.857749
## defect_type = defect_reversible 2.547142e-15 7.911300
## Geschlecht = Mann 4.235184e-05 4.094260
## n_vasos_sanguineos = 2 4.952918e-05 4.057838
## n_vasos_sanguineos = 3 9.157912e-05 3.911883
## default_type = fixed_defect 1.073890e-04 3.873260
## n_vasos_sanguineos = 1 4.649990e-03 2.830331
## elektro_reposto = hypertrophy_izq 2.225498e-02 2.285988
## elektro_repost = abnormalität_st 3.297443e-02 2.132394
## Steigung_s_st = negativ 4.472770e-02 2.007206
Nun werden wir die Beziehung zwischen den quantitativen Variablen und den beiden Clustern sehen. Die repräsentativsten Variablen sind diejenigen mit dem höchsten v.test (im absoluten Wert) Wenn wir uns den Unterschied zwischen "Mittelwert in Kategorie" und "Gesamtmittelwert" ansehen, können wir eine Vorstellung davon bekommen, welche Werte Einzelpersonen in einem Cluster für diese Variablen annehmen.
## $`1`
## v.test Mittelwert in der Kategorie Gesamtmittelwert sd in der Kategorie
## beats_minute 10.133353 161.3313609 149.597973 16.6608075
## p_sanguinea_mmHg -3.346967 128.6508876 131.648649 16.2372212
## Alter -6.575012 51.5147929 54.513514 8.9085469
## s_st -9.798909 0.4757396 1.051351 0.6908983
##
## $`2`
## v.test Mittelwert in der Kategorie Gesamtmittelwert sd in der Kategorie
## s_st 9.798909 1.817323 1.051351 1.222434
## Alter 6.575012 58.503937 54.513514 7.537699
## p_sanguinea_mmHg 3.346967 135.637795 131.648649 18.848618
## beats_minute -10.133353 133.984252 149.597973 20.744028
Damit, Sie können sehen, dass die Personen, aus denen der erste Cluster besteht, durch hohe Werte in beats_minute definiert werden (in Bezug auf den Mittelwert), niedriges Alter, p_sanguinea y s_st. Wir können auch sehen, wie die Personen im Cluster 1, das heißt, jene Fälle, die kein Herzproblem erlitten haben, sie sind Frauen, deren Brustschmerzen keine atypische Angina oder Angina sind und nicht durch körperliche Betätigung verursacht werden. Ebenfalls, Ihr Elektro in Ruhe ist normal, sein Wert nach dem Test mit Thalium ist normal und sein n_vasos_sanguíneos ist 0.
Andererseits, Die Individuen im zweiten Cluster sind überwiegend männlich, deren Blutdruck über dem Durchschnitt liegt, deren Schläge pro Minute kleiner als der Durchschnitt sind und deren s_st größer als der Durchschnitt ist. Sie zeichnen sich auch durch eine flache Steigung aus, einige Werte von 1, 2 Das 3 in n_vasos_sanguíneos, deren Angina durch körperliche Betätigung verursacht wird, Sein Schmerz ist asymptomatisch und sein Wert nach dem Thalium-Test ist reversibel oder fest. Schließlich sind seine Ruheelektrowerte Hypertrophie oder Abnormalität_st.
4.4 Diskussion der Ergebnisse
Wie Sie sehen können, die Variablen, die die Cluster am meisten charakterisieren, und folglich, auch wenn eine Person ein Herzproblem hat oder nicht, sind jene Variablen, die den größten Beitrag zur ersten und zweiten Dimension der FAMD geleistet haben. Ebenfalls, wir können sehen, dass die Schlussfolgerungen, die erhalten wurden, sinnvoll sind; diejenigen, die ein Herzproblem erlitten haben (Zugehörigkeit zum Cluster 2) haben eine sehr niedrige maximale Herzfrequenz pro Minute, ein fortgeschrittenes Alter, sie sind Jungs, höher als normaler Blutdruck, ein asymptomatischer Brustschmerz ... all dies sind Risikofaktoren für Herz-Kreislauf-Probleme.
5. Analyse 3: PLS-DA
Die Regression der partiellen kleinsten Quadrate oder der partiellen Regression der kleinsten Quadrate (PLS-Regression) Es ist eine statistische Methode, die sich auf die Regression von Hauptkomponenten bezieht, anstatt Hyperebenen mit maximaler Varianz zwischen der Antwortvariablen und den unabhängigen Variablen zu finden, Eine lineare Regression wird gefunden, indem die Vorhersagevariablen und die beobachtbaren Variablen in einen neuen Raum projiziert werden. Weil sowohl die X- als auch die Y-Daten in neue Räume projiziert werden, Die PLS-Modellfamilie ist als bilinearer Modellfaktor bekannt. In unserem Fall, Wir werden eine partielle Diskriminanzanalyse der kleinsten Quadrate verwenden (PLS-DA) Dies ist eine Variante, die verwendet wird, wenn das Y binär ist.
5.1 Tore
Bei der Durchführung des PLS-DA gibt es zwei Ziele:
Der erste besteht darin, die in der FAMD erhaltenen Ergebnisse anhand der Scores und Ladungsdiagramme zu vergleichen und zu prüfen, ob dasselbe Ergebnis interpretiert werden kann. Auch durch das Diagramm der Beobachtungsdiagnose können wir das Vorhandensein oder Nichtvorhandensein extremer Daten beobachten.
Das zweite Ziel besteht darin, die Vorhersagekapazität des PLS-DA-Modells anhand der Daten zu bewerten, die in Trainingsdaten und Testdaten getrennt werden. Dies wird dazu dienen, zu sehen, ob es möglich ist, neue Fälle von Herzproblemen mit den verfügbaren Variablen vorherzusagen..
5.2 Anwendung der Methode
Für die Anwendung der Methode wurde ein anderer Vorprozess der „unabhängigen“ Variablen verwendet, die unsere Matrix X bilden, da für die opls-Funktion alle Spalten der Matrix X vom Typ "numerisch" sein müssen (Code im Anhang verfügbar)
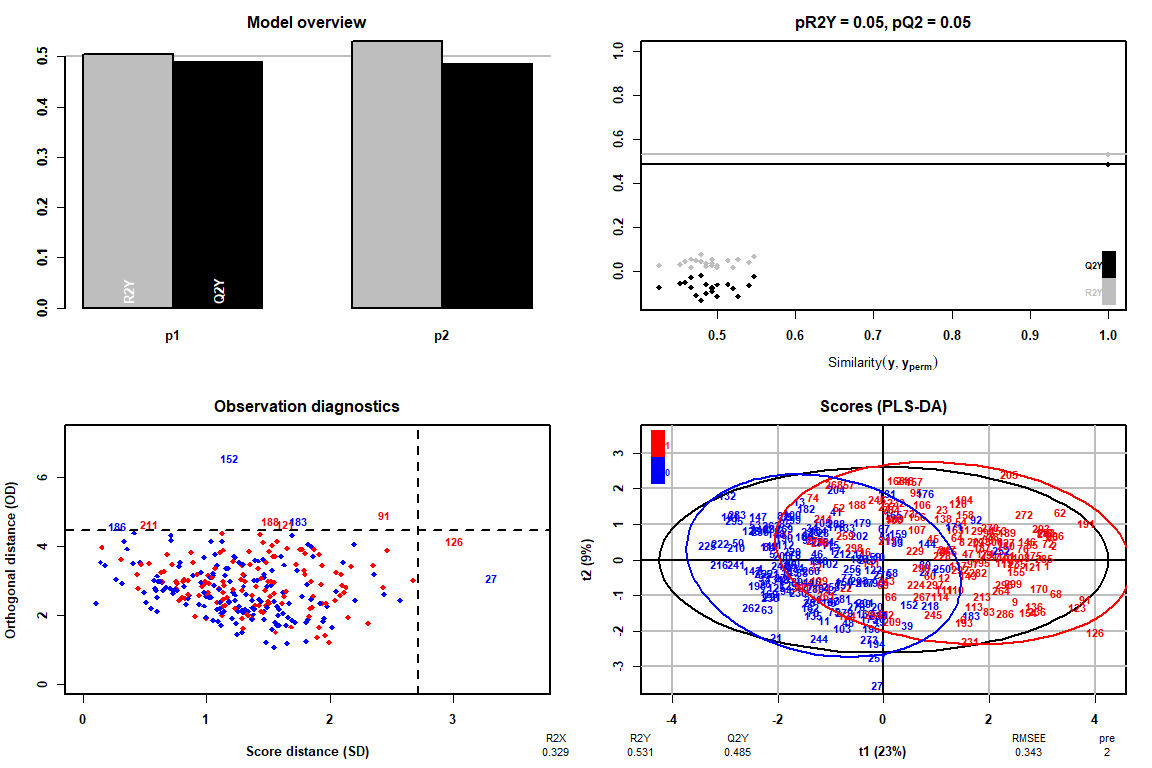
Wie es dank der Beobachtungsdiagnosetabelle beobachtet werden kann, Es gibt keine Extremwerte, Daher können wir die Analyse des PLS-DA fortsetzen, ohne einen Wert löschen zu müssen.
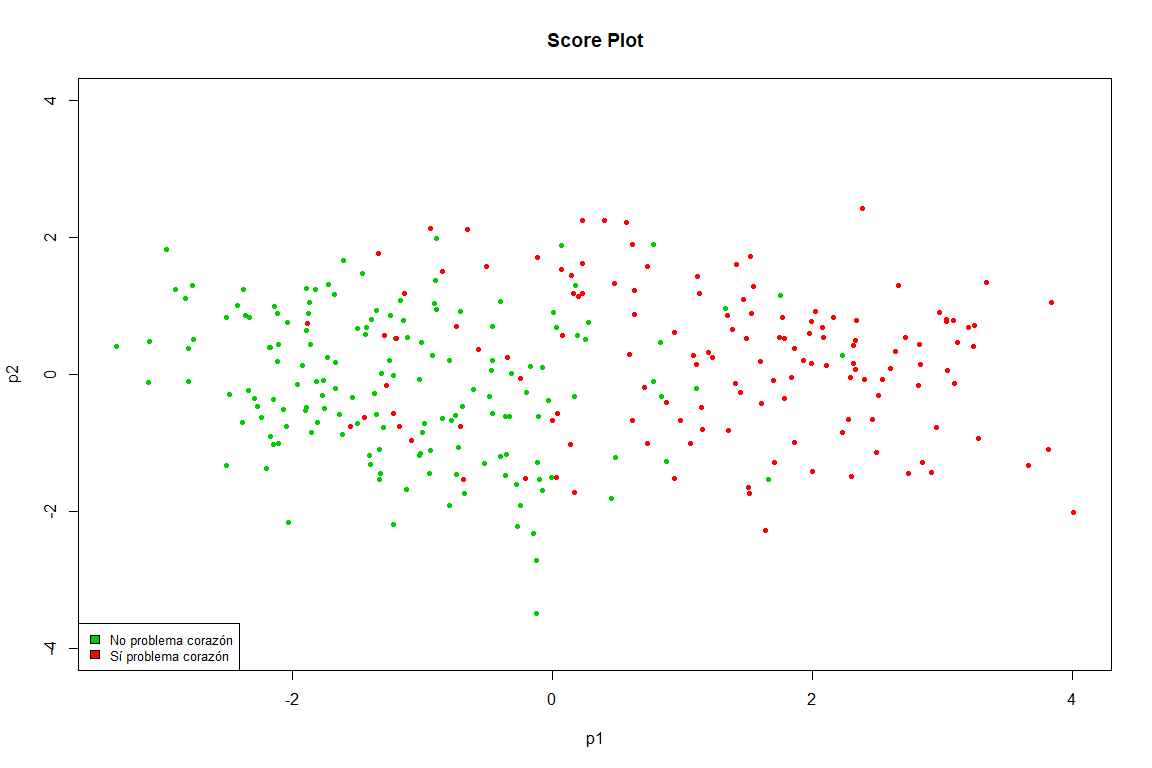
Diese Grafik ist praktisch eine Kopie der in der FAMD erhaltenen, wir sehen, wie klar die Punkte in zwei Gruppen getrennt sind (Herzproblem und nicht Herzproblem)
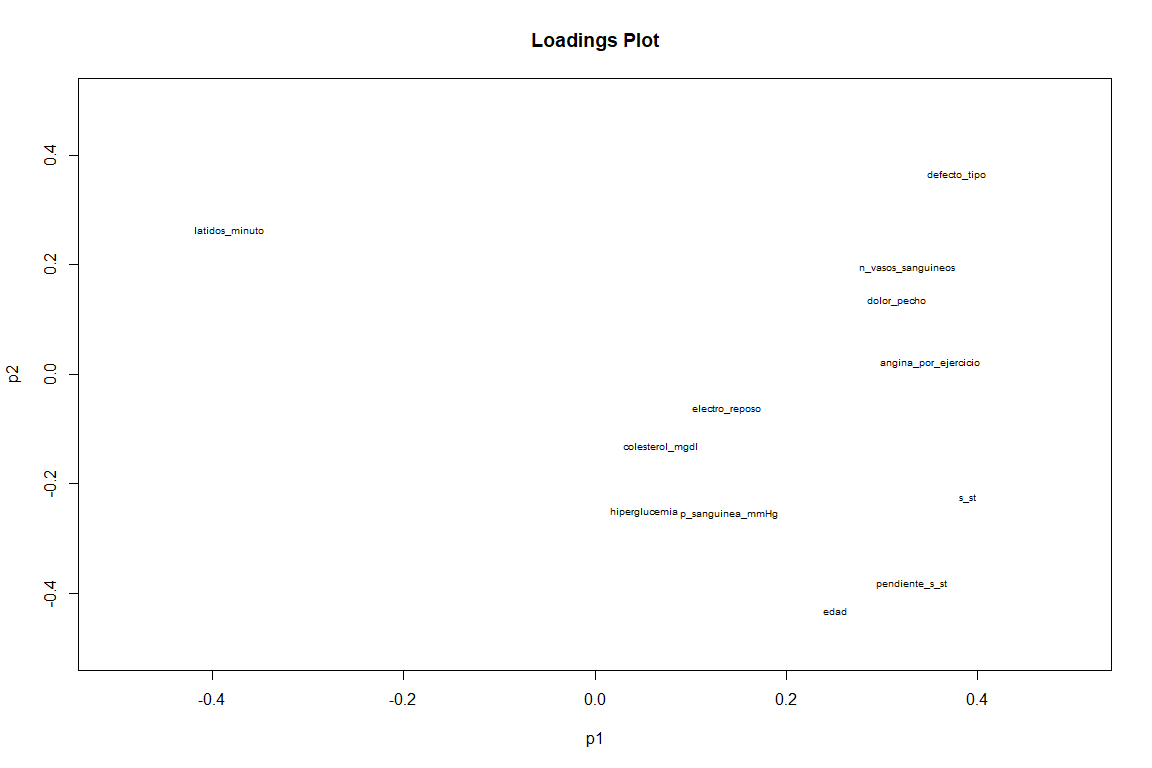
Auf dem Ladediagramm, wenn wir ein etwas anderes Ergebnis als das FAMD-Ladungsdiagramm sehen. Wir sehen als Variablen hang_s_st, default_type und minute_beats (obwohl dies mit negativem Wert ) haben einen großen Beitrag zu den beiden Komponenten. Während Variablen wie angina_por_exercicio und pain_chest vor allem zur ersten Komponente beitragen.
Nun wenden wir uns der Analyse der Vorhersagekapazität des pls-da anhand von Trainingsdaten und Testdaten zu.
mypred = vorhersagen(myplsda)
confuTrain = Tabelle(trainData$problem_heart, mypred)
Verwirrung Matrix(confuTrain)
## Verwirrungsmatrix und Statistik
## mypred Richtigkeit : 0.8487
## 0 1 Kappa : 0.6946
## 0 113 15
## 1 21 89 Ausgewogene Genauigkeit : 0.8495
Wie können wir sehen, dass das Modell seine eigenen Zeilen vorhersagt?, Es hat eine Genauigkeit von 0.85, Sehr guter Wert, der von einem Kappa unterstützt wird 0.7, was auf eine gute Übereinstimmung unserer Daten hinweist. (https://es.wikipedia.org/wiki/Coeficiente_kappa_de_Cohen)
Als nächstes müssen Sie versuchen, Daten vorherzusagen, die der PLS-DA noch nie "gesehen" hat.
mypred = vorhersagen(myplsda, Testdaten[,–14])
confuTest = Tabelle(Testdaten$problem_heart, mypred)
Verwirrung Matrix(KonfuTest)
## Verwirrungsmatrix und Statistik
## mypred Richtigkeit : 0.8448
## 0 1
## 0 28 3 Kappa : 0.6859
## 1 6 21 Ausgewogene Genauigkeit : 0.8493
Das Modell hat ähnliche Werte (Genauigkeit y Kappa) für Daten, die Sie noch nie gesehen haben, womit geschlossen werden kann, dass dieses Modell, sagt ziemlich gut voraus, ob ein neuer Fall ein Herzproblem haben wird oder nicht, mit einer Wahrscheinlichkeit von ungefähr 84% (Richtigkeit 0.84)
5.4 Diskussion der Ergebnisse
Sie können sehen, dass PLS-DA eine sehr gute Methode ist, um neue Fälle von Herzproblemen bei Patienten vorherzusagen, jedoch, Es sei darauf hingewiesen, dass die Studie aus einigen bestand 300 Patienten ungefähr, so müsste die Anzahl der Personen erhöht werden, um zu sehen, ob dieses PLS-DA-Modell wirklich mit solcher Sicherheit vorhersagt (84%) ob ein Patient ein Herzproblem hat oder nicht. Andererseits, Sowohl die Bewertungsmatrix als auch die Ladungsmatrix wurden in zwei Komponenten untersucht. (das bedeutendste) und die Unterschiede zu den FAMD-Ergebnissen wurden untersucht.
6. Schlussfolgerungen
6.1 Vergleichsmethoden verwendet
In dieser Arbeit, Es wurden drei Methoden angewendet: FAMD, Hierarchisches Clustering und PLS-DA.
Sowohl die FAMD als auch die Clusterbildung haben praktisch die gleichen Ergebnisse erzielt (Informationen finden Sie im Abschnitt Schlussfolgerungen der jeweiligen Methode) Dies ist sinnvoll, da die Koordinaten der Personen in den ersten sechs Hauptkomponenten zur Durchführung der hierarchischen Clusterbildung verwendet wurden, Daher hat uns die FAMD als Datenvorverarbeitung gedient (zum Clustering) und auch als erste Analyse der Beziehungen zwischen Variablen und Personen in unserer Datenbank. Beim Clustering haben wir die ersten Beobachtungen bestätigt, die wir über die Existenz von zwei Gruppen und die Variablen gemacht haben, die sie beeinflussen.. Der PLS-DA, Es wurde jedoch auch verwendet, um die Ergebnisse mit denen des FAMD zu vergleichen, da möglicherweise Ähnlichkeiten zwischen den Scores- und Loadings-Diagrammen bestehen., Es wurde hauptsächlich verwendet, um die Vorhersagekapazität des Modells mit unseren Daten zu bewerten.. So entdecken Sie die große Vorhersagekapazität des Modells mit einer Genauigkeit von 85% in Daten, die ich noch nie gesehen habe (Testdaten).
6.2 Diskussion über nicht angewandte Methoden
Die Methoden, die in dieser Arbeit nicht verwendet wurden, sind: Assoziationsregeln, Diskriminanzanalyse.
Zuerst, Zuordnungsregeln werden nicht verwendet, da wir der Ansicht sind, dass sie nicht in unsere Datenbank passen (Unsere Variablen sind nicht qualitativ und die Tatsache, dass alle Variablen transformiert wurden, hätte einen erheblichen Informationsverlust bedeutet). Stattdessen, Clustering und die Möglichkeit, die Cluster, in die unsere Datenbank unterteilt war, tatsächlich sehen zu können, schienen uns eine viel interessantere Option zu sein.
In Bezug auf die Diskriminanzanalyse, Es ist wahr, dass es eine sehr interessante Option gewesen wäre, da genau unsere Absicht vom ersten Moment an ist, die Variablen zu sehen, die am meisten mit der Tatsache zusammenhängen, ob ein Herzproblem vorliegt oder nicht., um dann zukünftige Fälle vorherzusagen oder die Personen zu klassifizieren, die wir bereits hatten. jedoch, Die Verwendung von PLS oder PLS-DA war obligatorisch, und die FAMD- und Clustering-Analysen wurden bereits durchgeführt, die in diesem Fall als relevanter angesehen werden als die Diskriminanzanalyse, deshalb wurde beschlossen, darauf zu verzichten.
Bis zum letzten, Die Wahl zwischen PLS und PLS-DA liegt auf der Hand, da immer die Beziehung zwischen Herzproblemen und den anderen Variablen untersucht werden sollte. Daher ist die beste Option in diesem Fall die Wahl von PLS-DA, Verwenden Sie als Y das Herzproblem und als X den Rest der Variablen, um die Beziehung zwischen ihnen und der Fähigkeit zur Vorhersage zu untersuchen.
7 Andere Themen
7.1 Kommentare zu gelesenen Artikeln
Die Idee, sowohl FAMD als auch hierarchisches Clustering zu entfernen (sowie die Verwendung der Score-Matrix für hierarchisches Clustering) ha chirurgido del libro ‘Praktischer Leitfaden für Hauptkomponentenmethoden in R. (Kassambara)’Y del libro’ Explorative multivariate Analyse am Beispiel mit R. (Chapman & Hall / CRC Informatik & Datenanalyse)Von Francois Husson. Wir glauben, dass es ein sehr leistungsfähiges Werkzeug ist, um beide Techniken zu kombinieren (FAMD und Clustering) seit zuerst, ermöglicht es uns, Rauschen aus unseren Daten zu entfernen, und zweitens, Wenn wir FAMD als vorverarbeitet verwenden, können wir beim Clustering „gemischte Daten“ verwenden, Das bringt uns einen großen Vorteil.
8. Annektieren:
8.1 Blibliographie
- HCPC I.
- FAMD I.
- Ausstehende ST-Segmentinformationen
- „Praktischer Leitfaden zu Hauptkomponentenmethoden in R. (Kassambara)’
- „Explorative multivariate Analyse am Beispiel mit R. (Chapman & Hall / CRC Informatik & Datenanalyse)Von Francois Husson
- FactoMineR-Dokumentation
- Veränderungen des Herzens und der Blutgefäße durch Alterung
- Maximale Schläge pro Minute
- Risikofaktoren für Herz-Kreislauf-Probleme
- Verwendete Daten
8.2 Analyse der variablen Verteilung
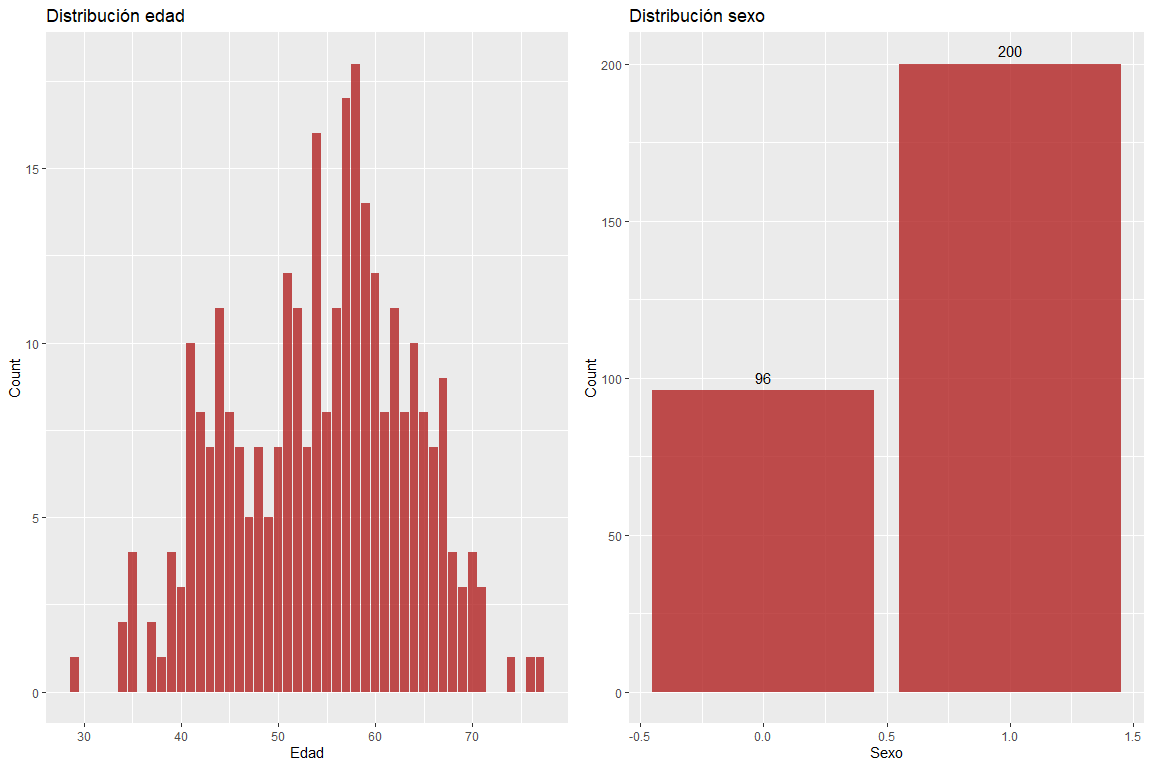
Die Altersvariable nimmt keine Extremwerte an und die Geschlechtsvariable enthält keine fehlerhaften Werte.
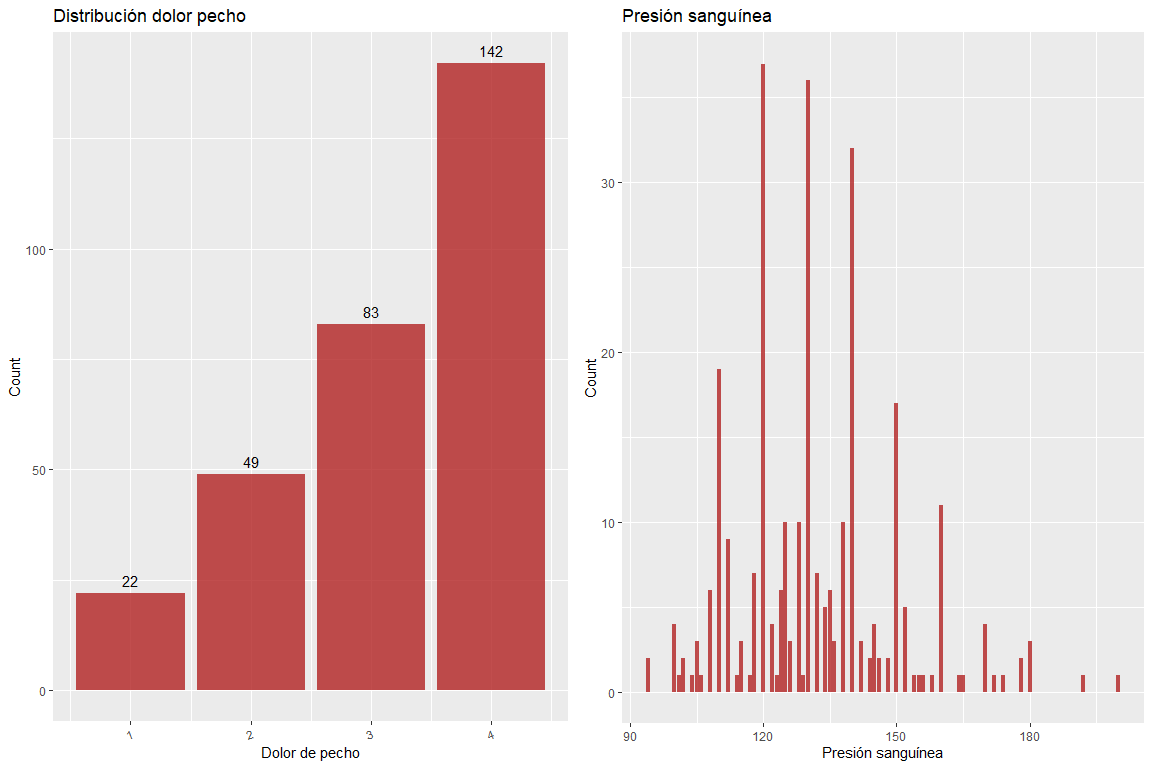
Variable Brustschmerzen enthalten keine falschen Werte, genauso wie der variable Blutdruck auch nicht.
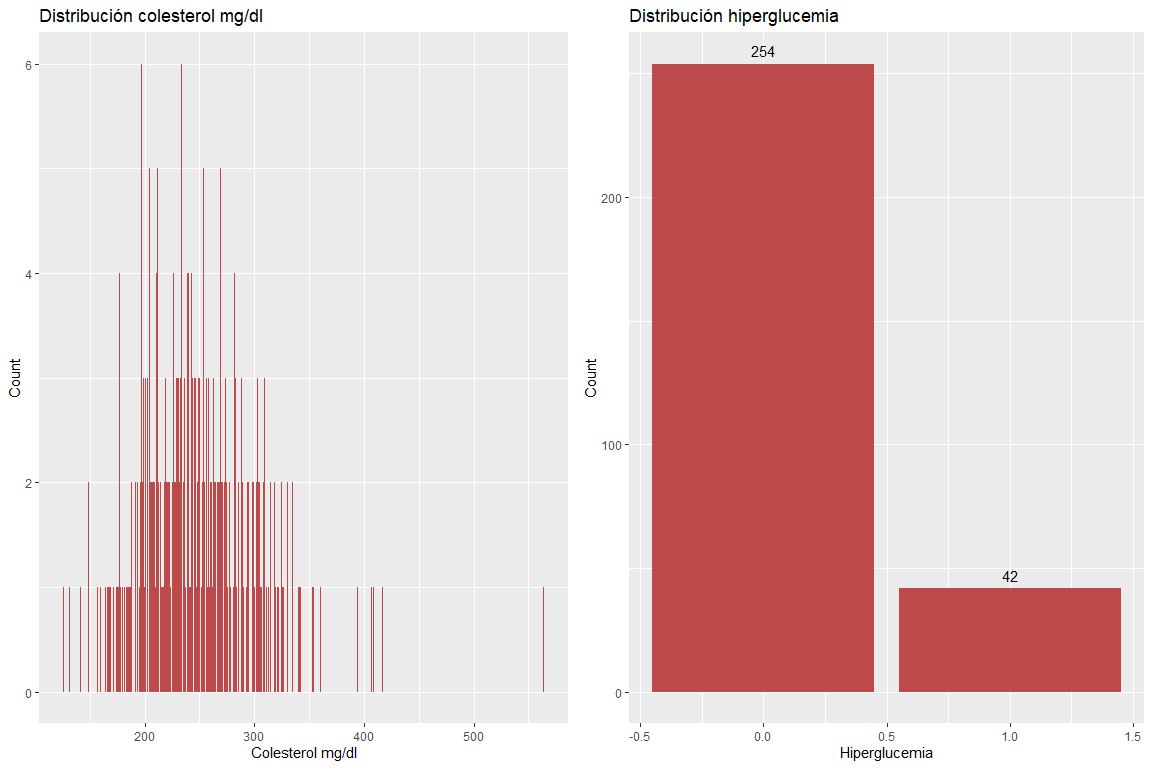
Die beiden Variablen Cholesterin mg / dl und Hyperglykämie nehmen keine falschen Werte an.
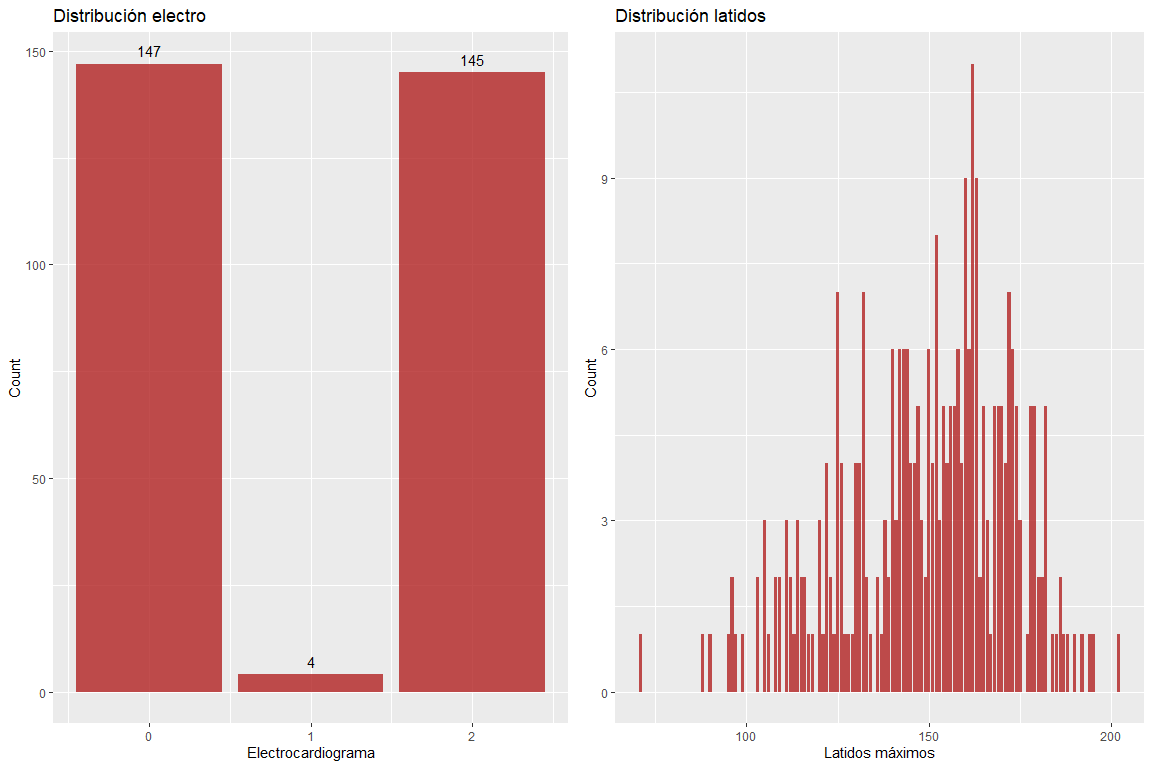
Die beiden Variablenergebnisse des Elektrokardiogramms und die maximalen Schläge pro Minute nehmen keine falschen Werte an.. Es muss jedoch betont werden, dass es für das Alter der Patienten etwas hohe Werte gibt. (nach Haskells Formel & Fuchs, Die Verwendung wird häufig verwendet, um die maximalen Pulsationen je nach Alter abzugrenzen).
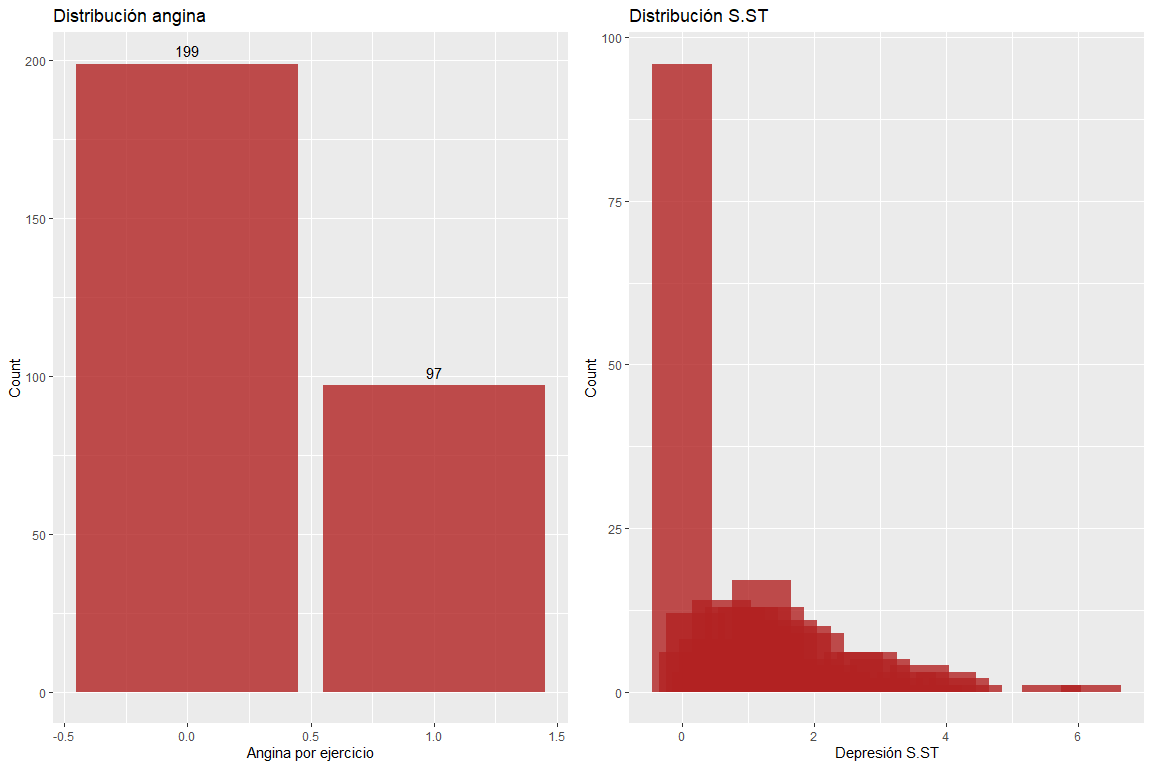
Die beiden Variablen Angina und Depression des ST-Segments haben keine fehlerhaften Werte.. Es muss jedoch betont werden, dass es Beobachtungen mit einem sehr hohen ST-Segment-Depressionswert gibt.
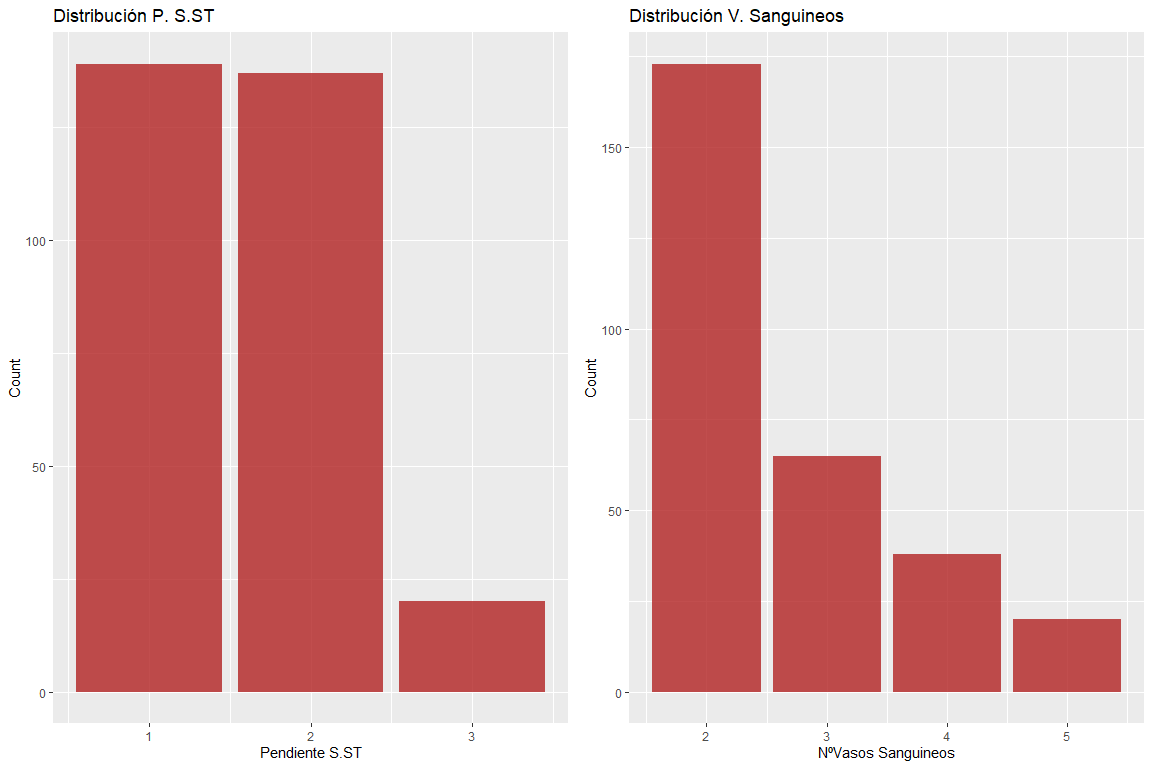
Die beiden Variablen bis zum ST-Segment und die Anzahl der Blutgefäße haben keine fehlerhaften Werte.
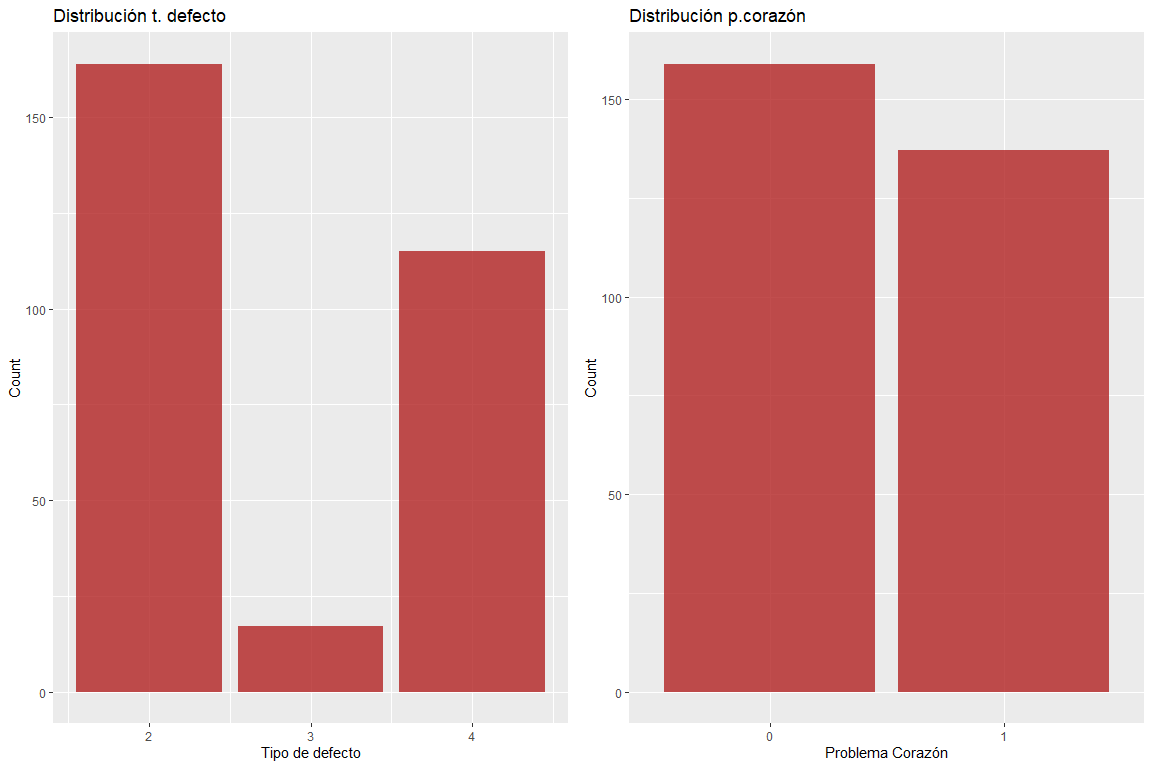
Die beiden Variablentypen Defekt und Herzproblem haben keine fehlerhaften Werte.